(1) Betriebssysteme: Architektur und Funktionsprinzipien
1.1. Überblick und Einordnung
Anforderungen und Aufgaben
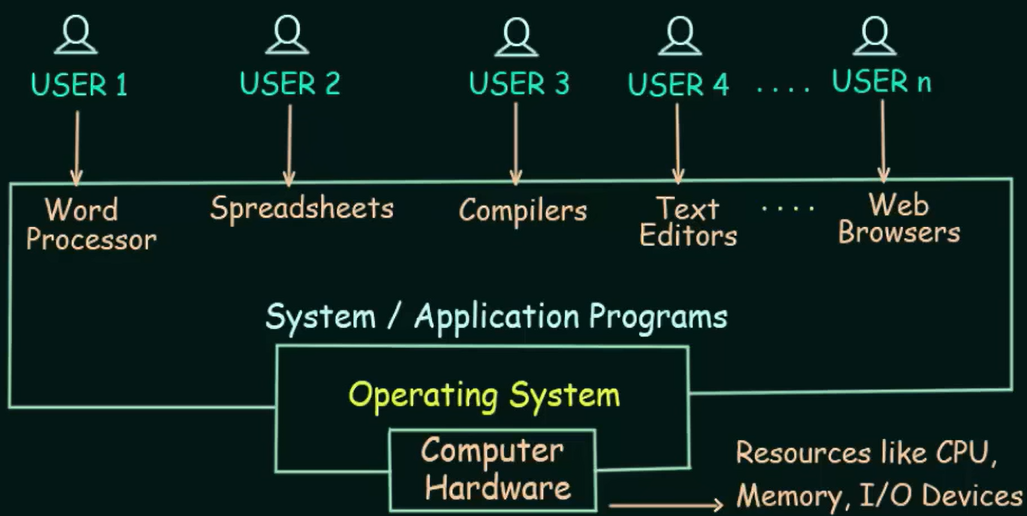
Ein Betriebssystem ist eine Software, die die Ausführung von Programmen steuert und Dienste wie Ressourcenzuweisung, Ablaufplanung, Ein-/Ausgabesteuerung und Datenverwaltung bereitstellen kann (ISO/IEC 2383:15)
Die Hardware reicht allein nicht aus, um darauf effizient Anwendungsprogramme entwickeln, testen und starten zu können. Eine zentrale Aufgabe von Betriebssystemen ist die Steuerung der Programmausführung. Betriebssysteme lösen Fragestellungen wie die folgenden:
- Wie wird ein Programm in den Speicher geladen und gestartet?
- Wie können mehrere Programme gleichzeitig in den Speicher geladen und ausgeführt werden?
- Was passiert nach Beendingung eines Programms oder bei einem Fehler?
Ein Betriebssystem fungiert als Brücke zwischen Hardware und Benutzer. Ein Beispiel ist die Dateiverwaltung. Die Hardware erlaubt das Lesen und Schreiben nur als einzelne Datenblöcke (meistens 512 Byte oder 4KiB). Ein benutzer erwartet aber natürlich, dass man große Datenmengen einfach in Form von Dateien lesen bzw. schreiben kann.
Ein Betriebssystem ist in diesem Sinne ein "Hilfsmittel", beeinflusst aber dadurch auch die Leistungssfähigkeit des gesamten Systems. Es bietet Schnittstellen, mit denen Benutzer arbeiten können, ohne sich mit der Komplexität der Hardware zu beschäftigen. Betriebssysteme gehören zur Systemssoftware.
Betriebssysteme lassen sich klassifizieren nach:
- der Betriebsart (Batch- bzw. Dialogbetrieb, Netzwerk-, Echtzeit- und Universelle Betriebssysteme),
- der Anzahl gleichzeitig verarbeiteter Programme (singletasking, multitasking),
- der Anzahl der gleichzeitig aktiven Nutzer (singleuser, multiuser),
- der Anzahl der verwalteten Prozessoren (singleprocessing, multiprocessing).
Aufgaben des Betriebssystem
Grob lassen sich die Aufgaben eines Betriebssystems in zwei Kategorien aufteilen:
- Optimale Ausnutzung von Ressourcen (z.B. Minimierung des Stromverbrauchs)
- Erfüllung von Nutzeranforderungen (z.B. Beachtung von Echtzeitanforderungen oder intuitive Bedienbarkeit)
Weiter lassen sich folgende Aufgaben feststellen:
- Anpassung der Leistung der Hardware an die Bedürfnisse der Benutzer. Ein Betriebssystem erweitert den Leistungsumfang der Hardware (z.B. Dateiverwaltung) und schützt sie ebenfalls durch Kapselung und Abstraktion (direkter Zugriff auf die Hardware ist unterbunden).
- Organisation und Steuerung des gesamten Betriebsablaufes im System: Arbeitsaufträge (z.B. über die GUI oder Kommandozeile) werden angenommen und die Verarbeitungsschritte eingeleitet (durch Prozesse, Tasks, Threads = "Ausführungseinheiten")
- Verwaltung und ggf. Zuteilung von Ressourcen an verschiedene "Ausführungseinheiten"
- Kontrolle und Durchsetzung von Schutzmaßnahmen, z.B. in Form von Zugriffsrechte für verschiedene Nutzer.
- Protokollierung von relevanten Abläufen im Gesamtsystem
Historie
Die Entwicklung von Betriebssystemen ist eng mit der Computerhardware verknüpft. Ab Ende der 50er-Jahre automatisierten erste Systeme auf Großrechnern die Stapelverarbeitung (Batch Processing), um Nutzeraufträge nacheinander abzuarbeiten. Mitte der 60er-Jahre, insbesondere mit der IBM 360, kam der Mehrprogramm-Betrieb (Multiprogramming) hinzu. Hierbei nutzt das OS Prozessor-Wartezeiten, etwa bei Ein-/Ausgabeoperationen, um andere Jobs zu bearbeiten. Für Mehrbenutzersysteme mit Terminals wurde dies zum Timesharing modifiziert: Das OS verteilt die Prozessorleistung durch zeitliche Verschachtelung auf verschiedene Jobs, um mehrere Nutzer quasi-gleichzeitig zu bedienen.
UNIX: Dennis Ritchie und Ken Thompson
1.2. Architektur von Betriebssystemen
Um Betriebssysteme verstehen zu können, ist es wichtig, sich zunächst anzusehen, aus welchen Komponenten es bestehen und wie diese Komponenten zusammengefügt sind (Architektur).
1.2.1. Entwurf von Betriebssystemen
Beim Entwurf von Betriebssystemen sind mehrere Kriterien zentral, auch wenn in der Praxis oft Kompromisse nötig sind:
-
Modularität und Portierbarkeit: Komponenten sollten modular mit klaren Schnittstellen aufgebaut sein, und das System sollte mit vertretbarem Aufwand auf andere Hardware-Plattformen übertragbar sein.
-
Erweiterbarkeit: Ein Betriebssystem muss leicht erweiterbar sein, um mit dem technischen Fortschritt Schritt zu halten, was auch ökonomisch notwendig ist.
-
Konfigurierbarkeit bzw. Rekonfigurierbarkeit: Einzelne Komponenten müssen sich, möglichst im laufenden Betrieb, anpassen oder austauschen lassen, etwa bei Hardwareänderungen.
-
Skalierbarkeit: Dies bezeichnet die Fähigkeit, das Betriebssystem auf verschiedensten Rechnerplattformen einzusetzen und die Last auf mehrere parallele Prozessoren zu verteilen.
-
Zuverlässigkeit und Fehlertoleranz: Als zentrale Steuerungssoftware muss das Betriebssystem absolut zuverlässig arbeiten, da sonst auch Anwendungsprogramme versagen.
-
Transparenz und Virtualisierung: Das Betriebssystem soll Hardware-Details sowie Ressourcenmängel vor dem Nutzer verbergen und kann Hardware, Speicher oder sogar sich selbst virtualisieren.
1.2.2. Hauptkomponenten
Als "privilegierte Kontrollinstanz" steuert das Betriebssystem das Ablaufgeschehen auf einem Computer und besteht aus folgenden Hauptkomponenten:
-
Kommunikation mit der Umgebung: Diese Komponente regelt den Datenaustausch mit dem Benutzer, der technischen Umgebung und anderen Rechnern.
-
Auftragsverwaltung: Sie ist dafür zuständig, alle ankommenden Aufträge zu registrieren und ihre vollständige Erfüllung zu überwachen.
-
Benutzerverwaltung: Im Mehrnutzer-Betrieb ordnet diese Komponente Aktionen spezifischen Benutzern zu und wehrt damit unerlaubte Zugriffe ab.
-
Prozessverwaltung und -koordinierung: Als zentrale Aufgabe verwaltet sie die laufenden Anwendungsprozesse und steuert deren Ablauf so, dass sie auch bei Konflikten fehlerfrei funktionieren.
-
Betriebsmittelverwaltung: Sie verwaltet alle von Prozessen benötigten Hard- und Software-Ressourcen, um eine "ungestörte" Nutzung zu garantieren.
-
Hauptspeicherverwaltung: Aufgrund ihrer Komplexität wird die Verwaltung des Arbeitsspeichers oft als eigene Komponente behandelt, obwohl sie eigentlich zur Betriebsmittelverwaltung gehört.
-
Ein-/Ausgabesystem: Diese Komponente kümmert sich um alle technischen Details der Daten-Ein- und Ausgabe, sodass der Benutzer diese nicht kennen muss.
-
Dateiverwaltung: Sie übernimmt alle Aufgaben zur sicheren Speicherung und transparenten Verwaltung von größeren, logisch zusammenhängenden Datenmengen.
