(3) Netzwerke II: Internettechnik
1. Protokolle und Dienste
Die Kommunikation in Computernetzen basiert auf internationalen Protokollen, wobei man zwischen herstellerabhängigen (wie SMB) und herstellerunabhängigen, offenen Standards (wie OSI und TCP/IP) unterscheidet. Während das OSI-Modell als theoretisch perfekter Standard durch Gremien entwickelt wurde und oft an Komplexität scheiterte, setzte sich die TCP/IP-Protokollfamilie durch einen pragmatischen, praxisorientierten Entwicklungsansatz als dominierender Standard durch.
1.1. Geschichte
Als Reaktion auf den Sputnikschock 1957 initiierten die USA unter der Forschungsbehörde ARPA die Entwicklung einer robusten, paketorientierten Kommunikationsmethode für Computer, aus der das ARPANET hervorging. Obwohl oft ein militärisches Motiv (Ausfallsicherheit bei Atomangriffen) vermutet wurde, stand die zuverlässige Vernetzung von Forschungseinrichtungen und dem Verteidigungsministerium im Vordergrund.
Da das Projekt nicht als geheim eingestuft war, wurden die Protokolle offengelegt und direkt in das an Universitäten verbreitete Betriebssystem UNIX integriert. Diese freie Verfügbarkeit etablierte die Technologie als Quasi-Standard im akademischen Bereich und bildete das Fundament, aus dem sich ab Mitte der 80er-Jahre das moderne Internet entwickelte.
1.2. Protokolle und Gremien
Die Basis des Internets bildet die herstellerneutrale TCP/IP-Protokollfamilie. Ihre Standards und Protokolle werden in sogenannten RFCs (Request for Comments) festgehalten. Historisch basierte dies auf einem offenen Prozess, bei dem Vorschläge von der Community diskutiert, verbessert und bei Bewährung in der Praxis als Standard übernommen wurden.
Die technische Leitung für das nordamerikanische Internet obliegt dem IAB (Internet Activities Board), das seine Aufgaben in zwei Bereiche teilt:
- Die IRTF (Internet Research Task Force) beschäftigt sich mit der langfristigen Forschung und Entwicklung.
- Im Gegensatz dazu ist die IETF (Internet Engineering Task Force) für die aktuellen Entwicklungen, Spezifikationen und die konkrete Standardisierung zuständig.
Für die Verwaltung eindeutiger Zuweisungen war ursprünglich die IANA zuständig (z. B. Port-Nummern, IP-Adressen).
Inzwischen organisiert die ICANN die Vergabe von Domain-Namen und neuen Top-Level-Domains. Die praktische Zuteilung von Adressen und Domains erfolgt regional delegiert: Das InterNIC agiert global, das RIPE-NCC koordiniert diese Aufgaben für Europa, und das DE-NIC ist spezifisch für Deutschland verantwortlich.
Für die Weiterentwicklung und Pflege von Standards, die spezifisch das World Wide Web betreffen (WWW-Technologie), ist das W3C (World Wide Web Consortium) zuständig.
1.3. Überblick über die TCP/IP-Protokollfamilie
TCP/IP wurde lange vor dem OSI-Modell entwickelt und ist grundsätzlich flexibler. Der TCP/IP-Protokoll-Stack ist hierarchisch strukturiert. Dieser besteht aus "nur" 4 DoD-Schichten (im OSI-Modell sind es 7), die darüber hinaus flexibel sind (z.B. die Benutzer können über verschiedene Schnittstellen auf die Netzzugangsebene zugreifen).
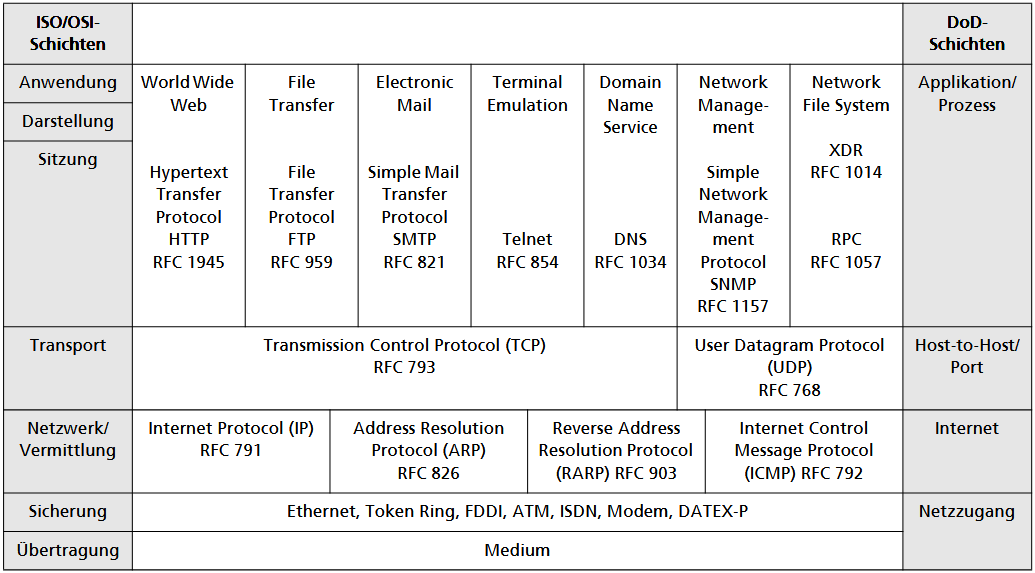
Die Anwendungsschicht ist die Benutzerschnittstelle und beinhaltet Protokolle wie SMTP, über die Anwendungsprogramme (z.B. E-Mail) kommunizieren und Internet-Dienste definieren.
Die darunterliegende Transportschicht (Host-to-Host) sorgt für die zuverlässige Beförderung der Daten von Sender zu Empfänger und reicht sie an die jeweilige Anwendungsschicht weiter.
In der Vermittlungs- oder Internetschicht (Network Layer) werden Daten in Pakete zerlegt und über verschiedene Routen durch das Netz geleitet.
Die unterste Schicht, die Netzzugangs- oder Verbindungsschicht (Network Access), entspricht den unteren beiden OSI-Schichten und ermöglicht den Versand über diverse Medien (z.B. Ethernet), wobei TCP/IP hier auf Standardprotokolle und Hilfsprotokolle wie ARP zurückgreift.
Innerhalb des TCP/IP-Stacks gibt es verschiedene Kommunikationspfade: Anwendungen können entweder direkt auf die Internetschicht zugreifen (z.B. via ICMP) oder über die Transportschicht kommunizieren, wobei sie Protokolle wie TCP oder UDP nutzen. Unabhängig von der gewählten Route oder dem Protokoll der höheren Schichten müssen jedoch alle Daten zwingend über das IP-Protokoll der Internetschicht laufen.
Die Daten durchlaufen in der Regel alle vier Schichten, wobei die Nutzdaten jeder Ebene um spezifische Verwaltungsdaten ergänzt werden; die resultierenden Dateneinheiten heißen je nach Schicht Rahmen, Datagramm oder Segment. Aufgrund der weltweiten Dominanz von TCP/IP ist eine Ablösung durch das OSI-Modell unwahrscheinlich; stattdessen wird die Protokollfamilie kontinuierlich durch RFCs weiterentwickelt.
2. Der Netzzugang: Network Access Layer
Die untersten zwei Schichten des OSI-Modells (Bitübertragung & Datensicherung) werden im Internet-Modell (TCP/IP) zu einer einzigen Schicht namens "Netzzugang" zusammengefasst. Sie dienen als "Transporteur" für das IP-Protokoll. Sie nehmen das IP-Paket, verpacken es in einen Rahmen (Framing), prüfen auf Fehler und senden es physikalisch über das Kabel oder die Funkstrecke.
In lokalen Netzen dominieren Ethernet-Varianten, während Token-Ring und andere Protokolle selten geworden sind. Große, zentrale Netzknoten nutzen für breitbandige Verbindungen Techniken wie ATM (Asynchronous Transfer Mode), das FDDI und Frame Relay weitgehend abgelöst hat. Für den normalen Nutzer sind diese Backbone-Technologien unsichtbar; relevant ist der Zugang zum Internet über öffentliche Leitungen, deren Bandbreite von Modems über ISDN bis zu xDSL reicht.
Moderne Betriebssysteme liefern Protokoll-Stacks mit, die den Zugriff der Vermittlungsschicht auf gängige Medien ermöglichen, insbesondere über Netzwerkkarten auf IEEE-802-Netze. ISDN-Karten werden dabei treiberseitig oft als Pseudo-Modems oder -Netzwerkkarten eingebunden.
Eine besondere Herausforderung stellte die Datenübertragung über serielle Leitungen wie analoge Telefonnetze dar. Hier müssen IP-Pakete durch Rahmenbildung in einen seriellen Strom umgesetzt werden. Für diese Punkt-zu-Punkt-Verbindung zwischen Host und Router dient heute fast ausschließlich das PPP (Point-to-Point Protocol), während das ältere SLIP kaum noch Bedeutung hat.
2.1. Das Point-to-Point-Protocol (PPP)
Das Point-to-Point Protocol (PPP) ist ein Protokoll der Sicherungsschicht/Data Link Layer (OSI 2), das notwendig ist, um Netzwerkpakete (wie IP) über serielle Direktverbindungen (wie Telefon- oder DSL-Leitungen) zu transportieren, indem es diese in Rahmen verpackt (Framing) und Funktionen für den Verbindungsaufbau sowie die Authentifizierung bereitstellt.
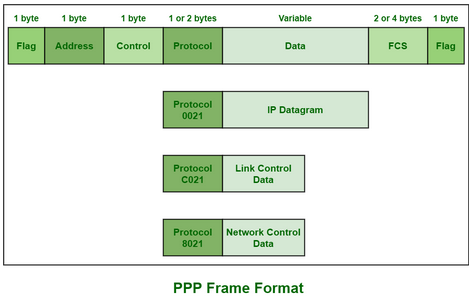
PPP baut auf dem HDLC-Protokoll (High Level Data Link Control) auf. PPP kennzeichnet eindeutig den Anfang und das Ende eines Rahmens und unterstützt die Fehlererkennung.
- Der PPP-Rahmen wird jeweils durch ein Flag-Byte
0111 1110eingerahmt. - Das Adresse-Feld enthält immer
1111 1111, im Control-Feld darf nur0000 0011stehen, beide HDLC-Felder sind damit de facto ungenutzt. (Bei einer direkten Leitung zwischen nur zwei Computern (Punkt-zu-Punkt) ist eine Adresse überflüssig. Es gibt nur einen einzigen möglichen Empfänger - hier der POC des ISP, point of presence) - Im folgenden zwei Byte langen Protokoll-Feld wird festgelegt, welches Protokoll im Datenteil eingepackt wurde.
- PPP ist so konzipiert, dass nicht nur IP-Datagramme (im Daten-Feld), sondern eine Vielzahl anderer Protokolle transportiert werden können.
- Das abschließende 16 Bit lange FCS-Feld (Frame CheckSequence) ermöglicht eine Fehlerkontrolle des Datenrahmens (Prüfsumme)
Das LCP-Protokoll (Link Control Protocol, RFC 1570) kann im Datenteil vorhanden sein und ist für den ordnungsgemäßen Aufbau, die Konfigurierung, den Test und den Abbau eine PPP-Verbingund verantwortlich. Es ermöglicht den parallelen Betrieb mehrerer logischer Verbindungen, die Prüfung der Leitungsqualität und die Anpassung an diese.
Das Internet Protocol Control Protocol (IPCP) ist spezifisch für IP-Verbindungen über PPP relevant. Es dient dazu, Komprimierungsmechanismen auszuhandeln und ermöglicht, was bei Wählverbindungen zu Providern essenziell ist, die Zuweisung dynamischer IP-Adressen beim Verbindungsaufbau.
2.2 PPP over Ethernet (PPPoE)
Das Protokoll PPPoE wird insbesondere für den Aufbau von ADSL-Internetverbindungen genutzt. Technisch wird dabei ein externes DSL-Modem über eine Netzwerkkarte mit dem Computer verbunden. Diese Methode wurde gewählt, da ältere Schnittstellen für die hohen DSL-Geschwindigkeiten zu langsam waren und moderne Alternativen wie USB zum Zeitpunkt der Einführung noch nicht standardmäßig verfügbar waren.
Ein zentrales Merkmal von PPPoE ist die Authentifizierung des Nutzers durch Benutzername und Passwort. Die Kommunikation erfolgt dabei direkt zwischen dem Endgerät und dem Internetanbieter. Die dazwischenliegende Hardware, wie der DSL-Splitter, leitet die Signale lediglich weiter und hat keinen Einfluss auf den Anmeldevorgang, weshalb sie problemlos ausgetauscht werden kann.