1.2.3. Architekturmodelle
1.2.3.1. Monolitische und Kern-Schale-Architektur
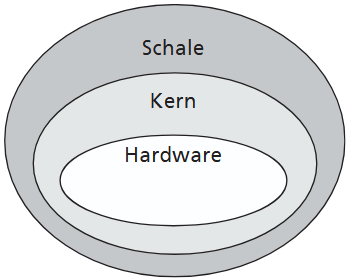
Die einfachste und älsteste "Bauweise" für Betriebssysteme ist die monolitische Architektur. Alle wichtigen Bestandsteile des Betriebssystem sind als einzelne Funktionen in einem großen Block gesammelt. Alle Funktionen könnnen bei Bedarf auf die Diente anderer Funktionen zugreifen: jede Funktion ist von außen offen sichtbar. Obwohl man selbst mit dieser Architektur ein Betriebssystem effizient programmieren kann, sind Änderungen und Erweiterungen sehr aufwendig.
Aus diesem Grund wurde in den 1970er diese Struktur aufgeteilt: Es entstand der kernel und die shell. Der kernel übernimmt die "lebenswichtigen" und hardwareabhängigen Komponenten des Systems (Prozessorverwaltung, Speicherverwaltung usw.) und die shell übernimmt alle anderen Komponenten (z.B. Benutzerkommunikation, Ein-/Ausgabe-Umleitung).
OS/360 von IBM oder Multics waren in den 1960er monolithische Betriebssysteme. Als Reaktion auf die Komplexität von Multics fingen Dennis Ritchie und Ken Thompson mit UNIX 1969 an, die kernel-shell-Architektur zu entwickeln.
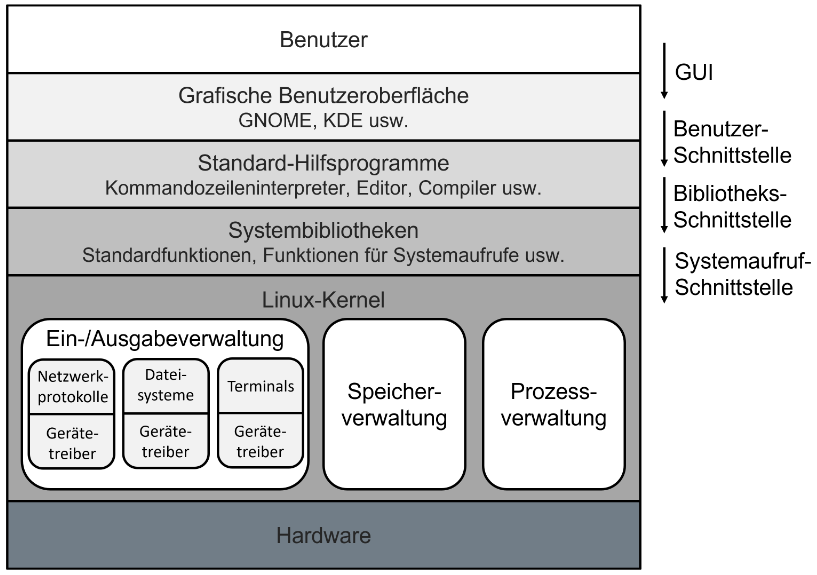
1.2.3.2. Hierarchische Mehrschichtenarchitektur
Als Weiterentwicklung der Kern-Schale-Architektur werden Betriebssysteme oft in hierarchische Schichten gegliedert, um eine klarere Struktur zu schaffen. Die einzelnen Schichten sind durch definierte Schnittstellen voneinander abgegrenzt und funktionieren nach dem Black-Box-Prinzip, was ihre Austauschbarkeit erleichtert. In dieser Hierarchie bietet jede Schicht der nächsthöheren Schicht ihre Dienste an und nutzt selbst die Funktionen der darunterliegenden, wobei die unterste Schicht auf der Hardware aufsetzt und die oberste die Benutzerschnittstelle bildet.
Bei einer konsistenten Schichtung sind Interaktionen nur zwischen direkt benachbarten Schichten erlaubt. Dies vereinfacht die Wartung erheblich, kann jedoch zu Verzögerungen führen, wenn Anfragen unnötig viele Zwischenschichten passieren müssen.
Deshalb nutzten ältere Systeme oft eine quasi-konsistente Schichtung, die das Überspringen von Schichten erlaubte. Dies kann jedoch zu unkontrollierbaren Abläufen führen. Neuere Betriebssysteme verhindern aus Sicherheitsgründen zumindest den direkten Hardwarezugriff durch Anwendungen, indem sie die Hardwareschicht vollständig abschirmen. Das Schichtenmodell dient dank klarer Schnittstellen auch als geeigneter Ansatz für die modulare Implementierung des Systems.
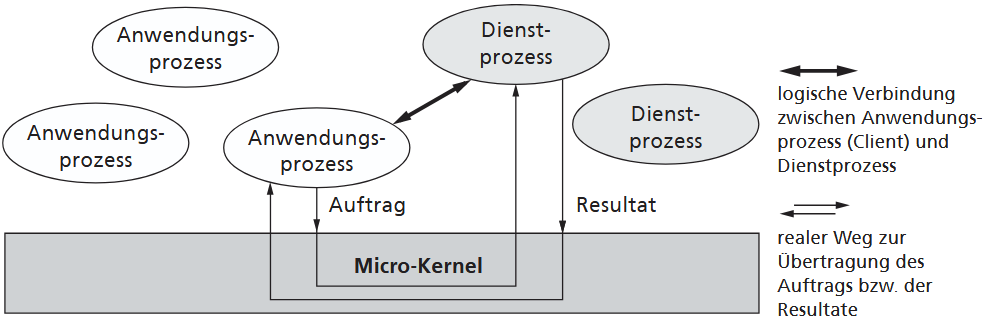
1.2.3.3. Micro kernel Architektur
Die Mikrokern-Architektur reduziert den Kernel auf unbedingt nötige Basisfunktionen, um ihn kleiner und effizienter zu gestalten. Dieser "Mikrokern" enthält nur die wichtigsten hardwareabhängigen Teile und Grundfunktionen für den Datenaustausch. Alle weiteren Betriebssystemleistungen werden von eigenständigen Dienstprozessen außerhalb dieses Kerns erbracht. Diese Modularität macht das System sehr flexibel, da die Dienste einfach modifizierbar oder austauschbar sind.
Das Zusammenspiel basiert auf dem Client-Server-Modell, bei dem Anwendungsprozesse (Clients) logische Verbindungen zu den Dienstprozessen (Servern) aufbauen, um Aufträge zu übermitteln. Der Mikrokern stellt hierfür die erforderlichen Kommunikationsmittel bereit und steuert den Austausch. Durch diese Eigenständigkeit der Dienste wird das System übersichtlicher, anpassbarer und robuster, da Fehler in einem Dienstprozess meist nicht zum Absturz des Gesamtsystems führen.
Mikrokern-Systeme eignen sich gut für verteilte Systeme, da nicht das komplette Betriebssystem installiert werden muss. Ein frühes Beispiel ist der MACH-Kernel, der als UNIX-kompatible Basis diente und Konzepte für heutige Systeme wie macOS und iOS lieferte. In der Praxis existieren auch hybride Konzepte, sogenannte Hybridkerne, die versuchen, die Vorteile von Mikrokerneln und monolithischen Kerneln zu vereinen.
1.2.4 Betriebssystem-Schnittstellen
1.2.4.1 Benutzerschnittstellen
Die Benutzerschnittstelle ist eine Anwendung, die Befehle entgegennimmt und zur Ausführung an den Betriebssystemkern weiterleitet. Sie kann grafik- oder textbasiert sein, aber auch andere Formen wie Sprachsteuerung annehmen.
Kommandosprachen (Texteingabe) erlauben komplexe, platzsparende Operationen, sind aber oft schwer erlernbar und fehleranfällig. Sie ermöglichen die Automatisierung von Abläufen durch Kommandofolgen, sogenannte Shell-Skripts.
Grafische Benutzungsoberflächen (GUIs) nutzen grafische Eingabegeräte und die Fenster-Technik, um den Bildschirm in virtuelle Bereiche zu teilen und ein Desktop-Modell mit Symbolen umzusetzen. Dies erlaubt eine intuitive Bedienung. Ein "Window-Manager" steuert dabei das Aussehen und Verhalten der Fenster (look & feel).
Während Kommando-Interpreter (CLI) Grundbestandteil sind, stellen GUIs mächtige Komponenten dar. Ihre Implementierung variiert: Manche Systeme integrieren die GUI fest, während flexible Systeme sie austauschbar halten. Mobile Geräte nutzen ebenfalls GUIs, die jedoch für Touch-Eingaben und Ganzseiten-Apps optimiert sind.
1.2.4.2 Programmierschnittstellen
Die Programmierschnittstelle (API) definiert verbindlich die Syntax und Semantik der Betriebssystemfunktionen, die Programmierer als Systemdienste oder Systemaufrufe nutzen können. Diese Dienste werden in oft standardisierten Funktions- oder Methodenbibliotheken für die jeweilige Programmierumgebung bereitgestellt.
Auch die Funktionen einer grafischen Benutzungsoberfläche sind in einer GUI-Schnittstelle zusammengefasst und können von Anwendungen über die API angesprochen werden, um Programme grafisch bedienbar zu machen.
1.3. Prozesse
Frühe Rechner ab den 1950er Jahren waren große Batch-Systeme, die Jobs ausführten. Später kamen die ersten Time-Sharing-Systeme, bei denen sich mehrere Nutzer über sogenannte Terminals die Rechenleistung quasi-gleichzeitig teilten und über Shells Programme und Tasks ausführten. Manchmal wird der Begriff "Job" als Synonym zu "Prozess" verwendet, obwohl letzter der modernere, korrektere Begriff ist und streng genommen Unterschiede zwischen den Begriffen bestehen.
Vereinfacht gesagt ist ein Prozess ein ausführendes Programm. Der Status der aktuellen Aktivität eines Prozesses wird durch den Wert des Befehlszählers (Program Counter - ein spezieller Speicherplatz in der CPU, der immer die Adresse des nächsten Befehls enthält) und den Inhalt der Prozessor-Register dargestellt.