Der Weg der Verbindung sieht folgendermaßen aus:
PC (Netzwerkkarte) → Ethernet-Kabel (LAN) → DSL-Modem → Telefonkabel (Twisted Pair) → Telefonbuchse in der Wand → Hausanschluss im Keller → Kupferkabel unter der Straße → DSLAM (grauer Kasten an der Straßenecke oder in der Vermittlungsstelle des Anbieters)
Im Gegensatz dazu funktionieren Kabelmodems technisch anders, da sie dem Nutzer direkt eine fertig konfigurierte Ethernet-Schnittstelle bereitstellen und vom Anbieter fernverwaltet werden. Eine manuelle Anmeldung durch den Nutzer ist hier meist nicht notwendig. Möchte man einen für DSL konzipierten Router an einem Kabelmodem betreiben, muss der WAN-Anschluss umkonfiguriert werden. Statt der PPPoE-Einwahl muss der Router so eingestellt sein, dass er die IP-Adresse sowie Gateway- und DNS-Informationen automatisch über das Netzwerkprotokoll DHCP vom Kabelmodem bezieht.
3. Die Vermittlungsschicht: Internet Layer
Die Vermittlungsschicht (Internet Layer) beherbergt das fundamentale Internet Protocol (IP), das zusammen mit TCP (auf der Transportschicht) das Kernpaar des TCP/IP-Stacks bildet. Während IP für die paketweise Übertragung von Teilstrecke zu Teilstrecke zuständig ist, gewährleistet TCP die Zuverlässigkeit der gesamten Ende-zu-Ende-Verbindung. Die Hauptaufgabe dieser Schicht besteht darin, verschiedene Subnetze zu verbinden und so die Illusion eines einzigen, zusammenhängenden Netzes zu erzeugen. Die Protokolle definieren hierbei, wie Pakete (IP-Datagramme) über Router von Knoten zu Knoten geleitet werden.
Neben dem zentralen IP (v4 und v6) existieren wichtige Kontroll- und Hilfsprotokolle. ICMP dient der Fehlerbehandlung und Steuerung, während ARP und RARP für die Übersetzung zwischen logischen IP-Adressen und physikalischen Netzwerkadressen verantwortlich sind.
3.1. Das Internet Protocol (IP)
Ein Ziel der Forschungen im Auftrag der ARPA war es, bestehende Netzwerke (Subnets) zu einem gemeinsamen Netz (Internet) zusammenzufassen. Als Resultat entstand das Internet Protocol, das die Subnetze miteinander verbinden sollte. Seine Aufgabe ist es, Pakete (genauer: Datagramme) vom Absender zum Empfänger zu befördern, unabhängig davon, ob sich diese Rechner im gleichen Netz befinden oder ob andere Netze dazwischenliegen.
3.1.1. Funktionsweise und Aufbau
Das Internet Protocol (RFC 791) überträgt Daten bzw. Nachrichten von Knoten zu Knoten im Internet. Es tut dies mittels verbindungsloser Kommunikation. Das bedeutet, dass keine Verbindung zu einem Rechner „geöffnet“ wird. Stattdessen werden einzelne Pakete abgeschickt und man verlässt sich darauf, dass sie ankommen.
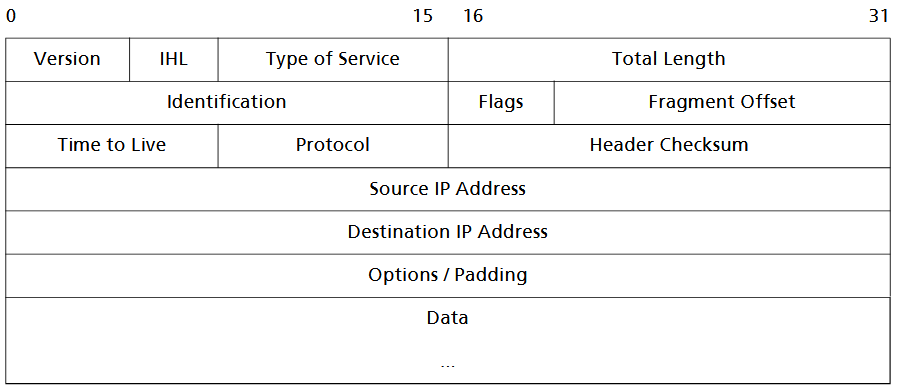
Die Bedeutungen der einzelnen Felder sind (die Zahlen in eckigen Klammern beziehen sich auf die jeweilige Länge des einzelnen Feldes in Bit):
- Version [4]: Versionsnummer des Protokolls; aktuell: 4; demnächst: 6 (IPv6).
- Internet Header Length (IHL) [4]: Länge des Headers, gemessen in 32-Bit-Blöcken; sie ist durch Einbeziehung von unterschiedlichen Optionen (Feld Options) variabel.
- Type of Service (TOS) [8]: Dienstkennung, beschreibt die Art des angeforderten Dienstes (wird wenig genutzt).
- Total Length [16]: Gesamtlänge des IP-Datagramms (max. 65535 Byte).
- Identification [16]: Zahlenwert zur Identifizierung von fragmentierten Paketen. Alle Fragmente eines Pakets haben den gleichen Wert. So können die Fragmente dem Originalpaket zuge- ordnet werden. Flags [3]: Sie geben an, ob fragmentiert werden darf oder nicht, und ob weitere Fragmente fol- gen, oder es das letzte ist.
- Fragment Offset [13]: Er bestimmt die Position (Folgenummer) des Fragments innerhalb des Originalpake- tes, damit eine Reassemblierung erfolgen kann.
- Time to Live (TTL) [8]: Hier wird die „Lebensdauer“ des Datagramms vorgegeben, aber nicht in Zeiteinheiten, sondern in der Anzahl der überquerten Knoten. Der Absender trägt die maximale Anzahl der Knoten ein, über die die Nachricht transportiert werden soll, bis sie den Empfänger erreicht. An jeder Zwischenstation wird der Wert um 1 reduziert. Erreicht TTL den Wert Null, wird das Datagramm verworfen. Damit lässt sich ein „Umherirren“ von Paketen vermeiden.
- Protocol [8]: Protokollkennung, identifiziert das übergeordnete Protokoll, an das das Datagramm weitergeleitet werden soll, z. B. 17: UDP, 6: TCP, 1: ICMP.
- Header Checksum [16]: Prüfsumme des IP-Headers. Sie ist nützlich für das Erkennen von Übertragungsfehlern. Die Werte für TTL und ggf. für Flag und Fragment Offset müssen beim Passieren eines Knotens geändert werden. Deshalb muss die Prüfsumme in jedem Knotenneu berechnet werden.
- Source IP Address [32]: IP-Adresse des absendenden Rechners.
- Destination IP Address [32]: IP-Adresse des empfangenden Rechners.
- Options [variable Länge bis zu 40 Bytes]: Diverse Optionen; kein Pflichtbestandteil des IP-Datagramms. Enthält Informationen über Routing, Diagnose und Statistik. Wegen der Gefahr des böswilligen Missbrauchs wird dieses Feld in Routern oft absichtlich ignoriert. Dieses Feld muss ggf. durch Padding (Auffüllen von Bits) auf Vielfache von 32 Bit aufgefüllt werden.
- Data: Der „Textteil“ des Pakets, Nutzdaten in beliebigem Format
IP erreicht seine hohe Leistungsfähigkeit durch den Datagrammdienst: Pakete werden unabhängig voneinander über das Netz geschickt.
Im Datagrammverkehr erreicht man
- flexible Adressierbarkeit (es kann eine unterschiedliche Anzahl von Stationen angesprochen werden)
- hohe Übertragungsgeschwindigkeit (es ist keine Bestätigung der übertragenen Datagramme notwendig, es gibt keine Fehlerkorrektur!)
- variables Routing (es können verschiedene Wege durchs Netz verwendet werden)
Fragmentierung und Reassemblierung
Die maximale Paketgröße MTU (maximum tranfer unit) variiert je nach Subnetztechnologie, weshalb IP-Datagramme fragmentiert werden müssen. Der IP-Header enthält hierfür spezifische Fragment-Informationen, die es dem Zielrechner ermöglichen, die Teilstücke wieder zum ursprünglichen Datagramm zusammenzusetzen. Da Fragmente in beliebiger Reihenfolge eintreffen können, nutzt der Empfänger den Fragment-Offset zur korrekten Einordnung.
Gehen Fragmente verloren, verhindert ein Timer, dass der Empfänger endlos wartet. Ist das Datagramm nach Ablauf der Zeit nicht vollständig, wird es nach dem „Alles-oder-Nichts“-Prinzip komplett verworfen. Um Verzögerungen durch Fragmentierung auf Teilstrecken zu vermeiden, lässt sich dieser Vorgang durch ein spezielles Flag im Header gezielt unterbinden.
Keine Fehlerkontrolle
IP-Datagramme können aus verschiedenen Gründen (Defekte, TTL-Ablauf, Überlastung) verloren gehen, ohne dass das IP-Protokoll selbst eine Zustellgarantie bietet oder Fehlerkorrekturen durchführt. Lediglich im Fall von Speicherüberlauf bei Routern existiert mit „Source Quench“ ein Mechanismus, um den Sender zur Reduzierung seiner Datenrate aufzufordern.
3.1.2. Adressierung / IP-Adressen
Die zentrale Funktion des IP-Protokolls ist damit die Paketzustellung in Netzwerken. Zur Erfüllung dieser Aufgabe ist es notwendig, dass die Kommunikationspartner über ein eindeutig sie identifizierendes Merkmal verfügen. Dieses findet sich in Form der IP-Adresse.
Eine IPv4-Adresse besteht aus 32 Bit und bietet theoretisch gut vier Milliarden (2^32) mögliche Adressen, doch dieser Raum schrumpft durch technische Vorgaben und Reservierungen, besonders wegen der wachsenden Zahl mobiler Geräte. Zur besseren Lesbarkeit werden die 32 Bit in vier Byte-Blöcke zerlegt, sogenannte Oktetts, die in der Dezimalschreibweise durch Punkte getrennt werden (Dotted-Decimal-Darstellung), sodass jede Gruppe einen Wert zwischen 0 und 255 annimmt.
Nicht alle Adressen können Endgeräte identifizieren, denn es gibt normale Geräteadressen, spezielle Netzwerk- und Broadcast-Adressen sowie Loopback-Adressen. Eine nutzbare Geräteadresse teilt sich in einen festen Netzpräfix, der festlegt, zu welchem Netzwerk der Rechner gehört, und einen veränderbaren Hostteil, der jedes Gerät innerhalb dieses Netzwerks eindeutig unterscheidbar macht.
Aufgabe der Vermittlungsschicht und Bedeutung der IP-Adresse
Die Vermittlungsschicht verbindet verschiedene Subnetze miteinander. Router empfangen Datenpakete und leiten sie anhand der Ziel-IP-Adresse zum richtigen Subnetz weiter. Damit ein Paket überhaupt versendet werden kann, muss der Absender die IP-Adresse des Empfängers kennen. Eine IP-Adresse ist weltweit eindeutig, besteht aus 32 Bit und setzt sich aus einem Netzteil und einem Hostteil zusammen. Der Netzteil identifiziert das Netzwerk, der Hostteil den einzelnen Rechner darin. Diese hierarchische Struktur ermöglicht effizientes Routing sowie eine globale Vergabe von Netzwerkanteilen und eine lokale Vergabe der Hosts.
IP-Adressklassen und Adressformate
IPv4-Adressen werden in Klassen eingeteilt, um Netze unterschiedlicher Größe zu unterstützen. Klasse A ist für sehr große Netze, Klasse B für mittlere und Klasse C für kleinere Netze vorgesehen. Klasse D dient dem Multicast-Empfang. Da das starre Klassensystem für viele Organisationen unpraktisch ist und Adressen knapp geworden sind, wurden flexible Verfahren wie CIDR eingeführt. Zudem ist langfristig die Umstellung auf IPv6 notwendig, das mit 128 Bit einen erheblich größeren Adressraum bietet.
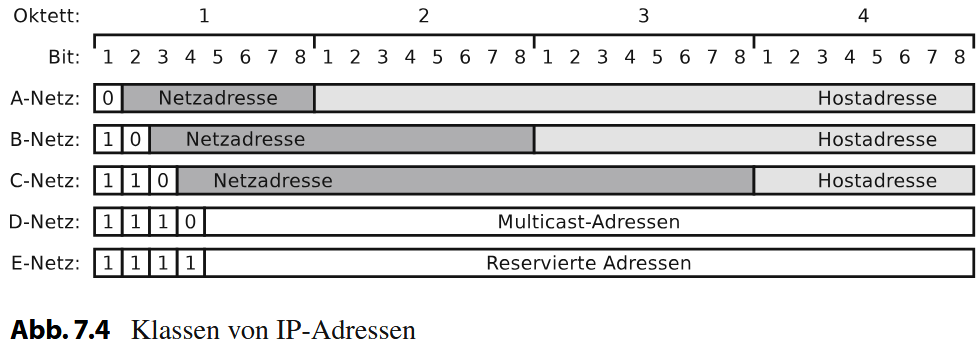
Um unterschiedliche Netzwerkgrößen abbilden zu können, wurden fünf Adressklassen eingeführt, Class A bis E, die jeweils die Grenze zwischen Netz- und Hostanteil an unterschiedlichen Stellen der 32-Bit-Adresse setzen.
- Class A-Adressen beginnen mit dem ersten Bit 0 und verwenden 8 Bit für das Netz und 24 Bit für Hosts. Daraus ergeben sich maximal 126 Netze (128 minus 2 für Spezialzwecke, 0 für Tests und 127 für Loopback) mit jeweils über 16 Millionen Hosts.