Im Speicher sieht der Prozess folgendermaßen aus:
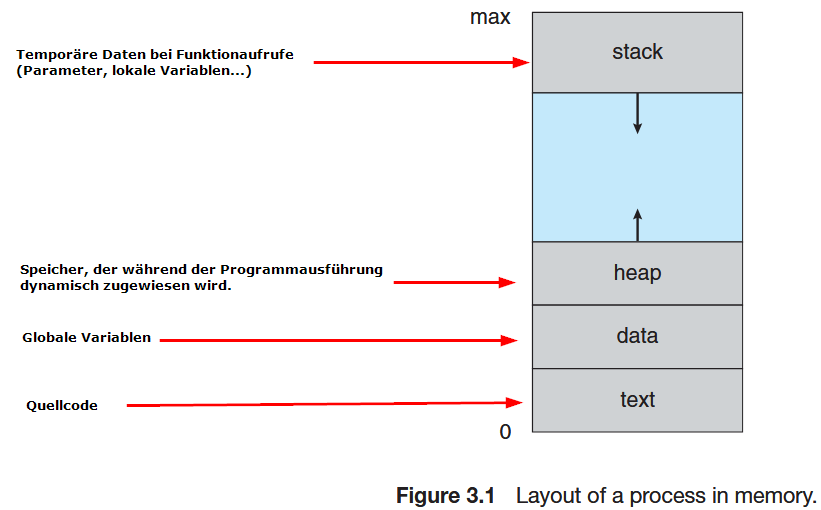
Während Text- und Datenbereiche eine feste Größe haben, können Stack und Heap zur Laufzeit dynamisch wachsen und schrumpfen, wobei bei jedem Funktionsaufruf ein Aktivierungsblock (activation record) mit Parametern, lokalen Variablen und die return address auf den Stack gelegt wird. Wenn die Funktion die Steuerung abgibt, wird der Aktivierungsblock wieder vom Stack entfernt (popped).
1.3.1. Auftrag -> Prozess -> Programm
Betriebssysteme nehmen Arbeitsaufträge von Benutzern oder der Umgebung entgegen, die als Auslöser für einen Arbeitsvorgang dienen. Um einen Auftrag auszuführen, wird ein Programm benötigt, das zuvor von einem Entwickler als Lösung für eine Aufgabe implementiert wurde. Ein Programm selbst ist jedoch lediglich eine statische, unveränderliche Einheit – eine Folge von Anweisungen und Daten, die meist als Datei gespeichert ist. Diese Sichtweise ist wichtig, da ein Programm die Grundlage für mehrere parallele Abläufe sein kann, aber nicht der Ablauf selbst ist.
Um die Lücke zwischen dem statischen Programm und dem auszuführenden Auftrag zu schließen, wurde der Begriff des Prozesses eingeführt. Ein Prozess ist das dynamische Objekt, das den wirklichen zeitlichen Ablauf und den Verarbeitungsfortschritt repräsentiert. Er ist der eigentliche "Aktivitätsträger" des Systems.
Definiert wird der Prozess als eine dynamische Folge von Aktionen und Zustandsänderungen, die durch die Ausführung eines Programms auf einem Prozessor entstehen. Ein Prozess ist daher maßgeblich durch seinen zeitlich veränderbaren Zustand charakterisiert, der sich hardwarenah oder anwendungsnah zeigen kann.
Der Zusammenhang zwischen den drei Begriffen ist klar definiert: Ein Auftrag veranlasst das Betriebssystem, einen Prozess einzurichten. Dieser Prozess dient der Erfüllung des Auftrags. Das Betriebssystem muss das zugehörige Programm kennen und dem Prozess zuordnen, damit dieser die notwendigen Aktionen ausführen kann. Dieses Modell erlaubt es, dass ein einzelnes Programm mehreren Prozessen gleichzeitig zugeordnet wird, um verschiedene Aufträge Die Zustandsänderungen dieser Prozesse lassen sich dabei auf zwei Ebenen beobachten: hardwarenah (z.B. als Änderung von CPU-Registern oder Speicherzellen) und aus der Benutzerperspektive (z.B. als Text, der sichtbar auf dem Bildschirm erscheint).
Ein Beispiel von zwei Prozessen können zwei getrennte Fenster sein, in denen zwei unterschiedliche Webseiten angezeigt werden. Obwohl das Browser-Programm nur einmal installiert ist, erzeugt das Betriebssystem für die Anzeige von zwei verschiedenen Webseiten in separaten Fenstern zwei eigenständige Prozesse.

1.3.2. Parallele Prozesse
In Multitasking-Betriebssystemen existieren viele Prozesse gleichzeitig, was als System paralleler Prozesse bezeichnet wird. Diese Parallelität bezieht sich jedoch nur auf die Existenz, nicht zwingend auf die Ausführung. Echte Parallelität (Multiprocessing) erfordert mehrere Prozessorkerne. Auf einem einkernigen Prozessor-System wird stattdessen durch Quasi-Parallelität (Nebenläufigkeit) eine zeitlich verschachtelte Abarbeitung realisiert, wodurch das Betriebssystem dem Nutzer eine Parallelität vorspiegelt, die die Hardware nicht bietet.
Die Prozessverwaltung steuert dabei sowohl Anwendungsprozesse (Benutzermodus) als auch Systemprozesse. Der Benutzermodus (user mode) verbietet privilegierte Befehle. Für Kernfunktionen wechselt ein Prozess – ausgelöst durch Systemaufrufe oder Interrupts in den Systemmodus (kernel mode). Dieser Wechsel wird aus Sicherheitsgründen hardwarenah überwacht, da im Kernel-Modus Schutzmechanismen zur Effizienzsteigerung oft abgeschaltet sind; die Rückkehr in den Benutzermodus erfolgt automatisch.
Die zentrale Herausforderung des Betriebssystems ist es, eine geeignete zeitliche Verschachtelung für den Ablauf der Prozesse zu finden. Das Verfahren zur Auswahl, welcher Prozess als Nächstes den Prozessor zugeteilt bekommt, um voranzuschreiten, wird als Scheduling (Ablaufplanung) bezeichnet.
1.3.3. Prozesszustände
Da maximal nur so viele Prozesse gleichzeitig voranschreiten können, wie Prozessorkerne vorhanden sind, muss die Prozessverwaltung den Zustand aller existierenden Prozesse über ein Prozesszustandsmodell kennen. Dieses Modell beschreibt die Grundzustände:
- neu (new), wenn der Prozess erzeugt wird
- aktiv (running), wenn der Prozess gerade auf einem Prozessor ausgeführt wird;
- bereit (ready), wenn der Prozess lauffähig ist, aber nur auf die Zuteilung des Prozessors wartet;
- wartend (waiting), wenn er auf ein externes Ereignis wie eine Dateneingabe warten muss.
Der Zustand nicht existent ist formell für Prozesse vor der Erzeugung oder nach der Beendigung. Auf einem inzelprozessorsystem kann nur ein Prozess aktiv sein, während viele andere bereit oder wartend sind.
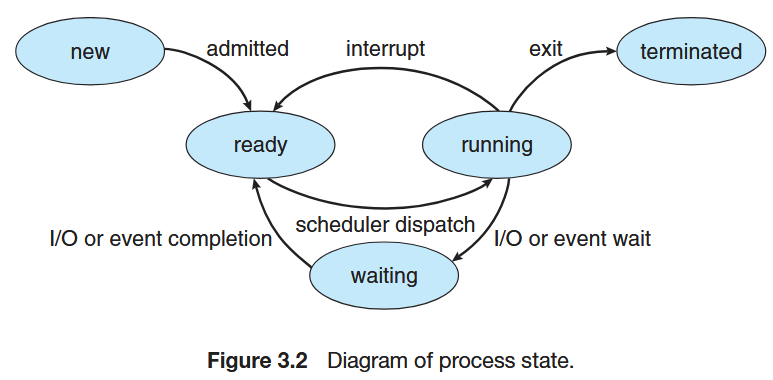
Zustandsübergänge
Die Zustandsübergänge werden teilweise vom Prozess selbst, meist aber vom Betriebssystem ausgelöst. Ein Prozess wechselt selbst von aktiv nach wartend, wenn er eine Wartebedingung (z.B. E/A) anstößt oder gibt den Prozessor freiwillig ab (aktiv → bereit). Das Betriebssystem (der Scheduler) steuert jedoch die Zuteilung des Prozessors: Es wählt einen Prozess aus (bereit → aktiv) oder entzieht ihm den Prozessor (aktiv → bereit). Ein wartender Prozess kann sich nicht selbst befreien; er wird extern in den Zustand bereit überführt, sobald seine Wartebedingung erfüllt ist.
Der Lebenszyklus beginnt mit der Erzeugung (nicht existent → bereit) und endet mit der Beendigung (aktiv → nicht existent) oder dem Abbruch (bereit/wartend → nicht existent). All diese Übergänge werden durch effiziente, gesicherte interne Funktionen des Betriebssystemkerns ausgeführt, die für Programmierer nicht direkt zugänglich sind, sondern in Systemdiensten gekapselt sind.
1.3.4. Prozesskontext / Prozessbeschreibung
Während ein Prozess für den Benutzer primär als Anwendung erscheint, benötigt das Betriebssystem zu seiner Verwaltung den gesamten Kontext, der ihn eindeutig charakterisiert.
Definition
Der Kontext eines Prozesses enthält alle zu seiner Existenz und Verwaltung im Betriebssystem erforderlichen Informationen und charakterisiert ihn daher eindeutig und vollständig.
Dieser Kontext besteht aus drei Teilen:
- dem Benutzer-Kontext, der den (virtuellen) Adressraum des Prozesses (Code, Daten, Stack) umfasst und als Schutzhülle dient;
- dem Hardware-Kontext (Register-Kontext), der alle aktuellen Informationen im Prozessor wie Befehlszeiger und Registerinhalte speichert;
- dem System-Kontext mit allen reinen Verwaltungsinformationen.