1.0.0.0 bis 126.255.255.255
- Class B-Adressen beginnen mit den ersten beiden Bits 10, teilen sich in 16-Bit-Netze und 16-Bit-Hosts auf, sodass 16.384 Netze mit je 65.534 Hosts möglich sind.
128.0.0.0 bis 191.255.255.255
- Class C-Adressen nutzen die ersten drei Bits 110 und erlauben 24 Bit für das Netz, 8 Bit für Hosts, wodurch über zwei Millionen Netze mit jeweils 254 Hosts entstehen.
192.0.0.0 bis 223.255.255.255
- Class D (1110) dient ausschließlich für Multicast,
224.0.0.0 bis 239.255.255.255
- Class E (1111) ist reserviert und wird nicht für reguläre Hosts verwendet.
240.0.0.0 bis 255.255.255.254
Besondere IP-Adressen haben spezifische Funktionen. Die Netzadresse eines Netzes enthält im Hostteil nur Nullen und identifiziert das gesamte Netz. Die Loopback-Adresse 127.0.0.1 ermöglicht einem Gerät, Netzwerksoftware zu testen, indem Pakete an sich selbst gesendet werden. Broadcastadressen setzen alle Hostbits auf Eins, um Nachrichten an alle Geräte eines Netzes gleichzeitig zu senden, z. B. 191.130.255.255 in einem Class-B-Netz.
Für private Netzwerke wurden bestimmte Adressbereiche reserviert, die nicht im Internet weitergeleitet werden und mehrfach von verschiedenen Organisationen genutzt werden können, wodurch die Knappheit an offiziellen IP-Adressen entschärft wird. Diese Adressen werden häufig in Verbindung mit Network Address Translation (NAT) eingesetzt, um interne Netzwerke mit dem öffentlichen Internet zu verbinden, ohne dass alle Geräte eine öffentliche IP-Adresse benötigen.
Offizielle IP-Adressen werden bei der IANA (Internet Assigned Numbers Authority) beantragt und regional von Organisationen wie RIPE (für Europa) vergeben. Unternehmen, die eine bestimmte Adresse zugewiesen bekommen, z. B. ein Class-B-Netz wie 140.25.0.0, können die verbleibenden Bytes frei zur internen Strukturierung nutzen. Oft wird das dritte Byte genutzt, um Abteilungen zu unterscheiden, und das vierte Byte, um Geräte innerhalb der Abteilung zu nummerieren. Dabei werden Hostadressen wie folgt verteilt: bestimmte Bereiche für Netzkomponenten, andere für PCs und wieder andere für Server. Netz- und Broadcastadressen dürfen niemals Geräten zugewiesen werden, und jede Hostadresse muss eindeutig sein, um Konflikte zu vermeiden.
Spezielle Adressen für besondere Zwecke
Broadcast-Adressen sprechen alle Geräte innerhalb eines Netzes an und entstehen durch Setzen aller Hostbits auf Eins. Die Adressen im Bereich 127.x.x.x dienen als Loopback-Adressen und ermöglichen interne Tests ohne Netzwerkverbindung. Die Adresse 0.0.0.0 wird von Geräten genutzt, die ihre Netzwerkkonfiguration noch nicht kennen, beispielsweise während der DHCP-Anfrage.
Private IP-Adressen und NAT
RFC 1597 definiert bestimmte Bereiche privater IP-Adressen, die nicht öffentlich geroutet werden. Sie werden in lokalen Netzwerken eingesetzt, etwa in Unternehmen oder Heimnetzen. Häufig werden sie in Verbindung mit NAT oder IP-Masquerading genutzt: Ein Router übersetzt interne Adressen in eine öffentliche Adresse, sodass interne Geräte im Internet nicht sichtbar sind.
Network Address Translation (NAT)
Das Verfahren Network Address Translation (NAT) wurde primär entwickelt, um dem Mangel an öffentlichen IPv4-Adressen entgegenzuwirken, indem es die Nutzung privater Adressbereiche in lokalen Netzwerken ermöglicht. Ein Router an der Schnittstelle zum Internet tauscht dabei die lokale Quell-IP-Adresse ausgehender Pakete gegen eine öffentliche IP-Adresse aus. Damit Antworten aus dem Internet den ursprünglichen Sender im lokalen Netz erreichen, führt der Router eine dynamische Übersetzungstabelle, welche die Zuordnung zwischen internen Anfragen und den entsprechenden externen Verbindungen speichert.
IP-Masquerading (PAT)
Eine spezielle und im Heim- sowie SOHO-Bereich dominierende Form des NAT ist das IP-Masquerading, technisch oft als Port Address Translation (PAT) oder NAPT bezeichnet. Hierbei werden alle Geräte eines gesamten Netzwerks hinter einer einzigen öffentlichen IP-Adresse „versteckt“ (maskiert), wobei der Router zur Unterscheidung der verschiedenen Datenströme zusätzlich die Port-Nummern des Transportprotokolls (TCP/UDP) modifiziert. Dies bietet neben der massiven Adressersparnis einen automatischen Sicherheitsgewinn, da interne Rechner nicht direkt aus dem Internet adressierbar sind und somit vor unaufgeforderten Zugriffen von außen geschützt bleiben.
Subnetzadressen und Subnetzmasken
Um große Netze weiter zu strukturieren, wird der Hostteil einer IP-Adresse erneut aufgeteilt. Mithilfe einer Subnetzmaske wird festgelegt, wie viele Bits für das Subnetz reserviert sind. Diese Unterteilung erleichtert internes Routing und die Verwaltung von Broadcast-Bereichen, während nach außen weiterhin eine gemeinsame Netzwerkadresse sichtbar bleibt.
Jedes Gerät in einem Netzwerk benötigt eine eindeutige IP-Adresse, die aus zwei Teilen besteht: dem Netzwerkanteil und dem Hostanteil. Durch die Bildung von Subnetzen wird der Netzwerkanteil einer IP-Adresse erweitert, wodurch eine klarere Struktur entsteht und der Datenverkehr innerhalb eines Netzwerks effizienter gesteuert werden kann. Subnetze helfen außerdem dabei, die Adressvergabe zu organisieren und die Anzahl der benötigten IP-Adressen für bestimmte Netzwerke zu optimieren.
Die Unterteilung erfolgt mithilfe einer sogenannten Subnetzmaske, die angibt, welche Bits einer IP-Adresse zum Netzwerkanteil gehören und welche für Hosts verfügbar sind. In IPv4 wird die Subnetzmaske meist in der Schreibweise mit vier Oktetten angegeben, zum Beispiel 255.255.255.0. In CIDR-Notation (Classless Inter-Domain Routing) wird die Anzahl der Bits, die für das Netzwerk reserviert sind, nach einem Schrägstrich hinter der IP-Adresse angegeben, etwa 192.168.1.0/24. Je mehr Bits für das Netzwerk verwendet werden, desto weniger Hosts können im jeweiligen Subnetz existieren, aber desto mehr Subnetze können gebildet werden.
Subnetting hat praktische Vorteile für die Netzwerksicherheit und die Leistungsfähigkeit. Durch die Aufteilung eines großen Netzwerks in kleinere Subnetze lässt sich der Broadcast-Verkehr reduzieren, da Broadcasts nur innerhalb eines Subnetzes gesendet werden. Außerdem kann die Netzwerkadministration einfacher erfolgen, da bestimmte Abteilungen oder Gerätegruppen eigene Subnetze erhalten. Subnetze ermöglichen auch eine flexiblere Zuweisung von IP-Adressen, was besonders in Unternehmen oder Organisationen mit vielen Geräten wichtig ist.
Subnetting konkretes Beispiel
Um ein Netzwerk zu unterteilen, wird die Subnetzmaske verlängert. Wir „leihen“ uns Bits vom Host-Anteil und schlagen sie dem Netz-Anteil zu. Es wird angenommen, dass unsere Standard Subnetzmaske 255.255.255.0 lautet. 255 heißt, das dementsprechende Oktett ist "geblockt" und für das Netzteil reserviert, 0 heißt das Oktett ist für Hosts freigegeben (mit Ausnahme der 0 = Router- und 255 = Broadcastadresse).
Um das Netzwerk in Subnetze zu unterteilen, muss die Subnetzmaske angepasst werden, und zwar so, dass der Netzwerkteil größer wird. Im letzten zweiten Oktett wird das erste Bit (128) auf 1 gesetzt.
Ursprung: 11111111.11111111.11111111.00000000 (255.255.255.0) Neu: 11111111.11111111.11111111.10000000 (255.255.255.128)
Das heißt nun haben wir:
- Anzahl Subnetze: 2^1=2 (da 1 Bit geliehen wurde).
- Schrittweite (Blockgröße): 256 : 2 = 128. Das Netz wird genau in der Mitte geteilt.
- Hosts pro Subnetz: Es verbleiben 7 Bits für Hosts (2^7=128).
Nutzbar: 128−2=126 Hosts (Minus Netzadresse & Broadcast).
Das erste Subnetz kann den Bereich 1 bis 126 für Hosts nutzen und das zweite den Bereich 129 bis 254.
Die moderne Schreibweise für eine Subnetzmaske ist in der CIDR-Notation(Classless Interdomain Routing): Die Zahl hinter dem Schrägstrich der IP-Adresse 172.21.240.90/27 ist die Anzahl der Einsen in der Netzmaske.
Dynamische Adressvergabe durch DHCP
DHCP ermöglicht die zeitlich begrenzte und automatische Vergabe von IP-Adressen. Ein Client fordert beim Start eine Adresse an und erhält vom Server ein Angebot, das er bestätigt. Die zugewiesene Adresse gilt nur für eine bestimmte Dauer und muss regelmäßig erneuert werden. Problematisch wird es, wenn Clients DHCP nutzen, obwohl kein Server vorhanden ist, da dies zu langen Wartezeiten führt. Mehrere DHCP-Server können parallel betrieben werden, sofern ihre Adressbereiche sauber abgestimmt sind.
Default-Gateway und Mehrfachadressierung von Routern
Für die Kommunikation zwischen Subnetzen wird in jedem Netz ein Standardrouter, das sogenannte Default-Gateway, benötigt. Oft verwendet man dabei die Adresse .1 des jeweiligen Subnetzes, auch wenn dies nur eine Konvention ist. Router besitzen in der Regel mehrere IP-Adressen, jeweils eine für jeden ihrer angeschlossenen Netzbereiche. Eine IP-Adresse identifiziert daher stets die Verbindung eines Geräts zu einem spezifischen Netzwerk, nicht den gesamten Rechner.
3.2 IPv6
Hintergrund und Adressraum von IPv6
Aufgrund der drohenden Adressknappheit bei IPv4 initiierte die IETF eine grundlegende Reform der Adressorganisation, die als IPv6 (Internet Protocol Version 6) eingeführt wurde. Im Gegensatz zum Vorgänger nutzt dieses Protokoll 128-Bit-Adressen, was den verfügbaren Adressraum auf über 340 Sextillionen erweitert. Diese enorme Menge reicht theoretisch aus, um jeden Quadratmeter der Erdoberfläche mit tausenden Adressen zu versorgen, wodurch auch der zukünftige Bedarf für vernetzte Alltagsgegenstände langfristig gedeckt ist.
Notation und Vereinfachung
Die Darstellung erfolgt in der Doppelpunkt-Hexadezimal-Notation. Hierbei wird die Adresse in acht Gruppen zu je 16 Bit unterteilt, die als vierstellige Hexadezimalzahlen notiert und durch Doppelpunkte getrennt werden. Zur Vereinfachung der Schreibweise dürfen führende Nullen innerhalb einer Gruppe entfallen. Zudem können aufeinanderfolgende Null-Gruppen einmalig durch zwei Doppelpunkte (Zero Compression) ersetzt werden, um die Adresse deutlich zu verkürzen.
IPv6-Adressen können daher wie folgt aussehen:
0815:0000:0000:CDEF:1234:0001:0002:0003815:::CDEF:1234:1:2:3- und sogar
0:0:0:0:0:0:1:1
Kompatibilität mit IPv4
Um den Übergang zwischen den Protokollgenerationen zu erleichtern, können alte IPv4-Adressen in das neue Format eingebettet werden. Dabei wird technisch unterschieden, ob das Endgerät bereits den neuen Standard beherrscht.
-
Bei Geräten, die IPv6 unterstützen, wird die alte Adresse einfach an eine Folge von Nullen angehängt:
-
0000:0000:0000:0000:0000:0000:193.17.45.39 -
0:0:0:0:0:0:193.17.45.39 -
::193.17.45.39::C111:2D27(C111:2D27ist das gleiche Bitmuster wie 193.17.45.39, nur hexadezimal geschrieben).
Bei Geräten, die nicht IPv6-fähig sind, wird die IPv4-Adresse durch einen vorangestellten Block von FFFF markiert, um die fehlende Kompatibilität zu signalisieren:
0000:0000:0000:0000:0000:FFFF:193.17.45.39::FFFF:193.17.45.39::FFFF:C111:2D27
Routing
IPv6 löst das Problem riesiger Routing-Tabellen durch eine hierarchische Aufteilung des Adressraums. Große Blöcke werden an Provider vergeben, sodass Router Entscheidungen allein anhand des Prefix treffen können, was Speicher und Rechenzeit spart. Zudem wurde der Basis-Header vereinfacht (acht statt 13 Felder); optionale Informationen werden in Extension Headers ausgelagert, was die Paketverarbeitung beschleunigt.
Unicast und Autokonfiguration
Unicast bleibt die wichtigste Adressierungsform. Die große Bitbreite ermöglicht eine Autokonfiguration, bei der Geräte ihre Adresse automatisch unter Einbeziehung der physischen MAC-Adresse generieren. Dies erleichtert die Integration mobiler Hosts enorm. Ein Providerwechsel betrifft nur den vorderen Teil der Adresse, wodurch interne Netze unberührt bleiben und komplexe Techniken wie NAT (Network Address Translation) entfallen.
Multicast
Multicast ermöglicht das Ansprechen einer ganzen Rechner-Gruppe, um beispielsweise beim Video Streaming identische Pakete nicht mehrfach über dieselbe Leitung zu senden. Im Gegensatz zu IPv4 ist diese Funktion bei IPv6 durch entsprechende Flags im Header fest vorgesehen und vereinfacht die Konfiguration der Router.
Anycast
Das neue Anycast-Verfahren adressiert eine Gruppe von Rechnern, wobei das Paket an denjenigen gesendet wird, der am nächsten liegt oder zuerst antwortet. Dies eignet sich hervorragend für Lastverteilung und Ausfallsicherheit (Redundanz) bei Servern wie DHCP oder Routern, ohne dass komplexe outing-Informationen ausgetauscht werden müssen.
Prüfsummen
Im Gegensatz zu IPv4 verzichtet IPv6 im Basis-Header auf eine Prüfsumme, da moderne Übertragungsnetze als hinreichend zuverlässig gelten. Dies eliminiert die Notwendigkeit, die Prüfsumme bei jedem Hop (wegen der Änderung der TTL) neu zu berechnen, was die Verarbeitungsleistung deutlich steigert.

- Das Feld Version gibt die Version des IP-Protokolls an, hier also 6.
- Payload Length entspricht dem Längenfeld von IPv4, allerdings wird hier nur die Länge der Nutzdaten (und nicht des gesamten Pakets) angegeben.
- Next Header spezifiziert, ob und welche(r) Erweiterungsheader folgt/folgen.
- Das Feld Hop Limit entspricht dem TTL-Feld von IPv4. Es ist das einzige Feld, das sich noch beim Durchlauf durch einen Router ändert.

Quality of Service (QoS)
IPv6 führt die Felder Priority und Flow Label ein, um Datenströmen bestimmte Gütemerkmale zu garantieren.
- Flow Label etabliert eine Pseudoverbindung, während
- Priority Eigenschaften wie Verzögerungstoleranz festlegt.
Dies ermöglicht Echtzeitanwendungen wie Videostreaming oder Telefonie ohne Qualitätsverlust („ruckelfrei“), indem Mindestanforderungen wie Bandbreite gesichert werden; ein entscheidender Vorteil gegenüber der klassischen Internet-Technologie.
Übertragungssicherheit
- Durch Extension Headers bietet IPv6 native Sicherheitsfunktionen.
- Der Authentication Header ermöglicht mittels digitaler Unterschriften die Verifikation des Absenders und schützt vor Manipulation.
- Zudem erlaubt ESP (Encapsulation Security Payload) die Verschlüsselung von Nutzdaten oder kompletten Paketen, was Herkunft und Ziel verschleiert und den Aufbau von VPNs erheblich vereinfacht.
Migration und Koexistenz
Der Übergang zu IPv6 wird über Jahre hinweg durch Koexistenz-Strategien realisiert. Ein Teil des IPv6-Adressraums ist für IPv4 reserviert. Router unterstützen beide Protokolle (Dual-Stack), und IPv4-Teilstrecken können durch Tunneling (Verpacken von IPv6 in IPv4) überbrückt werden, was jedoch die Leistung mindert.
Langfristig wird der Adressmangel den Umstieg erzwingen. Wenn reine IPv6-Adressen vergeben werden, droht alten Systemen ohne IPv6-Unterstützung die Isolation. Betreiber werden daher voraussichtlich noch lange beide Adressformate parallel nutzen (Aliasing), um Erreichbarkeit zu garantieren, während der Druck auf Backbone-Betreiber und Nutzer wächst, ihre Hard- und Software zu aktualisieren.
3.3. ICMP
ICMP ist ein wichtiges Protokoll für die Steuerung und Wartung des Internets (oder von Teilen davon). Das Internet Control Message Protocol ICMP (RFC 792) dient der Übermittlung von Meldungen (Informations- und Fehlermeldungen). Sie werden zwischen den beiden Kommunikationspartnern (Knoten) ausgetauscht, wenn z. B. bei der Datenübertragung Fehler auftreten.
ICMP-Meldungen werden in IP-Datagrammen gekapselt und mit dem IP-Protokoll übertragen. ICMPv6 ist das entsprechende Protokoll für IPv6, das für den Betrieb von IPv6 zwingend notwendig ist.
IP und ICMP sind gegenseitig abhängig: IP transportiert ICMP-Nachrichten, ICMP meldet IP-Fehler. ICMP-Meldungen befinden sich im Datenteil eines IP-Pakets. Bei fragmentierten IP-Paketen wird nur für das erste Fragment eine ICMP-Nachricht erzeugt.

Wichtige ICMP-Meldungstypen (IPv4)
-
Destination Unreachable Router senden diese Meldung, wenn ein Paket das Ziel nicht erreichen kann. Der Code gibt an, ob ein Host oder ein Netzwerk unzugänglich ist.
-
Time Exceeded Diese Meldung entsteht, wenn der TTL-Wert eines Pakets auf 0 fällt und der Router es verwirft. Auch ein Host kann sie senden, wenn beim Zusammensetzen fragmentierter Pakete der Timer abläuft.
-
Echo Request / Echo Reply Für Diagnosezwecke, z. B. durch ping. Ein Echo Request erwartet zwingend einen Echo Reply. Fehlt die Antwort, gilt der Zielrechner als nicht erreichbar (auch wenn manche Systeme Echo-Antworten deaktivieren).
-
Time Stamp Request / Reply Erlauben die Messung von Netzzeiten durch Aufnahme der Ankunfts- und Sendezeit.
Aufbau eines ICMP-Pakets (eingebettet in IPv4)
Im IP-Header wird das Protocol-Feld auf 1 gesetzt. Die ICMP-Nachricht selbst besteht aus:
- Type (8 Bit) – identifiziert den Nachrichtentyp
- Code (8 Bit) – differenziert Meldungen bestimmter Typen weiter
- Checksum (16 Bit) – Prüfsumme ab dem Type-Feld
- Data (variabel) – enthält meist Header + erste 64 Bit des fehlerhaften IP-Pakets; kann missbräuchlich verwendet werden
ICMP-Pakete sind kurz, erzeugen aber dennoch Verwaltungsaufwand für Router.
ICMPv6
ICMPv6 ist für den Betrieb von IPv6 unverzichtbar (z. B. für Neighbor Discovery). Wird es durch eine Firewall blockiert, funktioniert IPv6 nicht. In IPv6-Paketen steht 58 im Next-Header-Feld.
Der ICMPv6-Header enthält:
- Type (8 Bit) – legt die Nachrichtengruppe fest
- Code (8 Bit) – genauere Klassifikation
- Checksum (16 Bit) – umfasst Pseudoheader + ICMPv6-Nachricht (wichtige Neuerung gegenüber IPv4-ICMP)
3.4 ARP (Address Resolution Protocol)
IP-Adressen sind logische Adressen, während Netzwerkkarten ausschließlich mit physischen MAC-Adressen arbeiten. Damit Geräte in lokalen Netzen (z. B. Ethernet) IP-Pakete zustellen können, muss die logische IP-Adresse in eine physikalische MAC-Adresse umgesetzt werden. Diese Aufgabe übernimmt das Address Resolution Protocol (ARP).
ARP verwaltet eine Tabelle (**ARP-Cache), in der bereits bekannte IP-zu-MAC-Zuordnungen gespeichert sind. Ist die gesuchte Zuordnung nicht vorhanden, erfolgt eine Netzabfrage.
Bei unbekannter MAC-Adresse sendet ein Rechner ein Broadcast-Paket mit einem ARP-Request, den alle Geräte im Netzsegment empfangen. Erkennt ein Gerät seine eigene IP-Adresse im Request, sendet es ein ARP-Reply mit seiner MAC-Adresse zurück. Der anfragende Rechner speichert die Zuordnung im ARP-Cache und kann anschließend Pakete direkt adressieren.
Router leiten ARP-Requests nicht weiter, um Broadcast-Fluten zu verhindern. Geht ein Request an eine Adresse außerhalb des eigenen Subnetzes, antwortet mit seiner eigenen MAC-Adresse und übernimmt die Weiterleitung gemäß Routingtabelle.
ARP ist sehr einfach zu betreiben: Administratoren müssen nur die IP-Adressen eines Subnetzes vergeben, alles andere erledigt ARP automatisch. Statische Zuordnungen oder berechnete Adressen werden nur in Spezialfällen genutzt.
Weitere verwandte Protokolle:
- NDP (Neighbor Discovery Protocol) – ersetzt ARP in IPv6
- RARP – früher zur Ermittlung der IP-Adresse aus einer MAC-Adresse, heute veraltet
- DHCP / DHCPv6 – verteilt dynamisch IP-Adressen (bei IPv6 für Zusatzinformationen)
- BOOTP – dient u. a. zum Adressbezug beim Start plattenloser Workstations
4. Protokolle der Transportschicht: Host-to-Host-Layer
Transportschicht – Lage und Aufgabe
Die Transportschicht liegt zwischen Anwendungs- und Vermittlungsschicht. Sie vermittelt die Kommunikation zwischen Anwendungsprogrammen auf Sender- und Empfängerrechner, die über Portnummern identifiziert werden. Diese Ende-zu-Ende-Kommunikation stellt sicher, dass Daten korrekt, vollständig und in der richtigen Reihenfolge an die Anwendungsschicht gelangen.
Die Transportschicht nutzt TCP und UDP. TCP ist verbindungsorientiert und zuverlässig, während UDP verbindungslos und ungesichert arbeitet. TCP sorgt für die gesicherte Übertragung, UDP wird eingesetzt, wenn Geschwindigkeit wichtiger ist als Zuverlässigkeit.
Portnummern identifizieren Dienste und Anwendungen, sodass mehrere Programme auf demselben Rechner gleichzeitig über dieselbe IP-Adresse kommunizieren können.
4.1. TCP
TCP (Transmission Control Protocol) stellt eine Punkt-zu-Punkt-Verbindung zwischen Sender und Empfänger her. Die Anwendungsschicht übergibt die Daten streamorientiert (Byte für Byte) an TCP, das den Datenstrom in Segmente aufteilt. Jedes Segment erhält einen eigenen TCP-Header und wird an IP übergeben, das die Segmente in IP-Datagramme verpackt und über das Netzwerk versendet.
Am Empfänger entfernt TCP die Header, prüft die Daten auf Fehler, stellt die richtige Reihenfolge wieder her und übergibt die Daten an die Anwendung. Durch diese Mechanismen garantiert TCP die zuverlässige Kommunikation, sodass die Anwendungsschicht sich nicht um Fehlererkennung oder -behandlung kümmern muss.
4.1.1. Adressierung und Sockets
Damit ein Anwendungsprozess eine Verbindung zu einem entfernten Prozess aufbauen kann, muss er den Partner genau identifizieren. Auf der Transportschicht erfolgt die Adressierung über Portnummern, die zusammen mit der IP-Adresse einen Socket bilden (den Endpunkt der Kommunikation). TCP baut explizit eine Verbindung zwischen Sockets von Sender und Empfänger auf.
Portnummern sind 16 Bit lang und ermöglichen somit 65535 verschiedene Ports
Sogenannte Well-Known Ports (IANA, RFC 1010):
- FTP → Port 21
- HTTP/WWW → Port 80
Die vollständige Transportadresse (Socket) kombiniert IP-Adresse und Portnummer, z. B. 134.103.192.6:80. Die Socketnummern von Quelle und Ziel identifizieren die Verbindung und die Anwendungen, die miteinander kommunizieren.
Hierarchie der Adressen
Die TCP/IP-Adressierung ist hierarchisch aufgebaut:
- Port #x → Identifiziert den Prozess/Anwendung auf dem Host
- Host #y → IP-Adresse des Computers
- Network #z → Subnetz, in dem sich der Host befindet
Diese Hierarchie ermöglicht, dass die Kommunikation immer eindeutig von einem Anwendungsprozess auf einem Host zu einem Anwendungsprozess auf einem anderen Host geleitet wird.