Der System-Kontext ist der aufwendigste Teil und wird logisch in einer Datenstruktur zusammengefasst, die als Process Control Block (PCB) bezeichnet wird. Der PCB dient als zentrales Repository für alle Informationen, die nötig sind, um einen Prozess zu starten oder nach einer Unterbrechung exakt fortzusetzen. Dazu gehören:
- Prozess-Identifikation: Eindeutige PID.
- Aktueller Zustand: Z. B. neu, bereit, laufend, wartend oder angehalten.
- Hardware-Kontext: Der Program Counter (Adresse des nächsten Befehls) sowie die Inhalte der CPU-Register (z. B. Stack-Pointer, Allzweckregister), die bei einem Interrupt gesichert werden müssen.
- Scheduling-Informationen: Priorität des Prozesses und Zeiger auf Warteschlangen.
- Speicher-Management: Infos zu Speicherbegrenzungen (Basis-/Limit-Register) sowie Seiten- oder Segmenttabellen.
- Buchführung & E/A: Nutzung der CPU-Zeit, Zeitlimits sowie eine Liste der zugewiesenen E/A-Geräte und geöffneten Dateien.

Zur Organisation der Prozesse und ihrer Zustände nutzt das Betriebssystem oft verkettete Listen. Es existieren typischerweise eine Liste für alle bereiten Prozesse (ready list) und Listen für wartende Prozesse.
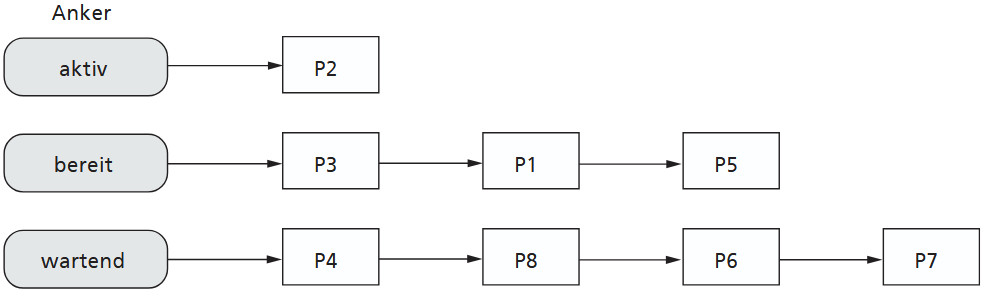
Die Zustandsübergänge eines Prozesses, etwa von "aktiv" zu "bereit", werden dann effizient implementiert, indem der PCB des Prozesses einfach aus einer Liste ausgekettet und in die andere eingekettet wird. Die Sortierstrategie dieser Listen, beispielsweise nach Priorität, beeinflusst direkt die Effizienz des Schedulings.
1.3.5. Prozesswechsel
Eine Änderung der Prozessorzuteilung wird als Prozessumschaltung (task switch) bezeichnet und bedeutet einen Wechsel des aktiven Prozesses. Dieser Wechsel wird ausgelöst, wenn ein Prozess den Prozessor freiwillig abgibt (z.B. bei Beendigung oder Warten) oder wenn das Betriebssystem ihm diesen entzieht (z.B. bei abgelaufener Zeit oder höherprioren Aufgaben). Während der Scheduler anhand einer Strategie entscheidet, welcher laufbereite Prozess als Nächstes dran ist, führt der Dispatcher als spezielle Komponente des Betriebssystemkerns die eigentliche Umschaltung durch. Diese Prozesswechsel können nur nach einer Unterbrechung des laufenden Betriebs stattfinden, etwa durch einen Hardware-Interrupt oder einen Systemdienstaufruf (Trap) durch den Prozess selbst.
Aus der Sicht eines Benutzers entsteht durch diese zeitlich verschachtelte Abarbeitung die Illusion der Gleichzeitigkeit (Quasi-Parallelität oder Nebenläufigkeit), als würden alle seine Prozesse ungestört und parallel ablaufen, auch wenn sich das System bei hoher Last insgesamt verlangsamt. Aus Sicht des Betriebssystems und der Hardware ist dies jedoch eine Abstraktion: Auf einem einzelnen Prozessorkern wird zu jedem Zeitpunkt immer nur ein einziger Prozess "echt" ausgeführt. Das Betriebssystem selbst benötigt für diese Steuerung und die Prozesswechsel ebenfalls CPU-Zeit, die dann den Anwendungsprozessen nicht zur Verfügung steht.
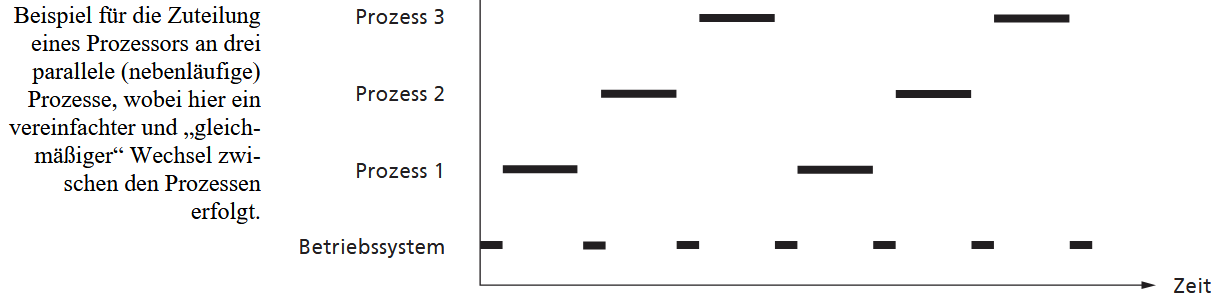
Die zentrale Anforderung an die Prozessverwaltung ist, dass ein Prozess durch die meist unvorhersehbare Unterbrechung nicht "beschädigt" werden darf und den Wechsel idealerweise gar nicht bemerkt. Um dies zu gewährleisten, muss der Prozess exakt an der Stelle und in dem Zustand fortgesetzt werden können, an dem er unterbrochen wurde. Das Betriebssystem muss den Prozess daher "einfrieren", indem es alle für ihn relevanten Informationen sichert. Diese Sammlung von Informationen ist der Prozess-Kontext. Ein Prozesswechsel ist daher immer ein Kontext-Wechsel (context switch): Der Dispatcher muss den kompletten Kontext des alten Prozesses sichern und den gesicherten Kontext des neuen Prozesses laden. Da Unterbrechungen auch verschachtelt auftreten können, müssen diese Kontexte stapelbar verwaltet werden. Ein Hauptziel beim Betriebssystementwurf ist es, diese Umschaltzeit (context switch time) so gering wie möglich zu halten.
1.4. Systemdienste
1.4.1. Systemaufrufe und Kontextwechsel
Systemdienste werden Programmierern über eine API als gekapselte Unterprogramme angeboten. Der Aufruf eines Systemdienstes löst einen Unterbrechungsmechanismus aus, wodurch das Betriebssystem die Steuerung erhält und ein sofortiger Wechsel vom Benutzermodus in den Systemmodus stattfindet. Um die spätere Fortsetzbarkeit des aufrufenden Prozesses zu garantieren, muss der Kontext des aufrufenden Prozesses gesichert werden, bevor der Dienst bearbeitet wird. Der Prozess wird währenddessen vorübergehend in den Zustand "bereit" oder "wartend" überführt.
Nachdem das Betriebssystem den Dienst erbracht hat, wählt der Scheduler den am besten geeigneten Prozess aus der Menge der laufbereiten aus – dies ist nicht zwangsläufig der aufrufende Prozess. Mit der Wiederherstellung des Kontexts des ausgewählten Prozesses wird dessen Bearbeitung fortgesetzt, was automatisch den Wechsel zurück in den Benutzermodus bewirkt.
Diese Mechanik führt dazu, dass Programmierer keine Annahmen über den zeitlichen Ablauf ihrer Prozesse treffen können, da diese nach Systemaufrufen verzögert werden können. Um sicherzustellen, dass der privilegierte Systemmodus stets schnell verlassen werden kann, halten Betriebssysteme oft einen Leerlaufprozess (idle task) bereit. Dieser Prozess wird nur dann aktiviert, wenn kein anderer Anwendungsprozess lauffähig ist, um die Wartezeit zu überbrücken und ein "aktiv warten" (busy waiting) des Betriebssystems zu verhindern.
1.4.2. Nebenläufigkeit bei Systemdiensten
Um die Datenkonsistenz bei kritischen Abläufen im Systemmodus zu wahren, etwa bei Listenoperationen, müssen Unterbrechungen verhindert werden. Dies geschieht mittels Kernsperren.
- Eine vollständige Kernsperre schützt den gesamten Kern, was einfach, aber unproduktiv ist und bei Wartezuständen zu Problemen führen kann.
- Teilweise Kernsperren: Hier werden nur bestimmte Teilabschnitte vor Unterbrechungen geschützt.
- Alternativ wird es auf Sperren verzichtet, was wiedereintrittsfähige (reentrant) Programmierung erfordert.
Die Dauer der Sperren ist entscheidend für die Echtzeitfähigkeit, da lange Sperren die Reaktionszeit des Systems verzögern.
Systemdienste können zudem unterschiedlich implementiert werden. Beim traditionellen prozedurorientierten Ansatz wird der Dienst effizient, aber unflexibel, komplett im Kernel (Systemmodus) ausgeführt. Moderne Mikrokern-Architekturen nutzen einen prozessorientierten Ansatz (Client-Server-Modell). Hier wird der Dienst von einem eigenständigen Serverprozess außerhalb des Kerns erbracht. Dies ist sehr flexibel, da Dienste ohne Kernänderung austauschbar sind, und unterstützt die Verteilung auf andere Rechner.