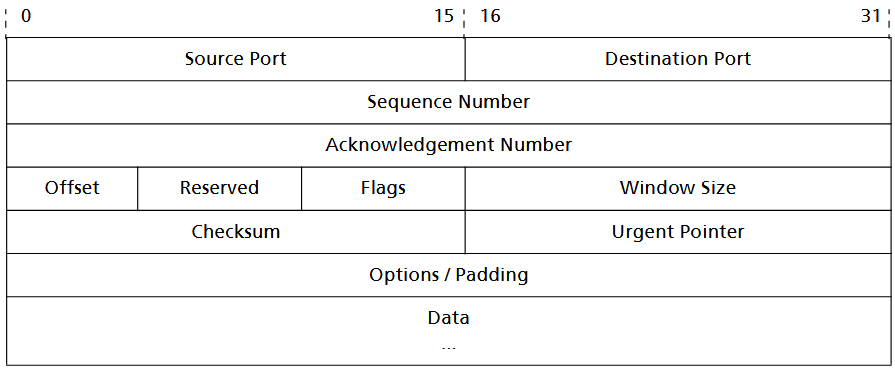
4.1.2. TCP-Segment-Aufbau
TCP fragmentiert den Datenstrom der Anwendungsschicht in Segmente, die jeweils einen TCP-Header enthalten. Diese Segmente werden sequenzgerecht und fehlerfrei übertragen. Ein TCP-Segment besteht aus drei Hauptteilen: dem Pseudoheader, dem TCP-Header und dem Datenbereich. Der Pseudoheader erweitert die Fehlererkennung auf IP-Header-Informationen, um fehlgeleitete Datagramme zu erkennen.
Pseudoheader
Der Pseudoheader enthält Informationen aus dem IP-Header:
- IP-Quelladresse
- IP-Zieladresse
- 8-Byte-Leerfeld
- Protokoll-Identifier
- Länge des TCP-Segments
Er wird nur für die Berechnung der Prüfsumme verwendet und nicht tatsächlich übertragen.

TCP-Header
Der TCP-Header enthält Steuerinformationen für die Verbindung und die Segmentverwaltung:
- Source Port [16] – Port des sendenden Anwendungsprozesses
- Destination Port [16] – Port des empfangenden Anwendungsprozesses
- Sequence Number [32] – Nummer des ersten Bytes im Segment, für Reihenfolgekontrolle
- Acknowledgement Number [32] – Bestätigung empfangener Daten, gibt an, welches Byte als nächstes erwartet wird
- Data Offset [4] – Länge des TCP-Headers in 32-Bit-Blöcken
- Reserved [6] – nicht verwendet, enthält Nullen
- Control Flags [6] – Statusinformationen über die Verbindung (urgent pointer, acknoledgment usw.)
- Window Size [16] – Fenstergröße zur Flusskontrolle, gibt an, wie viele Bytes unbestätigt gesendet werden dürfen
- Checksum [16] – Prüfsumme über TCP-Header und Pseudoheader
- Urgent Pointer [16] – Zeigt Ende von Vorrangdaten innerhalb eines Segments an
- Options [variabel] – Zusatzinformationen, z. B. maximale Segmentgröße (MSS), Ende der Optionsliste, keine Operation; ggf. mit Padding auf 32-Bit-Vielfache
Der Datenbereich enthält die Nutzdaten der Anwendung, die von TCP zuverlässig an den Empfänger übergeben werden.
4.1.3. Verbindungsmanagement
TCP ist das Transportprotokoll im TCP/IP-Stack. Es sorgt für die verbindungsorientierte, gesicherte und zuverlässige Kommunikation von Endteilnehmer zu Endteilnehmer (vollduplex). Der Datenstrom wird in für die Datenübertragung geeignete Segmente unterteilt und beim Empfänger wieder in der richtigen Reihenfolge zusammengesetzt.
TCP erzeugt für Anwendungen die Illusion eines dedizierten Kanals, obwohl die Daten tatsächlich über das paketvermittelte IP-Netz übertragen werden. TCP ist verbindungsorientiert und sorgt für die sequenzgerechte und fehlerfreie Auslieferung der Segmente. Daten werden an IP übergeben, als IP-Datagramme über das Netz geschickt und am Empfänger wieder als TCP-Segmente zusammengesetzt. Für jedes korrekt empfangene Segment sendet der Empfänger eine Bestätigung (ACK) zurück. TCP ermöglicht Vollduplexübertragung, sodass beide Endpunkte gleichzeitig Daten senden und empfangen können.
Verbindungsmanagement
Das TCP-Verbindungsmanagement regelt den Verbindungsaufbau, Verbindungskontrolle und den Verbindungsabbau.
Ein Server geht in den passive open-Status, wartet auf Kontaktaufnahme durch einen Client. Ein Client initiiert einen Connection Request und geht in den active open-Status.
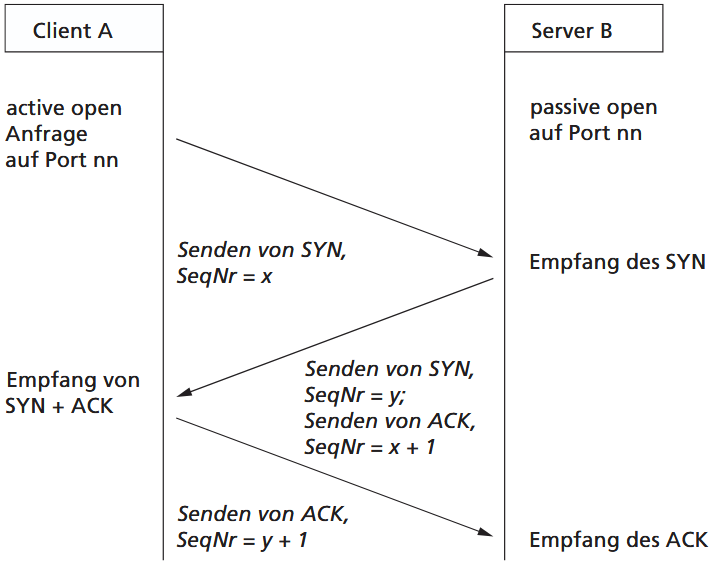
Verbindungsaufbau – Drei-Wege-Handshake
-
SYN: Client A sendet ein Segment mit gesetztem SYN-Flag und einer zufällig gewählten Sequenznummer.
-
SYN + ACK: Server B antwortet mit SYN-Flag und eigener Sequenznummer, zusätzlich ACK für die Sequenznummer des Clients.
-
ACK: Client A bestätigt die SYN-Nummer des Servers, die Verbindung ist nun aufgebaut.
Die besonderen Eigenschaften von TCP lassen sich folgendermaßen zusammenfassen:
- Punkt-zu-Punkt: genau ein Sender und ein Empfänger je Verbindung,
- Ende-zu-Ende: die logische Verbindung zwischen Sender und Empfänger wird nicht von Netzwerkkomponenten (Router, Switch) unterbrochen,
- verbindungsorientiert: vor der Übertragung wird ein Handshake für den Verbindungsaufbau und den Austausch von Parametern durchgeführt,
- zuverlässig: die Daten werden bei Fehlern im Netz durch Retransmits ggf. mehrfach übertragen. Scheitern auch diese Versuche, wird eine Fehlermeldung an die Anwen dung übergeben,
- vollduplex: Nutzdaten und Kontrollinformationen können gleichzeitig in beide Richtungen der Verbindung ausgetauscht werden.
Die TCP-Felder sind wie folgt definiert: – Quellport identifiziert die Portnummer des Anwendungsprogramms des Senders, – Zielport identifiziert die Portnummer der Anwendung des Ziels, – Sequenznummer definiert eine während der Verbindungsdauer geltende virtuelle Verbindungsidentifikation. Sie entspricht der Sequenznummer des Vorgängersegmentes vergrößert um die Datenanzahl des laufenden Segmentes, – Acknowledgement Nummer bezeichnet eine eindeutige Nummer, die den Empfang einer Anzahl von Segmenten bestätigt. Fehlt diese Bestätigung innerhalb einer Zeitschranke, erfolgt eine Retransmission der Segmentfolge. Sie wir aus dem vorhergehenden Acknowledgement plus dem Betrag der erhaltenen Daten gebildet, – Offset gibt die Länge des TCP-Headers in 32-Bit-Worten an und damit die Stelle, ab der die eigentlichen Daten beginnen, – Reserviert besitzt keine Verwendung.
- Windowgröße erlaubt es einem Empfänger, dem Sender über ACK-Messages mitzuteilen, wie viel Pufferplatz in Byte zum Empfang der Daten zur Verfügung steht. Ein Eintrag von 0 stoppt den Sendevorgang,
- Prüfsumme verifiziert das gesamte Segment (Header + Daten),
- Urgent-Zeiger beschreibt die Position priorisierter Daten, die so schnell wie möglich verarbeitet werden sollen. Damit können außergewöhnliche Zustände signalisiert werden.
- Optionen können entweder aus einem einzelnen Byte – der Optionsnummer – bestehen oder eine variable Form aufweisen. Ihr Auftreten ist Ursache der variablen Größe des Header
Fehlerkontrolle und Übertragungswiederholung
Segmente können bei der Übertragung verloren gehen oder beschädigt werden. TCP erkennt Beschädigungen über eine 1er-Komplement-Prüfsumme des gesamten Segments und fehlende Segmente anhand der Sequenznummer. Nach dem Versenden eines Segments startet der Sender einen Timer und wartet auf die Bestätigung (ACK) des Empfängers. Kommt diese nicht rechtzeitig, wird das Segment erneut gesendet. Sequenznummern ermöglichen zudem die Erkennung von Duplikaten, falls eine Bestätigung verspätet eintrifft. Um auch bei großen Verzögerungen oder Host-Ausfällen eine eindeutige Zuordnung zu gewährleisten, kann eine auf der Uhrzeit basierende Initial-Sequenznummer (clock-based) verwendet werden, die bei einem 4-Mikrosekunden-Intervall Segmente über mehrere Stunden eindeutig identifiziert.
Flusskontrolle (Windowing)
Die Flusskontrolle wird durch Übertragungsverzögerungen und durch verlorene Segmente erschwert. Aus diesem Grund vergibt der Empfänger explizit Sendekredite.
Die Empfangsbestätigung hat dann die Form (ACK i, CREDIT j)
ACK iquittiert alle Segmente bis zur Nummeri-1; die nächste erwartete Sequenznummer isti.CREDIT jerlaubt die Übertragung weitererjSegmente, d. h., es darf von Nummeribis zur Nummeri+j-1gesendet werden.
Kann der Empfänger die Daten so schnell lesen, wie sie ankommen, sendet er mit jeder Bestätigung eine positive Kreditanzeige. Arbeitet der Sender aber schneller als der Empfänger, füllt sich der Puffer beim Empfänger. In diesem Fall wird er keinen weiteren Kredit vergeben, der Sender muss so lange warten, bis er wieder eine positive Anzeige erhält.
Verbindungsabbau
Zum Beenden der Verbindung gibt es zwei Möglichkeiten:
- Fehlerfall (abrupt): Es wird ein abort primitive eingeleitet. Dabei wird die Verbindung durch Setzen des RST-Flags (Reset) sofort beendet. Es werden keine Datenflussmechanismen zur Vermeidung von Datenverlust berücksichtigt.
- Normales Beenden (graceful): Die Verbindung wird durch ein gegenseitiges Abstimmungsverfahren über das FIN-Flag (Final) (ähnlich dem Drei-Wege-Handshake) zuverlässig abgebaut. Beim normalen Beenden gehen deshalb keine Daten verloren.
4.2. UDP (User Datagram Protocol)
UDP wird als Transportprotokoll für die Ende-zu-Ende-Kommunikation über fastverzögerungslose, fehlerfreie Strecken verwendet, sowie für kurze, isolierte Informationspakete oder wenn Performance wichtiger ist als Sicherheit.
Nicht jede Netzkommunikation benötigt die Zuverlässigkeit von TCP. In lokalen Netzen ist die Fehlerwahrscheinlichkeit gering, und viele Vorgänge übertragen nur ein einzelnes Paket. TCP-Aufwand für Verbindungsaufbau, -abbau und Fehlerkontrolle wäre hier unnötig. Auch bei Anwendungen wie Video-Streaming ist Leistung wichtiger als absolute Zuverlässigkeit, kleine Fehler fallen weniger ins Gewicht. Für solche Fälle wird das verbindungslose UDP (User Datagram Protocol) genutzt. UDP überträgt Segmente ohne Verbindungsaufbau und ohne umfassende Fehlerkontrolle, eine Prüfsumme ist optional.
Ein UDP-Segment besteht aus einem Pseudoheader, dem UDP-Header und dem Datenbereich.
Der 12-Byte-Pseudoheader enthält die Quell- und Ziel-IP-Adresse, den Protokolltyp und die Segmentlänge.
Der UDP-Header umfasst Source Port, D****estination Port, Länge und Checksum.
UDP ist trotz seiner Einfachheit weit verbreitet, vor allem für Verwaltungspakete oder lokalen Netzverkehr. Es dient als Schnittstelle zwischen Anwendungen und IP, ermöglicht Port-Demultiplexing und erlaubt mehreren Anwendungen gleichzeitig den Datagramm-Austausch, ohne dass Verbindungen aufgebaut werden müssen.
4.3. Feste Port-Nummern
Im Folgenden geben wir Ihnen eine Übersicht über häufig benutzte Ports. Die einensind den Kommunikationspartnern wohlbekannt (well known ports). Die anderen (oberhalb der Portnummer 1024) sind in der Praxis oft anzutreffen.
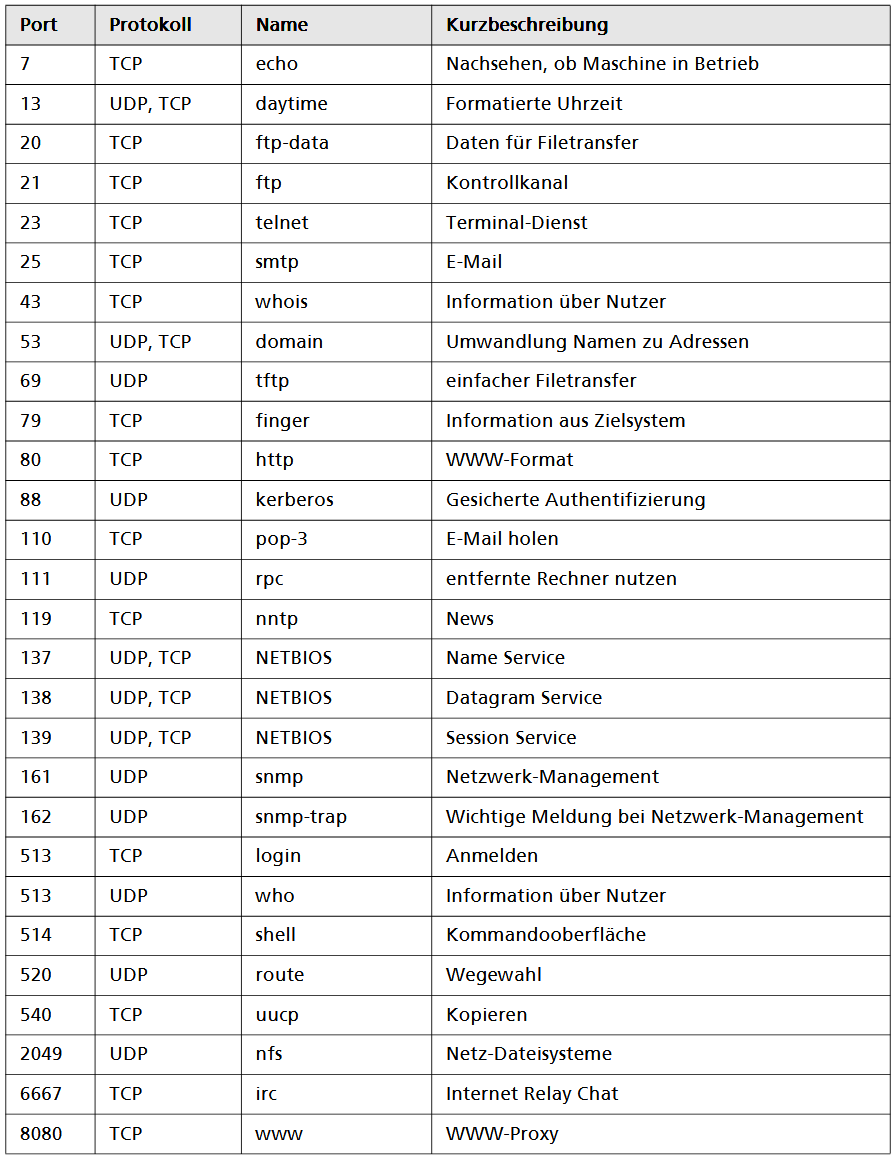
Ports sind Schlüsselzahlen für die Schnittstelle zu Anwendungen oder Diensten.
5. Die Anwendungsschicht
Die Anwendungsschicht stellt die Schnittstelle zwischen Benutzern und den Diensten des Internets dar. Sie ermöglicht Programmen, die grundlegenden Transport- und Netzwerkprotokolle zu nutzen, ohne dass die Anwendung selbst den Datentransport übernehmen muss. Anwendungssoftware legt das Datenformat fest und bestimmt, wie Informationen gespeichert, übertragen und wiedergefunden werden.
Damit unterschiedliche Programme und Hersteller miteinander kommunizieren können, werden Protokolle definiert, die ein einheitliches Interface bereitstellen. Ein Beispiel ist SMTP für E-Mail, das sicherstellt, dass verschiedene E-Mail-Programme Nachrichten austauschen können, ohne speziell aufeinander abgestimmt zu sein.
Beispiele wichtiger Anwendungsprotokolle
- DNS: Übersetzung von IP-Adressen in leicht verständliche Namen
- SSH / TELNET: Fernzugriff auf entfernte Rechner
- SCP, SFTP, FTP: Austausch von Dateien
- SMTP: Versand von E-Mails
- NNTP: Zugriff auf Newsgroups
- WWW (HTTP/HTTPS): Surfen im Web
Das Domain Name System (DNS)
Das DNS (Domain Name System) wurde geschaffen, um Rechnern statt der IP-Adressen auch (sprechende) Namen zuordnen zu können, da Menschen sich diese besser merken können.
In den Anfängen des Internets war die Datei mit der Zuordnung der Rechnernamen zu IP-Adressen noch lokal auf jedem Rechner vorhanden, der mit dem Internet verbunden war. Diese Datei wurde regelmäßig vom NIC (Network Information Center) verschickt
Die Umwandlung der Namen des DNS in IP-Adressen und umgekehrt wird durch eigens dafür vorgesehene Rechner im Internet durchgeführt: den Domain Name Servern.
Als das Internet immer weiter wuchs, ging man dazu über, die Daten in Zonen aufzuteilen und auf Domain Name Servern in einer Datenbank zu verwalten. Jeder Domain Name Server verwaltet nur einen Teil des gesamten Namensraumes (Domain Name Space).
DNS-Namen setzen sich aus einer Hierarchie von Einzelnamen, getrennt durch Punkte,
zusammen. Meist sind es diese drei:
<Rechner>.<Netz>.<TopLevelDomain> z. B. webserver.akad-online.de
Die Top-Level-Domains (TLDs) werden weltweit eindeutig festgelegt. Innerhalb dieser Domains vergeben spezielle Registrierungsstellen die Netznamen oder Subdomains.
Die Zuordnung von Netznamen zu IP-Netzwerken erfolgt zentral, um die Eindeutigkeit im Internet zu sichern. Verantwortlich dafür ist zunächst das InterNIC in den USA, das Domain-Namen zusammen mit IP-Nummern vergibt, die (für Deutschland) vom DENIC in Karlsruhe verwaltet werden. Firmen oder Organisationen wenden sich an das DENIC, um Netznamen in der TLD .de zu reservieren und die passenden IP-Adressen zu erhalten. Innerhalb der eigenen Netze können Administratoren dann Rechnernamen und IP-Adressen frei vergeben.
5.1.2. Top Level Domains
Die oberste Ebene der Internet-Namensstruktur, die Top Level Domains (TLDs), umfasst organisatorische Domains (gTLD) und geografische Domains (ccTLD).
Die zentrale Datenbank der Root Server wird derzeit von NSI verwaltet, wobei der Einfluss der US-Regierung stark ist, da ohne zentrale Root-Server das Internet chaotisch wäre.
Die klassischen gTLDs stammen aus der Anfangszeit des Internets in Nordamerika, inzwischen hat die ICANN weitere gTLDs eingeführt, teils allgemein zugänglich, teils nur für bestimmte Gruppen, oft nach Vorschlägen von Bewerbern mit Lizenzierungsmodellen. Mit der Vielzahl an Endungen wie .com, .biz oder .shop nimmt die Aussagekraft einer Domain ab, obwohl Suchmaschinen dies teilweise ausgleichen.
Generische TLD (gTLDs) werden inzwischen in unsponsored (uTLD) unter direkter ICANN-Kontrolle und sponsored (sTLD) unter Sponsorverwaltung unterteilt, Beispiele sind .museum, .coop, .aero, aber auch .edu und .gov. Außerhalb Nordamerikas dominieren ccTLDs, die auf geografische Codes basieren und Rückschlüsse auf den Standort erlauben; ihre Vergabe erfolgt durch nationale Registrierungsstellen wie das DENIC für Deutschland.
5.1.3. Komponenten des DNS und Namensauflösung
Das Domain Name System (DNS) besteht aus drei Hauptkomponenten: dem Domain Name Space, den Name Servern und den Name Resolvern.
- Der Name Space ist hierarchisch aufgebaut, und die Daten zur Zuordnung von Domain-Namen zu IP-Adressen sind in sogenannten Resource Records gespeichert, die Informationen wie Rechnernamen, IP-Adressen, Aliasnamen oder Mail-Server enthalten.
Name Server verwalten Teile dieses Baums, beantworten Anfragen und nutzen einen Cache, um wiederholte Anfragen schneller zu bedienen.
Name Resolver sind Programme auf Client-Seite, die Anfragen an die zugehörigen Name Server weiterleiten; falls ein Server die Anfrage nicht beantworten kann, werden andere Server kontaktiert.
Bei der Namensauflösung fragt der Client den Resolver, der zunächst lokale Dateien oder den Cache überprüft, bevor die Anfrage an den zuständigen Name Server geschickt wird. Dieser durchsucht ebenfalls seinen Cache und die Datenbank. Findet er keine passende Information, wird die Anfrage an übergeordnete oder benachbarte Name Server weitergeleitet, bis schließlich der Root Server oder der zuständige Endserver erreicht ist, der die IP-Adresse liefert. Die Antwort wird auf demselben Weg zurückgegeben, sodass der Client die Datenpakete korrekt adressieren kann.
Durch den Cache kann die Auflösung beschleunigt werden, jedoch kann dieser auch manipuliert werden, was falsche DNS-Antworten zur Folge hat. Falsch geschriebene oder nicht existierende Adressen verursachen besonders viel Datenverkehr, da die Anfrage viele Hierarchieebenen durchlaufen muss, bevor sie als nicht auffindbar erkannt wird.
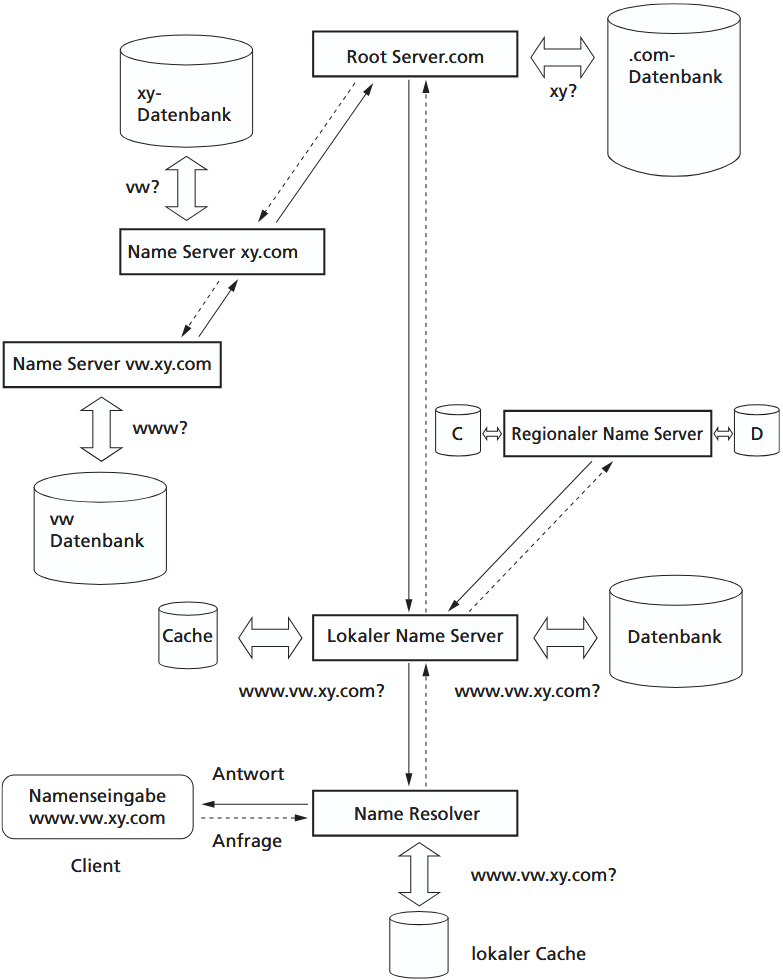
Name Server verwalten Zonen im DNS-Baum, die jeweils einen Knotenpunkt und alle darunterliegenden Domains enthalten. Jeder Server kennt seinen über- und untergeordneten Nachbarn. Aus Sicherheitsgründen gibt es in jeder Zone mindestens zwei Server, einen Primary und einen Secondary, die identische Daten bereitstellen. Für die TLD .de ist der Primary Server bei DENIC in Karlsruhe.
Bei einer Anfrage sucht der Name Server zuerst in seinem Cache nach der zugehörigen IP-Adresse, um Netzverkehr zu reduzieren und die Verbindung zu beschleunigen. Wird dort nichts gefunden, überprüft er seine eigenen Datensätze. Ist der Name auch hier nicht vorhanden, kontaktiert er benachbarte Server oder geht über die Hierarchie nach oben zum Root Server, der den zuständigen Server für die Domain kennt. Die Anfrage wird dann schrittweise nach unten weitergeleitet, bis der zuständige Name Server gefunden ist, der die IP-Adresse liefert. Die Antwort gelangt auf demselben Weg zurück zum Client.