1.4.3. Multiprozessoren und Parallelverarbeitung
Durch der Einzug von Mehrkernprozessoren ist die Unterstützung von echter Parallelverarbeitung durch das Betriebssystem enorm wichtig geworden. Eine simple vollständige Kernsperre ist hierfür ungeeignet, da sie die Leistung einschränkt, indem sie verhindert, dass mehrere Prozessoren gleichzeitig im Kernel-Modus arbeiten. Moderne Systeme müssen daher skalierbar sein und eine feingranulare Architektur an Sperren aufweisen. Diese erlaubt, dass sich mehrere Prozesse auf unterschiedlichen CPUs gleichzeitig im Betriebssystemkern befinden dürfen, solange sie nur auf verschiedene, einzeln geschützte Datenstrukturen zugreifen. Heutige Universalbetriebssysteme nutzen solche "Multithreaded-Kerne".
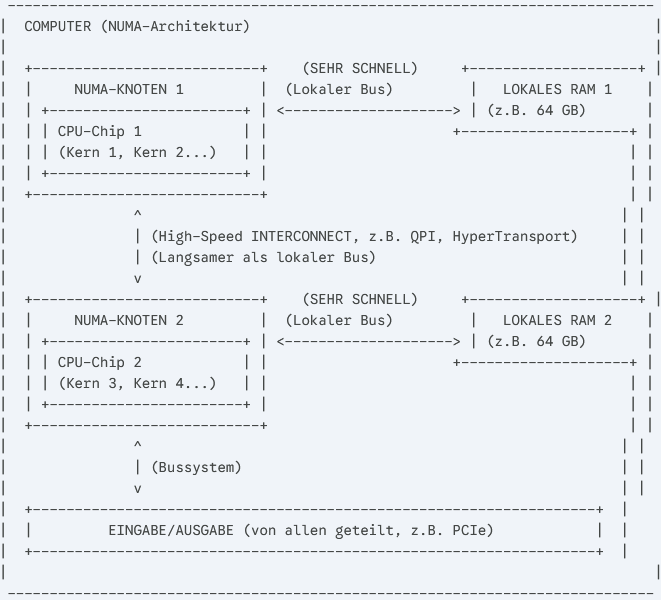
Ein weiterer Aspekt moderner Parallelverarbeitung ist Heterogenität, insbesondere bei NUMA-Architekturen (Non-Uniform Memory Access). Bei NUMA haben CPUs eigenen lokalen Arbeitsspeicher, der deutlich schneller ist als der Zugriff auf den Speicher anderer CPUs im gemeinsamen Adressraum. Das Betriebssystem muss diese Affinität (Zuordnung von Speicher zu CPUs) berücksichtigen und Prozesse möglichst auf der CPU ausführen, die lokal auf die benötigten Daten zugreifen kann.
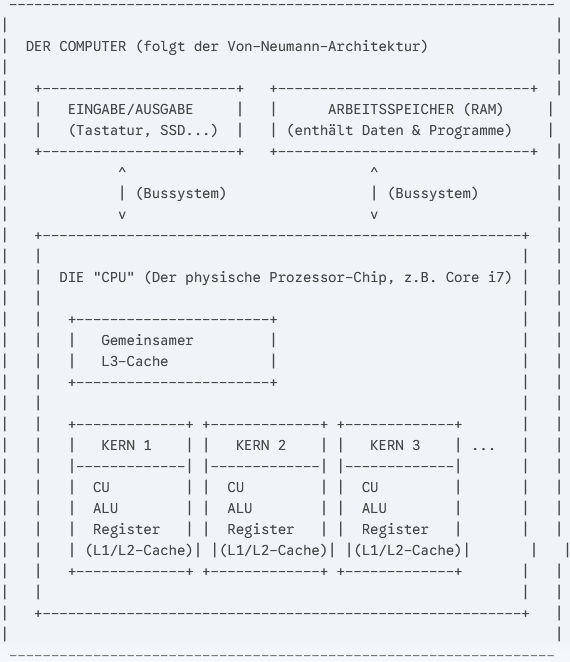
Zur Einordnung, die Von-Neumann-Architektur:
NUMA-Architektur (jeder Kern hat seinen eigenen RAM)
Einen Schritt weiter gehen Multikernel-Betriebssysteme. Sie behandeln die CPUs eines Systems wie ein Netzwerk unabhängiger Kerne (ein verteiltes System). Statt impliziter Zugriffe auf geteilten Speicher erfolgt der Datenaustausch hier explizit über Nachrichtenaustausch (Message Passing). Diese strikte Isolation der Adressräume zielt darauf ab, die Komplexität zu reduzieren und die Skalierbarkeit weiter zu verbessern.
-
QPI/HyperTransport (Hardware): Das ist die physische Verbindung zwischen den Prozessoren (die "Interconnects" aus dem NUMA-Schema).
-
Message Passing (Software): Das ist das Kommunikationsprotokoll, das die Software (das Betriebssystem) auf dieser Autobahn spricht.
1.4.4. Systemdienste zur Prozessverwaltung
Programmierer nutzen API-Systemdienste, um Prozesse zu verwalten, wobei sich die Funktionen je nach Betriebssystem stark unterscheiden. Die Prozesserzeugung ist ein aufwendiger Vorgang, bei dem das OS eine PID (IDENTIFIKATOR) vergibt, einen PCB anlegt und Ressourcen reserviert. Bei Windows erledigt CreateProcess() Erzeugung und Laden in einem Schritt. UNIX/Linux nutzt einen zweistufigen Ansatz: fork() erzeugt zunächst einen Klon des Elternprozesses; dieser Klon muss anschließend explizit ein neues Programm über exec() laden.
Die Beendigung eines Prozesses muss dem Betriebssystem ebenfalls explizit per Systemdienst mitgeteilt werden, etwa mittels ExitProcess() (Win32) oder exit() (UNIX/Linux). Nur so kann das Betriebssystem den Prozess austragen und alle "ausgeliehenen" Ressourcen wieder "einsammeln", um ein "Aushungern" des Systems zu verhindern. Es existieren Dienste zur Eigen- und Fremdterminierung sowie zur dynamischen Änderung von Eigenschaften, wie SetPriorityClass() bei Windows zur Anpassung der Priorität.
1.4.5. Threads
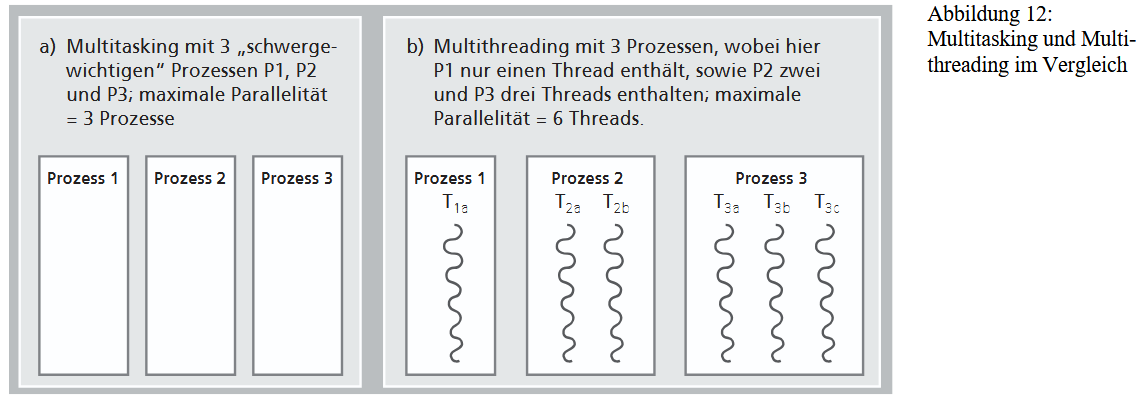
Die Verwaltung von Prozessen, insbesondere der Kontextwechsel, verursacht wegen des großen Umfangs des Kontextes einen erheblichen Aufwand. Um diese Belastung zu reduzieren, wurde das Konzept der Leichtgewichtsprozesse (Threads) entwickelt. Der Kern des Thread-Konzepts ist ein Kompromiss beim Adressraum, dem größten "Ballast" beim Kontextwechsel: Mehrere Threads, die als vertrauenswürdig gelten, teilen sich einen gemeinsamen Adressraum. Dadurch entfällt bei einer Umschaltung zwischen ihnen der aufwendige Wechsel des Adressraums, was den Kontextwechsel erheblich vereinfacht.
In diesem Multithreading-Modell sind die Threads die eigentlichen "Aktivitätsträger" (Ausführungsfäden). Der Prozess dient nur noch als "Container", der den gemeinsamen Adressraum und andere Ressourcen bereitstellt. Jeder Thread besitzt nur seine eigenen Register und einen individuellen Stack; Code- und Datenbereiche werden geteilt.
Umschaltungen zwischen Threads desselben Prozesses sind "leichtgewichtig". Nur ein Wechsel zwischen Threads verschiedener Prozesse bleibt "schwergewichtig", da hier der volle Prozesskontext gewechselt werden muss. Diese erhöhte Software-Parallelität durch Threads lässt sich ideal auf die Hardware-Parallelität moderner Mehrkernprozessoren abbilden.
1.4.6. Threadsprogrammierung auf Anwenderebene
Die Existenz von Threads ändert die Herangehensweise an die Programmierung: Statt Anwendungen als einen oder mehrere schwergewichtige Prozesse zu implementieren, müssen Entwickler über eine feinere Aufteilung in einzelne Threads nachdenken. Dies ermöglicht eine feingranulare Parallelität innerhalb einer einzigen Anwendung. Der Hauptvorteil besteht darin, dass die gesamte Anwendung nicht blockiert wird, wenn eine Teilaufgabe, wie das Laden von Daten, unkalkulierbare Zeit benötigt. Dank Multithreading können andere Teile, beispielsweise die Reaktion auf Benutzereingaben, unabhängig und nebenläufig weiterlaufen, was die Reaktionsfähigkeit des Programms sicherstellt.
Die Programmierung von Threads erfolgt über standardisierte Schnittstellen (APIs) oder ist direkt in Programmiersprachen integriert. Ein fundamentaler Unterschied zur Prozesserzeugung besteht in der Art des Starts: Während ein neuer Prozess typischerweise ein komplett neues Programm aus einer Datei lädt, wird ein neuer Thread durch den Aufruf einer spezifischen Funktion oder Methode innerhalb des laufenden Programms gestartet. Der aufrufende Thread wird dabei nicht blockiert, sondern läuft sofort parallel zum neu erstellten Thread weiter, wobei er oft ein "Handle" erhält, um den neuen Thread später zu referenzieren.
1.4.7. Betriebssystemunterstützung für Threads
Die Realisierung von Threads muss nicht zwangsläufig das Betriebssystem involvieren. Es ist möglich, eine ähnliche Funktionalität mit "einfachen Bordmitteln" auf Anwendungsebene zu implementieren, indem ein Algorithmus ständig zwischen verschiedenen Teilaufgaben hin und her wechselt. Eine entscheidende Voraussetzung hierfür ist jedoch, dass die verwendeten Betriebssystemfunktionen, etwa zur Abfrage von Eingaben, nicht blockierend sind. Obwohl Programmierbibliotheken dies unterstützen können, ist die direkte Unterstützung durch das Betriebssystem, insbesondere auf Mehrkernprozessoren, deutlich effektiver.
Daher wird bei der Implementierung grob zwischen zwei Formen unterschieden. User-Level-Threads sind Threads aus der Sicht der Anwendung und des Programmierers, die auf dem Betriebssystem ablaufen. Im Gegensatz dazu sind Kernel-Level-Threads die Threads aus der Sicht des Betriebssystems, die es auf der CPU zur Ausführung einplant. Moderne Betriebssysteme wie Windows stellen für diesen Zweck entsprechende API-Funktionen bereit (z.B. CreateThread() und ExitThread()), die sich prinzipiell an den Funktionen zur Prozessverwaltung orientieren.
Die praktische Implementierung von Threads erfolgt durch unterschiedliche Zuordnungen von User-Level-Threads zu Kernel-Threads. Bei einem Modell werden alle User-Level-Threads einer Anwendung einem einzigen Kernel-Thread zugeordnet. Hier liegt die Threadverwaltung komplett auf der Anwendungsebene, oft realisiert durch spezielle Bibliotheken, und das Betriebssystem weiß nichts von der Existenz der einzelnen User-Level-Threads.
Das Gegenstück ist das Modell, bei dem jedem User-Level-Thread genau ein Kernel-Thread zugeordnet wird. In diesem Fall kennt das Multithreading-Betriebssystem die Zuordnung und verwaltet alle Threads direkt selbst.
Darüber hinaus gibt es auch implementierungsabhängige hybride Lösungen, die diese Ansätze mischen, zu denen beispielsweise sogenannte Thread-Pools gehören.
1.4. Koordinierung paralleler (nebenläufiger) Prozesse
1.4.1 Wechselwirkungen
Im Multitasking-Betrieb ist die Annahme falsch, ein Prozess laufe ungestört. Stattdessen befinden sich viele Prozesse "nebeneinander" als Last auf dem System und unterliegen der Steuerung des Betriebssystems. Es ist dabei oft nicht vorhersehbar, wann ein Prozess unterbrochen und ein anderer Prozess "eingeschoben" wird, was zu ungesteuerten Wechselwirkungen führt. Diese unkoordinierte Verschachtelung der Abläufe hat zur Folge, dass die Gesamtablauffolge der Aktionen verschiedener Prozesse nicht deterministisch ist, auch wenn die Aktionen innerhalb eines einzelnen Prozesses sequenziell garantiert bleiben. Verschiedene Durchläufe können zu völlig unterschiedlichen Gesamtergebnissen führen.
Solche Wechselwirkungen entstehen typischerweise durch die gemeinsame Benutzung von Ressourcen, sei es durch Konkurrenz (z.B. um einen Drucker) oder Kooperation (z.B. Datenaustausch). Um diese Abläufe zu beherrschen und korrekte Ergebnisse zu garantieren, ist eine Koordinierung der Prozesse zwingend notwendig. Das Betriebssystem stellt Programmierern hierfür Mittel zur Synchronisation und Kommunikation zur Verfügung.
Lösungsansatz
Synchronisation bezeichnet die Beeinflussung paralleler Prozesse, um ihre zeitlichen Abläufe in eine bestimmte Reihenfolge zu bringen. Ein System ist determiniert, wenn die Ergebnisse der Verarbeitung unabhängig von der Ablaufgeschwindigkeit der Prozesse sind und für gleiche Eingaben stets gleiche Resultate liefern. Um dies zu erreichen, müssen Programmierer Synchronisationsoperationen nutzen, die das Betriebssystem bereitstellt.
Diese Operationen basieren auf Protokollen, also Steueralgorithmen zur Koordinierung. Protokolle lassen sich nach ihrem Koordinierungsprinzip klassifizieren: prozedurorientiert (Steuerung über globale Daten), nachrichtenorientiert (Steuerung durch Nachrichten) oder prozessorientiert (Steuerung durch Dienstprozesse).
Ein weiteres Kriterium ist die Synchronisationsaktivität:
- Beim aktiven Warten (busy waiting) prüft ein Prozess wiederholt eine Bedingung.
- Beim passiven Warten wird der Prozess blockiert und in eine Warteliste eingeordnet, bis die Bedingung erfüllt ist.
An diese Protokolle werden hohe Anforderungen gestellt, darunter Sicherheit und Lebendigkeit (z.B. Verklemmungsfreiheit). Moderne Multitasking-Betriebssysteme bevorzugen und bieten vorrangig zentrale Protokolle an, die auf passivem Warten basieren.
1.4.2. Konkurrenzsituation / Race conditions
Eine Konkurrenzsituation tritt auf, wenn mindestens zwei parallele Prozesse unabhängig voneinander dasselbe Betriebsmittel exklusiv (allein) benutzen wollen. Solche Situationen sind in Multitasking-Systemen aufgrund begrenzter Ressourcen unvermeidlich. Das Kernproblem ist, dass der genaue Zeitpunkt ihres Auftretens nicht vorhersagbar ist; es hängt von der Steuerung durch das Betriebssystem und dem Verhalten der übrigen Prozesse ab. Wenn das Betriebssystem die Prozesse ungesteuert umschaltet, kann es zu einer fehlerhaften Vermischung der Abläufe kommen, bei der ein Prozess die Ressource nicht für die gesamte benötigte Dauer exklusiv halten kann.
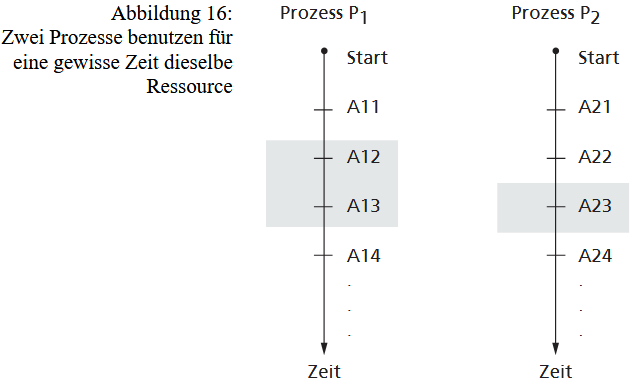
Diese ungesteuerte Verschachtelung kann dazu führen, dass Prozesse von falschen, da zwischenzeitlich unbemerkt veränderten, Daten ausgehen. Solche Szenarien werden als Wettlaufsituation (Race Condition) bezeichnet. Um diese Probleme zu verhindern, ist es essenziell, diejenigen Abschnitte in allen Prozessen zu identifizieren, die im Gesamtablauf nicht miteinander vermischt oder parallel ausgeführt werden dürfen. Diese spezifischen Verarbeitungsschritte, in denen ein exklusiver Zugriff auf ein Betriebsmittel erfolgt und die daher nicht parallel zu denselben Schritten eines anderen Prozesses ablaufen dürfen, bilden einen kritischen Abschnitt (critical section).
Das Problem der Konkurrenz ließe sich zwar trivial lösen, indem alle Prozesse streng sequenziell nacheinander ablaufen. Dies würde jedoch die (Quasi-)Parallelität des Multitasking-Betriebs vollständig aufheben. Es kann zwar durch Zufall zu fehlerfreien Abläufen im Multitasking kommen, wenn ein kritischer Abschnitt zufällig nicht unterbrochen wird, doch das Ziel der Synchronisation ist es, die korrekte Ausführung immer zu garantieren, nicht nur zufällig.
Lösungsprinzip
Um Konkurrenzsituationen zu lösen, ist der wechselseitige Ausschluss (mutual exclusion) erforderlich. Dieses Koordinierungsprinzip erlaubt nur einem der konkurrierenden Prozesse den exklusiven Zugriff auf eine Ressource, während alle anderen "ausgesperrt" werden. Realisiert wird dies durch Sperrsynchronisation-Protokolle, die die Sicherheit gewährleisten, indem sie sicherstellen, dass sich höchstens ein Prozess in seinem kritischen Abschnitt (bezüglich dieser Ressource) befindet. Selbst wenn der aktive Prozess im kritischen Abschnitt unterbrochen wird, muss das Protokoll jeden anderen zutrittswilligen Prozess am Betreten hindern, bis der erste den Abschnitt wieder verlassen hat.