Ein Nachteil dieses Systems ist die Möglichkeit der DNS-Cache-Manipulation, wodurch falsche Daten längere Zeit genutzt werden können. Zudem verursachen falsch geschriebene oder nicht existierende Adressen hohen Datenverkehr, da die Anfrage durch viele Hierarchieebenen geleitet wird, bevor ein Fehler zurückgemeldet wird.
5.2. Zugriff auf entfernte Rechner
5.2.1. Telnet
Telnet (Teletyp Network) ist der erste Dienst, der im Internet eingesetzt wurde. Mit Telnet arbeitet man auf entfernten Rechnern im Internet. Dabei entsteht der Eindruck, der eigene Bildschirm und die Tastatur seien direkt an den entfernten Rechner angeschlossen. Diese Möglichkeit des Anmeldens auf entfernten Rechnern heißt Remote Login. Telnet wird jedoch vorwiegend zur Administration und Konfiguration von Systemen eingesetzt, die über das Internet erreichbar sind.
Das Network Virtual Terminal (NVT) ist ein idealisiertes Terminal, das die Grundlage für die Kommunikation zwischen Client und Server über Telnet bildet. Es definiert grundlegende Regeln und Eigenschaften, wie die Übertragung von Ausgaben, Steuerungscodes für Cursor- oder Bildschirmfunktionen, und ermöglicht so die Verständigung von Rechnern mit unterschiedlichen Architekturen.
Auf Basis des NVT können über das Konzept der aushandelbaren Optionen zusätzliche Funktionen vereinbart werden, die über den Minimalstandard hinausgehen.
Telnet-Verbindungen sind symmetrisch, beide Partner können Optionen oder Parameter aushandeln. Früher wurde Telnet über die Kommandozeile gestartet, heute meist über grafische Clients wie PUTTY, wo Verbindungsparameter komfortabel eingestellt werden. Nach dem Aufbau der Verbindung meldet man sich mit Benutzername und gegebenenfalls Passwort an und kann auf alle zugänglichen Programme und Anwendungen des Servers zugreifen.
Zielsysteme müssen keine klassischen Rechner sein; Telnet-Zugriff ist oft auch auf Routern oder Netzwerkfestplatten möglich, die sonst über Webinterfaces gesteuert werden. Für den Zugriff auf verschiedene Internetdienste muss der passende Port angegeben werden, wodurch Telnet auch den Zugriff auf Dienste wie Gopher oder WWW im Textmodus ermöglicht.
5.2.3. Secure Shell (SSH)
SSH ersetzt Telnet, weil Telnet Daten einschließlich Passwörtern unverschlüsselt überträgt und so leicht abgefangen werden kann.
SSH nutzt dagegen Verschlüsselung und läuft wie Telnet über einen festen Dienst auf Port 22. Grundlage ist eine asymmetrische Authentifizierung: Der Client kennt den öffentlichen Schlüssel des Servers, wodurch sichergestellt wird, dass kein Angreifer sich als Server ausgeben kann.
Der Client weist sich anschließend entweder
- durch ein verschlüsselt übertragenes Passwort
- oder durch ein eigenes Zertifikat aus, dessen öffentlicher Teil auf dem Server hinterlegt ist.
Nach der gegenseitigen Authentifizierung handeln beide Partner einen symmetrischen Schlüssel für die eigentliche Sitzung aus, da diese Verschlüsselungsart deutlich schneller ist. SSH diente ursprünglich nur dem sicheren Login auf entfernten Rechnern, unterstützt heute aber auch zusätzliche sichere Dienste wie SFTP und SCP für verschlüsselten Dateitransfer sowie SSHFS für den Zugriff auf entfernte Dateisysteme
5.3. Übertragung von Dateien
Das File Transfer Protocol (FTP) wird für die Übertragung von Dateien über das Internet genutzt. Anders als in Anhängen von E-Mail-Programmen können mit FTP problemlos auch umfangreiche Dateien transportiert werden.
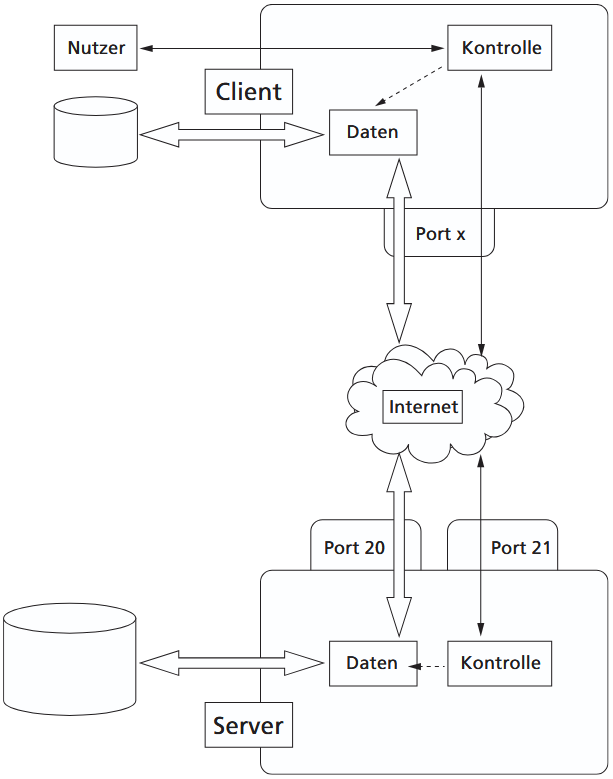
FTP wird zur Übertragung beliebiger Dateien über das Internet genutzt und eignet sich im Gegensatz zu E-Mail-Anhängen auch für sehr große Datenmengen. Das Vorgehen ähnelt einem entfernten Login: Der Client verbindet sich mit einem FTP-Server, meldet sich an, navigiert durch die dortigen Verzeichnisse und lädt Dateien herunter oder hoch. Im Unterschied zu Telnet ist FTP nicht auf Text beschränkt, sondern überträgt beliebige Dateiformate.
FTP arbeitet nach dem Client/Server-Modell und nutzt zwei getrennte Verbindungen:
- Die Kontrollverbindung auf Port 21 dient dauerhaft dem Austausch von Befehlen und Statusmeldungen, während
- die Datenverbindung auf Port 20 für jede Dateiübertragung neu aufgebaut und anschließend wieder beendet wird.
Der Server antwortet mit dreistelligen Codes, über die der Client den Zustand der Sitzung erkennt.
Zusätzlich existiert Anonymous FTP, bei dem man öffentliche Dateien ohne persönliches Konto herunterladen kann. Solche Archive enthalten Milliarden von Dateien, etwa Programme oder Treiber, weshalb Download-Manager oft genutzt werden, um schnelle Server auszuwählen, Verbindungen automatisch fortzusetzen oder große Dateien auf mehrere parallele Downloads aufzuteilen.
FTP-Clients existieren sowohl als textbasierte Tools als auch als grafische Anwendungen, die lokale und entfernte Verzeichnisse nebeneinander anzeigen. Sie können Zugangsdaten speichern und erleichtern so wiederkehrende Anmeldungen.
Ein häufiger Fehler besteht in der falschen Wahl des Übertragungsmodus: Im Binärmodus werden Dateien unverändert übertragen, im ASCII-Modus werden Steuerzeichen wie Zeilenumbrüche an das Zielsystem angepasst. Wird eine Binärdatei versehentlich im ASCII-Modus übertragen, wird sie unbrauchbar.
Da FTP unverschlüsselt ist und sowohl Befehle als auch Passwörter im Klartext sendet, wurden sichere Alternativen entwickelt.
SFTP (Secure FTP) und SCP (Secure Copy Protocol) nutzen SSH, wodurch Authentifizierung und Dateiübertragung verschlüsselt werden.
Während SFTP wie ein vollwertiges Dateitransferprotokoll funktioniert, konzentriert sich SCP auf die reine Dateiübertragung und überlässt den Verbindungsaufbau SSH.
FTP over TLS ist eine weitere sichere Variante, bei der sowohl Steuer- als auch Nutzdaten über eine TLS/SSL-Verbindung geschützt sind.
Die wesentlichen Unterschiede zwischen FTP, SFTP und SCP liegen daher in der Sicherheit und in der Art, wie die Übertragungen technisch aufgebaut werden.
5.4. Das Simple Mail Transfer Protocol (SMTP)
Das Internet stellt einen Dienst zum weltweiten Nachrichtenaustausch zur Verfügung: E-Mail (Electronic Mail). Das Übertragungsproto- koll für E-Mails ist der Internet-Standard SMTP (Simple Mail Transfer Protocol).
Die Verbindung läuft über TCP und Port 25.
Nach einer Mailaufforderung des Benutzers stellt der SMTP-Sender einen ZweiwegÜbertragungskanal zum SMTP-Empfänger her, wobei der SMTP-Empfänger entweder der Zielrechner oder eine Zwischenstation sein kann.
Aufbau einer E-Mail
Das Format einer E-Mail-Nachricht (kurz: Mail) ist in RFC 822 festgelegt. Es besteht aus zwei Teilen: dem Header (Steuerinformationen wie Sender, Empfänger, Datum, Betreff usw.) und dem Body (Inhalt der Nachricht). Der Inhalt der Mail darf nur ASCII-Zeichen (7 Bit!) enthalten. Die Steuerinformationen am Beginn des Textes werden durch Schlüsselwörter identifiziert.
Funktionsweise des E-Mail-Austausches
E-Mail funktioniert nach dem gleichen Prinzip wie die klassische Post, nur dass alle Beteiligten Computer sind. Der Absender erstellt seine Nachricht in einem Mailprogramm, dem sogenannten MUA (Message User Agent), und schickt sie an den zuständigen Mailserver. Dieser Server ist ein MTA (Message Transfer Agent) und übernimmt die Rolle des „Postamts“. Er liest die Adresse der E-Mail aus, findet den richtigen Ziel-MTA und leitet die Nachricht dorthin weiter. Auf dem Zielserver wird die E-Mail in der Mailbox des Empfängers abgelegt.
Eine E-Mail wird also nicht direkt von der Mail-Anwendung (dem E-Mail-Client) über das Netz zum Zielrechner verschickt. Der MTA (Mailserver) speichert zuerst die E-mail im Spoolbereich (Speicherbereich) und legt diese erst dann in die Mailbox des Empfängers.
Die MTAs kommunizieren untereinander mit dem SMTP-Protokoll, weshalb sie auch SMTP-Server genannt werden. Ebenso nutzt der Absender-MUA SMTP, um seine E-Mail an den ersten MTA zu übermitteln. Der Empfänger wiederum holt seine Nachrichten nicht per SMTP ab, sondern verwendet dazu das POP3-Protokoll (Post Office Protocol, Version 3), weshalb der Server, der die Mailboxen verwaltet, POP3-Server heißt. Dieses Zusammenspiel aus MUA, MTA, SMTP und POP3 bildet die technische Grundlage des E-Mail-Verkehrs.
POP und IMAP
POP3 und IMAP4 sind zwei unterschiedliche Methoden, wie ein E-Mail-Client Nachrichten aus dem Postfach auf dem Server abruft.
Bei POP3 lädt der Client die E-Mails vollständig vom Mailserver herunter und speichert sie lokal ab. Sortieren, Filtern und Archivieren finden daher auf dem eigenen Rechner statt. Die Authentifizierung erfolgt beim POP-Server, wird aber in der Praxis oft mit der Anmeldung am SMTP-Server vermischt, weil viele Systeme das Versenden erst erlauben, nachdem per POP ein erfolgreicher Login erfolgt ist. Ein Nachteil von POP3 ist, dass die Mails nach dem Abruf häufig vom Server gelöscht werden – greift man mit mehreren Geräten auf dasselbe Konto zu, sind die Nachrichten daher nicht überall sichtbar, sofern man das Löschen nicht deaktiviert.
IMAP4 arbeitet völlig anders: Die Nachrichten bleiben auf dem Mailserver und werden dort verwaltet. Der Client lädt Inhalte nur temporär herunter, wenn sie angezeigt werden sollen. Das spart Datenvolumen und Zeit, besonders bei großen Anhängen oder langsamen Verbindungen. Zudem können Sortierung, Filterung und das Verwalten von Ordnern direkt auf dem Server erfolgen, sodass man von mehreren Geräten aus stets denselben, synchronisierten Zustand sieht. Der Nachteil von IMAP besteht darin, dass man sich vollständig auf die Datensicherheit und Backups des Providers verlassen muss, da die Mails nicht lokal gespeichert werden.
Webbasierte E-Mail-Dienste
Webbasierte E-Mail-Dienste funktionieren ähnlich wie IMAP: Man greift über den Browser auf das Postfach zu, ohne Nachrichten herunterladen zu müssen. Allerdings ist man auch hier stark von der Sicherheit des Anbieters abhängig, was bei kostenlosen Diensten oft kritischer ist.
Ursprünglich waren E-Mails reine Textnachrichten, doch mit dem Aufkommen des WWW entstand der Wunsch nach ansprechender Formatierung. Heute nutzen viele Clients HTML, um E-Mails mit Farben, Schriftarten, Fett- oder Kursivdarstellung und eingebetteten Bildern zu gestalten.
Bearbeitung einer E-Mail
E-Mail-Clients bieten eine komfortable Oberfläche, die den Nutzer von den Details des zugrunde liegenden SMTP-Protokolls entlastet. Nachrichten werden in Editoren erstellt, Header-Angaben in speziellen Feldern eingegeben, und über Menüs oder Konfigurationsfenster lassen sich zusätzliche Optionen einstellen. Der eigentliche Versand erfolgt im Hintergrund nach den Standards von RFC 822.
Mit diesen Clients lassen sich E-Mails übersichtlich verwalten, beispielsweise automatisch in Ordner sortieren, Dateien anhängen oder persönliche Adressbücher nutzen. Für die Bearbeitung eingehender Nachrichten stehen verschiedene Funktionen zur Verfügung: Forward leitet die Mail an andere Empfänger weiter, wobei der aktuelle Nutzer als Absender erscheint; Redirect leitet ebenfalls weiter, zeigt aber den ursprünglichen Absender an und vermerkt, wer weitergeleitet hat; Reply dient zur Beantwortung einer Mail an den ursprünglichen Absender, wobei das Betrefffeld automatisch mit „Re:“ versehen wird und der Originaltext oft mit einem Quote-Zeichen (>) gekennzeichnet wird; Reply All ermöglicht die Antwort an alle ursprünglichen Empfänger einer Nachricht.
Dateitransfer über E-Mail (Attachments)
E-Mails können neben Text auch Binärdateien wie Bilder oder Programme enthalten, müssen dafür jedoch zunächst in ein 7-Bit-ASCII-kompatibles Format umgewandelt werden, da das ursprüngliche E-Mail-Format nach RFC 822 nur US-ASCII-Zeichen unterstützt. Dies erfolgt automatisch in vielen E-Mail-Clients, die beim Empfang die Daten wieder dekodieren. Für Binärdateien wird häufig das Base64-Verfahren genutzt: Drei 8-Bit-Bytes (24 Bit) werden in vier 6-Bit-Werte zerlegt, die anschließend über eine Codierungstabelle in druckbare ASCII-Zeichen umgewandelt werden. Der Empfänger dekodiert diese Zeichen wieder zurück in die Originaldaten.
Die MIME-Spezifikation (Multipurpose Internet Mail Extensions, RFC 1521–1523), eingeführt 1991, ermöglicht den standardisierten Versand von Nicht-ASCII-Inhalten wie Grafiken, Videos, Audio oder Sonderzeichen in Texten. MIME erweitert den E-Mail-Header um zusätzliche Informationen wie Version, Content-Typ, Codierungsverfahren, Content-ID und eine Kurzbeschreibung. Der E-Mail-Client des Senders erzeugt diese Header automatisch und wandelt den Inhalt in das passende Codierungsformat um, der Empfänger-Client wertet die Informationen aus, dekodiert die Daten und öffnet gegebenenfalls die zugehörige Anwendung zur Darstellung.
Zur Kodierung von Sonderzeichen im Text wird häufig das Quoted-Printable-Verfahren eingesetzt. Dabei werden Zeichen wie Umlaute durch ASCII-Sequenzen ersetzt, die mit einem Gleichheitszeichen beginnen, z. B. wird „ö“ zu =F6 und „ß“ zu =DF. Auch das Gleichheitszeichen selbst wird codiert (=3D). Auf der Empfängerseite werden diese Kodierungen automatisch wieder in die Originalzeichen zurückverwandelt.
Im World Wide Web wird der MIME-Mechanismus genutzt, um den übertragenen Inhalt von Dateien eindeutig zu klassifizieren. Dazu greift jeder Webserver auf die Datei mime.types zurück. Diese Datei ist eine einfache ASCII-Datei, in der in der linken Spalte die Content-Types und gegebenenfalls die Content-Subtypes aufgeführt sind, während in der rechten Spalte die zugehörigen Dateiendungen eingetragen werden. Dadurch kann der Webserver oder der Browser erkennen, um welchen Typ von Datei es sich handelt – etwa Text, Bild, Audio, Video oder ein Dokument.
Der Browser nutzt diese Informationen, um automatisch die passende Anwendung zu starten, mit der die Datei dargestellt oder geöffnet werden kann. Ein typisches Beispiel ist eine PDF-Datei: Erkennt der Browser anhand der Endung oder des MIME-Typs, dass es sich um ein PDF handelt, startet er den Adobe Acrobat Reader oder ein anderes konfiguriertes PDF-Programm, um den Inhalt anzuzeigen. Auf diese Weise wird gewährleistet, dass Dateien korrekt interpretiert werden, unabhängig davon, welches Format sie haben.
5.6. Das World Wide Web (WWW)
Das WWW (World Wide Web), oder kurz: Web (engl. für Geflecht, Netzwerk, Spinnennetz), hat sich zu dem am meisten genutzten Dienst im Internet entwickelt. Das WWW ermöglicht über eine Client-Server-Architektur den Zugriff auf verknüpfte Informationen, die auf Abertausenden von Rechnern überall im Internet verteilt sind.
5.6.1. Dokumente im WWW
Aus Sicht des Benutzers besteht das World Wide Web aus einer riesigen, weltweiten Sammlung von Dokumenten.. Eine einzelne Seite wird als Web-Seite oder Page bezeichnet. Web-Seiten können Links zu anderen Seiten enthalten, die im Internet auf verschiedenen Rechnern gespeichert sind. Über diese Links kann der Nutzer durch Anklicken direkt auf weitere Dokumente zugreifen, wodurch der Browser bei Bedarf automatisch eine Verbindung zum entsprechenden Web-Server herstellt.
Die Grundlage dieser Verknüpfungen bildet Hypertext, also Text mit direkten Querverweisen, der per Mausklick abrufbar ist. Da Web-Dokumente neben Text auch andere Medien enthalten können, spricht man beim WWW von einem Hypermedia-System.
In den 1980er-Jahren entwickelte Tim Berners-Lee am CERN ein Hypertextsystem für den internen Informationsaustausch. 1989 schlug er den Einsatz im Internet vor, und 1990 entstand zusammen mit Robert Cailliau das Konzept für das World Wide Web. Sie definierten die Standards HTML (HyperText Markup Language) für die Dokumentenbeschreibung und HTTP als Transportprotokoll. 1991 wurden die ersten HTML-Dokumente auf CERN-Server geladen, und kurz darauf erschien der erste Browser, der Texte im ASCII-Format darstellen konnte. Mit der Veröffentlichung von NCSA Mosaic 1993 kam der erste grafische Browser auf den Markt, was den endgültigen Durchbruch des WWW ermöglichte. Nun konnten HTML-Dokumente inklusive Bilder dargestellt und per Mausklick auf andere Dokumente zugegriffen werden.
Das Web Browser
Der Browser ist das Programm auf der Client-Seite, das Web-Dokumente abruft, die enthaltenen Formatierungsbefehle interpretiert und die Seite korrekt auf dem Bildschirm darstellt. Web-Seiten enthalten oft verschiedene Elemente wie Text, Grafiken und Links, die der Browser unterscheiden muss. Technisch handelt es sich bei HTML-Dokumenten um Textdateien, in die Tags eingefügt sind, die die Struktur und Formatierung festlegen, beispielsweise Überschriften, Absätze, Tabellen oder Kursivdarstellung.
Damit ein Browser eine Web-Seite aufrufen kann, muss er wissen, wie das Dokument heißt, wo es sich befindet und wie darauf zugegriffen wird. Jedes Dokument erhält daher eine URL (Uniform Resource Locator), die alle dafür nötigen Informationen enthält.
Eine URL hat das Format Protokoll://Rechnername:Port/Dokumentname.
- Das Protokoll, meist HTTP, gibt an, wie auf das Dokument zugegriffen wird;
- der Rechnername ist der DNS-Name des Servers, auf dem sich die Datei befindet;
- die Portnummer ist standardmäßig 80 und kann oft weggelassen werden;
- der Dokumentname enthält Pfad und Dateinamen.
Beispiel: http://www.akad.de/main.asp bezeichnet das HTTP-Protokoll, den Server www.akad.de und die Datei main.asp.
Das Hypertext Transfer Protocol (HTTP)
Die Interaktion zwischen einem Browser und einem Web-Server erfolgt über HTTP (HyperText Transfer Protocol). Es dient zum Transport von WWW-Inhalten und ist sehr einfach gehalten (Zusammenspiel Browser – Web-Server).
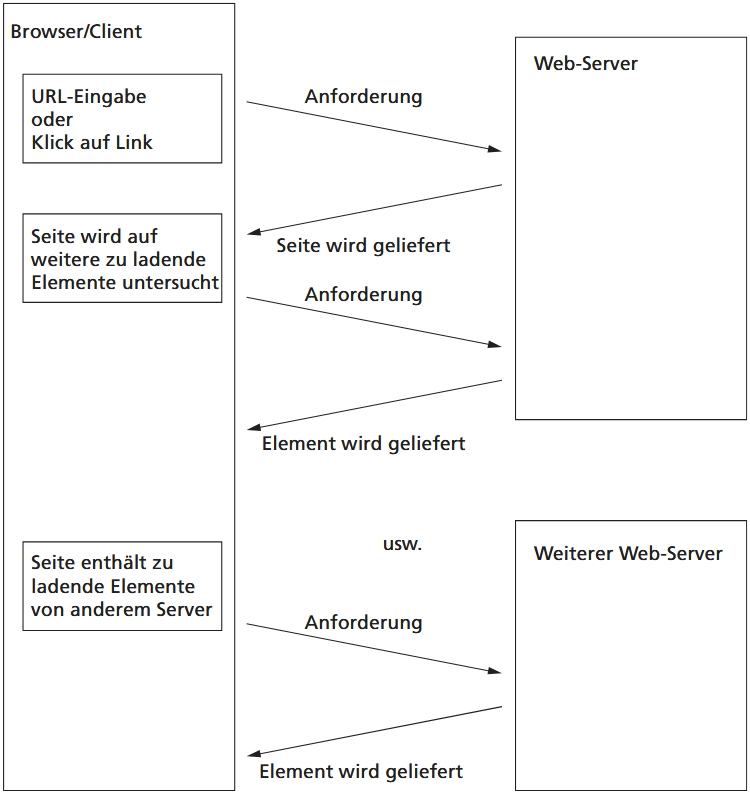
HTTP funktioniert ähnlich wie SMTP, da Client-Anfragen und Server-Antworten als ASCII-codierter Text übertragen werden. Eine HTTP-Verbindung beginnt nach dem Aufbau über TCP (Standard-Port 80) immer mit einer Request-Nachricht des Clients, ausgelöst durch die Eingabe einer URL oder einen Klick auf einen Link. In dieser Nachricht spezifiziert der Client, welche Ressource er vom Server haben möchte. Liefert die Seite weitere Elemente wie Grafiken, Buttons oder Videos, fordert der Client diese separat an; liegen sie auf einem anderen Server, wird eine neue Verbindung aufgebaut, nach der Lieferung wieder geschlossen.
Eine HTTP-Request-Nachricht enthält eine Methode, eine URI (Universal Resource Identifier) und optional Zusatzinformationen. Die URI ist weiter gefasst als die URL, da sie auch URNs (Uniform Resource Name) umfasst, die bei Serverwechseln unverändert bleiben. In der Praxis spricht man jedoch meist nur von URLs. Die wichtigsten HTTP-Methoden sind: GET (Ressource anfordern), HEAD (nur Statusinformationen abfragen), POST (Daten an den Server senden, z. B. Formularinhalte) und PUT (Daten an einem bestimmten Speicherort auf dem Server ablegen).
Serverantworten beginnen stets mit einem Header, der Statusinformationen zum übertragenen Element enthält. HTTP ist ein zustandsloses Protokoll: jede Anforderung wird unabhängig von vorherigen Anfragen behandelt. Zunächst wurde für jedes Element, selbst für kleine Teile einer Seite, eine eigene TCP-Verbindung aufgebaut. Spätere Versionen erlauben das Anfordern mehrerer Elemente über eine einzige Verbindung. Um Informationen zwischen Anfragen zu speichern, werden Cookies eingesetzt, die auf dem Client abgelegt und bei späteren Anfragen zurückgeschickt werden. Dies erleichtert personalisierte Inhalte, birgt jedoch Datenschutzrisiken, etwa wenn Passwörter unverschlüsselt gespeichert werden oder Nutzungsprofile erstellt werden.
Da HTTP standardmäßig unverschlüsselt ist, können Daten von Dritten mitgelesen werden. Besonders bei Funkverbindungen wie ungesicherten WLAN-Hotspots ist daher HTTPS (HTTP Secure) notwendig, das die Daten verschlüsselt und die Identität von Server und Client authentifiziert. HTTPS nutzt SSL/TLS: Zunächst erfolgt ein SSL-Handshake, bei dem die Kommunikationspartner sicher identifiziert werden. Anschließend wird ein symmetrischer Sitzungsschlüssel ausgetauscht, mit dem die Daten verschlüsselt übertragen werden. Eine HTTPS-Verbindung erkennt man an der HTTPS-URL und an Symbolen im Browser, z. B. einem Schloss-Icon oder einer gelb hinterlegten Adresszeile, abhängig vom verwendeten Browser.