Neben der Sicherheit müssen diese Protokolle auch die Lebendigkeit (Liveness) garantieren: Jeder Prozess, der eintreten möchte, muss dies irgendwann auch dürfen. Das schließt Fernwirkungsfreiheit (keine Behinderung durch unbeteiligte Prozesse), Verklemmungsfreiheit (deadlock freedom) und Behinderungsfreiheit (starvation freedom) ein. Da die korrekte Implementierung dieser Anforderungen komplex ist, hat sich in der Praxis eine Zweiteilung durchgesetzt: Der Programmierer muss unmittelbar vor dem kritischen Abschnitt ein Vorprotokoll (zum Sperren) und unmittelbar danach ein Nachprotokoll (zum Freigeben) einfügen
Lösungsansatz
Sperren (Mutexe/Spinlocks)
Um zu verhindern, dass sich zwei Prozesse gleichzeitig in ihren kritischen Abschnitten befinden, führen die Prozesse eine gemeinsam benutzte zweiwertige Variable, die Sperrvariable. Hat sie den Wert 0, erlaubt sie den Eintritt in den kritischen Bereich, mit 1 wird dieser Eintritt gesperrt. Der in denkritischen Bereich eintretende Prozess muss vor seinem Eintritt prüfen, ob der Abschnitt frei ist, d. h., ob die Sperrvariable den Wert 0 hat. Ist dies der Fall, setzt er die Sperrvariable auf 1 und betritt den kritischen Abschnitt. Alle anderen Prozesse, die nun die Sperrvariable überprüfen, finden den Wert 1 und müssen warten. Der eingetretene Prozess muss am Ende des kritischen Bereichs die Sperrvariable wieder auf 0 setzen. Damit wird der kritische Bereich für andere Prozesse frei.
Moderne Prozessoren bieten dafür spezielle atomare Befehle (wie "test and set lock"). Dies ist jedoch eine sehr hardwarenahe Lösung, die zudem zu aktivem Warten (busy waiting) führt, da Prozesse in einer Schleife (polling) wiederholt prüfen müssen, ob die Sperre frei ist. Diese atomaren Hardware-Befehle sind jedoch die notwendige Grundlage, um effizientere, höherwertige Synchronisationsmittel zu implementieren.
Semaphor
Das bewährteste und von den meisten Betriebssystemen angebotene Mittel ist der Semaphor, der von Dijkstra 1965 eingeführt wurde. Ein Semaphor ist ein Objekt (abstrakter Datentyp), das eine globale Steuervariable und eine Warteliste für Prozesse enthält. Er vermeidet aktives Warten durch Betriebssystemunterstützung. Er bietet zwei Methoden: p (für das Vorprotokoll, oft "down" genannt) und v (für das Nachprotokoll, oft "up" genannt).
- Ruft ein Prozess die p-Operation auf, wird geprüft, ob der kritische Abschnitt frei ist. Wenn ja, wird die Steuervariable dekrementiert und der Prozess darf eintreten. Wenn nein, wird der aufrufende Prozess durch Einfügen in die Warteliste blockiert (passives Warten).
Die jeweiligen Programmabschnitte der Prozesse, die auf gemeinsam benutzte Daten oder andere Betriebsmittel zugreifen, nennt man kritische Abschnitte.
- Ruft ein Prozess die v-Operation auf, signalisiert er das Verlassen des kritischen Abschnitts. Das Protokoll prüft, ob Prozesse in der Warteliste sind. Wenn ja, wird ein wartender Prozess "befreit" und in den "bereit"-Zustand überführt; die Steuervariable bleibt dabei unverändert.
Nur wenn niemand wartet, wird die Steuervariable inkrementiert. Für die Korrektheit des gesamten Systems ist es essenziell, dass die p- und v-Operationen selbst als unteilbare (atomare) Operationen implementiert sind. Das Betriebssystem muss (mithilfe der atomaren Hardware-Sperren) verhindern, dass eine p- oder v-Operation während ihrer Ausführung unterbrochen wird, da sonst Race Conditions entstehen könnten.
Binäre und zählende Semaphoren
Es gibt zwei Hauptvarianten von Semaphoren. Binäre Semaphore (mutex) können nur zwei Zustände annehmen und eignen sich für den klassischen wechselseitigen Ausschluss, bei dem nur ein Prozess eintreten darf. Allgemeine (zählende) Semaphore verwenden eine Zählvariable, die angibt, wie viele Prozesse den kritischen Abschnitt gleichzeitig betreten dürfen, was für Ressourcen nützlich ist, die mehrfach vorhanden sind.
In der Praxis ist die Anwendung von Semaphoren jedoch sehr fehleranfällig. Programmierer müssen kritische Abschnitte exakt identifizieren und die p- und v-Operationen korrekt platzieren. Ein Vergessen der v-Operation oder ein Vertauschen der Reihenfolge kann zu Laufzeitfehlern führen, die vom Compiler nicht erkannt werden. Um diese Komplexität und Fehleranfälligkeit zu reduzieren, bieten höhere Programmiersprachen oft robustere, integrierte Synchronisationsmittel an. Das Konzept des Monitors beispielsweise kapselt gemeinsam genutzte Daten und erlaubt den Zugriff nur über definierte, automatisch synchronisierte Methoden. Einige moderne Programmiersprachen haben dieses Konzept übernommen, um die Koordination von parallelen Threads sicherer und übersichtlicher zu gestalten.
1.4.3. Kooperation von Prozessen
Unter Kooperation paralleler Prozesse versteht man eine bewusste Zusammenarbeit mehrerer Prozesse mit dem Ziel, durch Arbeitsteilung eine komplexe Gesamtaufgabe zu erfüllen. Im Gegensatz zur unerwartet auftretenden Konkurrenz ist diese Form der Koordinierung zielgerichtet, da ein einzelner Prozess die Aufgabe nicht allein bewältigen kann. Diese Zusammenarbeit muss "geordnet" erfolgen, da für bestimmte Verarbeitungsschritte eine vordefinierte Reihenfolge (Präzedenz) eingehalten werden muss. Das bedeutet, ein Prozess muss unter Umständen an einer bestimmten Stelle warten, bis er sicher sein kann, dass ein anderer Prozess seine Teilarbeit abgeschlossen hat. Obwohl die Kooperation beabsichtigt ist, schränkt sie, genau wie die Konkurrenz, die maximal mögliche Parallelität im System ein. Das Betriebssystem darf nicht mehr beliebig umschalten, da es die vorgegebenen Abhängigkeiten sicherstellen muss. Ein klassisches Beispiel hierfür ist das Erzeuger-Verbraucher-Problem, bei dem über einen Puffer (reservierter Speicherbereich im RAM) kommuniziert wird und klare Regeln (z.B. "Lesen nur, wenn voll") eingehalten werden müssen.

Wie erzwingt man eine strikte Reihenfolge (Synchronisation), obwohl die Prozesse eigentlich unabhängig voneinander laufen wollen?
Lösungssprinzip
Ein Prozess muss unter Umständen an einer bestimmten Stelle warten, bis er sicher sein kann, dass ein anderer Prozess eine notwendige Aktion ausgeführt hat. Diese grundlegendste Form der Koordinierung wird als Ereignissynchronisation bezeichnet. Sie erzwingt Präzedenzen zwischen verschiedenen Prozessen. Um dies zu implementieren, werden Operationen benötigt, mit denen ein Prozess ein "Ereignis melden" (Signal) kann, und Operationen, mit denen ein anderer Prozess auf dieses Ereignis "warten" (Wait) kann. Das Grundprinzip dabei ist, nur die unbedingt nötigen Reihenfolgebeziehungen zu garantieren, während ansonsten maximale Parallelität (Multitasking) erhalten bleiben soll.
In vielen Fällen von Kooperation reicht das bloße Melden eines Ereignisses jedoch nicht aus; es müssen zusätzlich Daten, wie etwa Teilergebnisse, übertragen werden. Dieser zielgerichtete Austausch von Informationen zwischen parallelen Prozessen wird als Interprozesskommunikation (IPC) bezeichnet. Die IPC-Möglichkeiten lassen sich grob unterteilen. Bei der speicherbasierten Kommunikation stellt das Betriebssystem lediglich einen gemeinsamen Speicherbereich bereit; die Prozesse müssen sich jedoch selbst um die gesamte Synchronisation (z.B. den Schutz vor Race Conditions) kümmern. Bei der nachrichtenbasierten Kommunikation (Message Passing) tauschen Prozesse hingegen "Nachrichten" als eigenständige, identifizierbare Objekte aus. Das Betriebssystem verwaltet diese Nachrichten (mit Kopf- und Körperdaten) und stellt den Übergabemechanismus bereit.
Kommunikationsverfahren, speziell das Message Passing, werden anhand mehrerer Kriterien klassifiziert. Bezüglich der Zahl der Prozesse unterscheidet man direkte Kommunikation, die Prozessidentifikatoren nutzt (1:1, 1:n oder m:1), und indirekte Kommunikation, die über eine gemeinsame Übergabestelle läuft und m:n-Beziehungen erlaubt. Beim Datentransport kann entweder der Wert der Nachricht kopiert oder nur eine Adresse (Verweis) auf die Daten übergeben werden. Das Übertragungssystem kann speichernd (buffering) sein, wobei Nachrichten aufbewahrt werden, bis der Empfänger sie abholt, oder nicht speicherernd, wobei eine nicht zustellbare Nachricht verloren geht.
Das wichtigste Kriterium ist die Synchronisation des Austauschs. Bei der synchronen Kommunikation wird ein Prozess blockiert. Ein "blocking send" (blockierendes Senden) hält den Sender an, bis der Empfänger die Nachricht erhalten oder bestätigt hat. Im Gegensatz dazu wird bei der asynchronen Kommunikation auf eine Synchronisation verzichtet. Ein "non-blocking send" (nicht-blockierendes Senden) erlaubt dem Sender, die Nachricht zu übergeben und sofort mit seiner eigenen Arbeit fortzufahren, ohne auf den Empfänger zu warten. Diese verschiedenen Mittel der Synchronisation und Kommunikation ermöglichen die Realisierung komplexer, arbeitsteiliger Beziehungen und verteilter Verarbeitung.
Lösungsmittel
Zur Ereignissynchronisation können prozedurorientierte Mittel genutzt werden. „Private“ Semaphore dienen hier nicht dem wechselseitigen Ausschluss, sondern der reinen Signalisierung; eine v-Operation meldet ein Ereignis, eine p-Operation wartet darauf, wobei der Semaphor typischerweise mit 0 initialisiert wird. Ereigniszähler (event flags) sind Objekte zur Registrierung von Ereignissen, die Operationen zum Signalisieren (und Wecken aller Wartenden) oder zum Warten auf einen bestimmten Zählerstand bieten. Signale wiederum sind asynchrone Prozessunterbrechungen (Software-Interrupts) zur Anzeige besonderer Ereignisse oder Ausnahmesituationen, auf die ein Prozess mittels einer Behandlungsroutine reagieren kann. All diese Mechanismen erfordern große Sorgfalt, da ihre fehlerhafte Anwendung zu schwerwiegenden Laufzeitfehlern führen kann.
Bei der Interprozesskommunikation (IPC) wird zwischen speicher- und nachrichtenbasierten Verfahren unterschieden. Zu den speicherbasierten Mitteln gehört:
-
Kommunikation über gemeinsame Speicherbereiche. Hierbei stellt das Betriebssystem einen Speicherbereich bereit, der in die Adressräume mehrerer Prozesse eingeblendet wird. Dies ist extrem schnell, da keine speziellen API-Aufrufe zum Lesen und Schreiben nötig sind. Der Nachteil ist, dass die Programmierer die gesamte erforderliche Synchronisation (sowohl Sperr- als als auch Ereignissynchronisation) manuell, z.B. mit Semaphoren, implementieren müssen.
-
Kommunikation über gemeinsame Dateien: Prozesse schreiben in Dateien, die von anderen Prozessen gelesen werden. Auf diese Weise kommunizieren einzelne (und oftmals unterschiedliche) Programme.
Nachrichtenbasierte Kommunikation (Message Passing) hat den Vorteil, dass das Betriebssystem die Verwaltung und Synchronisation übernimmt und die Verfahren oft netzwerkfähig sind. Pipes sind unidirektionale FIFO-Puffer (Datenröhren) für Byteströme, bei denen das Betriebssystem das Lesen aus einer leeren Pipe automatisch blockiert. Nachrichtenwarteschlangen (message queues) sind flexiblere, indirekte Übergabestellen (wie Mailboxen) für m:n-Beziehungen, über die ganze Nachrichten-Objekte mit verschiedenen Strategien (z.B. Priorität) ausgetauscht werden.
Sockets bilden die Grundlage für die Netzwerkkommunikation. Sie sind standardisierte Kommunikationsendpunkte, die die darunterliegenden Protokolle (wie TCP/IP) abstrahieren und so die Kommunikation zwischen Prozessen auf unterschiedlichen Betriebssystemen ermöglichen. Eine noch höhere Abstraktionsebene ist der Entfernte Prozeduraufruf (Remote Procedure Call, RPC). Dieses Verfahren, ebenso wie Java RMI, lässt einen Dienst auf einem entfernten Rechner wie einen lokalen Funktionsaufruf erscheinen, indem es den zugrundeliegenden Nachrichtenaustausch vor dem Programmierer verbirgt.
1.5. Ressourcen (Betriebsmittel)
1.5.1. Klassifikation von Betriebsmitteln
Betriebsmittel (Ressourcen) sind alle Komponenten (Objekte) eines Computersystems, die zur Erfüllung von Aufträgen durch Prozesse benötigt werden.
Sie lassen sich anhand verschiedener Kriterien klassifizieren. Zunächst wird nach der Realisierungsform unterschieden, ob es sich um Hardware-Ressourcen (wie Drucker) oder Software-Ressourcen (wie Dateien) handelt.
Hinsichtlich der Nutzbarkeit wird zwischen lokalen (privaten) Ressourcen, die nur einem Prozess gehören, und globalen (gemeinsamen) Ressourcen, die allen zur Verfügung stehen, differenziert. Die Wiederverwendbarkeit beschreibt, ob Betriebsmittel nacheinander von mehreren Prozessen genutzt werden können (wie der Prozessor) oder ob sie bei der Benutzung verbraucht bzw. zerstört werden (wie Signale oder Nachrichten).
Ein weiteres Kriterium ist die Entziehbarkeit: Entziehbare Ressourcen (z.B. der Prozessor) können einem Prozess temporär weggenommen und ihr Zustand konserviert werden, während dies bei nicht entziehbaren (z.B. einem laufenden Druckauftrag) nicht möglich ist. Schließlich definiert die Benutzungsweise, ob Ressourcen mehrfach (parallel) oder nur exklusiv (einzeln und nacheinander) genutzt werden können.
1.5.2. Verwaltung von Betriebsmitteln
Unter Scheduling (Ablaufplanung) versteht man die Vorgehensweise des Betriebssystems bei der Zuteilung von Ressourcen an Prozesse. Die Auswahl des für die Zuteilung am besten geeigneten Prozesses wird vom Scheduler anhand einer konkreten Strategie vorgenommen.
Das Ziel ist ein optimales Systemverhalten, wobei sich verschiedene Zielfunktionen wie Fairness, maximaler Durchsatz oder minimale Antwortzeit widersprechen können.
Statische vs Dynamische Zuteilung
Eine statische Zuteilung, bei der ein Prozess alle Ressourcen bei der Erzeugung erhält, ist nur bei vorab bekanntem Ressourcenbedarf (z.B. im Stapelbetrieb) möglich. In allen anderen Fällen erfolgt eine "operative", dynamische Zuteilung, bei der ein Prozess Ressourcen je nach aktueller Systemlast anfordern muss.
Bei der dynamischen Zuteilung fordert ein Prozess Ressourcen per API-Funktion an. Erhält er sie nicht, wird er blockiert und in eine Warteliste eingeordnet. Da die exklusive Nutzung einen kritischen Abschnitt darstellt, wird dies oft über Semaphore realisiert: Die p-Operation dient der Anforderung und die v-Operation der Freigabe des Betriebsmittels.
Strategien mithilfe von Semaphoren
Mithilfe von Semaphoren lassen sich verschiedene Strategien zur Betriebsmittelverwaltung realisieren:
- Die Anforderung einer einzelnen Ressource kann einfach mithilfe eines binären Semaphors erfolgen, der den exklusiven Zugriff (als kritischen Abschnitt) regelt.
- Zur Verwaltung mehrerer gleichartiger Ressourcen (wie Blöcke aus einem Speicher-Pool) können allgemeine (zählende) Semaphore genutzt werden. Der Wert der Steuervariablen gibt dabei an, wie viele Exemplare der Ressource noch verfügbar sind.
- Die gleichzeitige Anforderung mehrerer verschiedener Ressourcen ist komplexer und kann auf der Basis von "Sammelanforderungen" realisiert werden, beispielsweise indem die Anforderungen in einem Vektor markiert werden.
Entziehbarkeit: Scheduling durch Verdrängung (preemption)
Bei Multitasking-Betriebssystemen unterscheidet man zwei Grundansätze für das Scheduling:
- Bei nicht verdrängenden Verfahren = kooperatives Multitasking (non-preemptive) entscheidet das Betriebssystem erst über eine Neuzuteilung, wenn der aktuelle Prozess die Ressource freiwillig zurückgibt. Dies wird als "kooperatives Multitasking" bezeichnet und ist vom "guten Willen" der Prozesse abhängig.
- Im Gegensatz dazu können bei verdrängenden Strategien = verdrängendes Multitasking (preemptive) Prozesse jederzeit durch das Betriebssystem unterbrochen werden, um ihnen die Ressource vorzeitig zu entziehen. Dieses Verfahren wird von den meisten modernen Betriebssystemen verwendet.
Time-triggered vs event-triggered
Für verdrängende Strategien gibt es unterschiedliche Auslöser. Bei zeitgesteuerten Verfahren (time-triggered) wird die Verdrängung durch eine Zeitunterbrechung ausgelöst, etwa wenn ein zugewiesenes Zeitlimit (Time Slice, Quantum) abgelaufen ist, was ein Timer-Interrupt signalisiert. Bei ereignisgesteuerten Verfahren (event-triggered) ist der Auslöser ein besonderes Ereignis, wie beispielsweise das Eintreffen eines neuen Auftrags mit höherer Wichtigkeit, das eine sofortige Umschaltung erfordert.
Prozessor-Scheduling
Der Prozessor-Scheduler wird bei jeder Prozessumschaltung vom Dispatcher aktiviert, um den am besten geeigneten Prozess aus der Menge der laufbereiten auszuwählen, notfalls auch einen Leerlaufprozess.
Es existiert eine Vielzahl unterschiedlicher Strategien (Algorithmen), die sich in nichtverdrängende und verdrängende Verfahren einteilen lassen.
- Bei den nichtverdrängenden Strategien erfolgt die Zuteilung in der Reihenfolge des Eintreffens (First Come First Served, FCFS) oder bevorzugt den Prozess mit der kürzesten erwarteten Bearbeitungszeit (Shortest Job First, SJF), wobei letztere in der Praxis oft schwer bekannt ist.
- Die meisten Betriebssysteme nutzen verdrängende Strategien. Am bekanntesten ist Round Robin (Time-Slice-Verfahren), das den Prozessor reihum jedem Prozess für eine feste Zeitscheibe zuteilt. Ist die Zeit abgelaufen oder gerät ein Prozess in eine Wartesituation, wird ihm der Prozessor entzogen. Dieses Verfahren ergibt kurze Antwortzeiten bei kleinem Quantum, aber bedingt höhere Rechenzeitverluste durch die häufigen Prozesswechsel.
Andere Verfahren nutzen Prioritäten.
- Bei festen, statischen Prioritäten erhält immer der Prozess mit der höchsten Priorität den Prozessor, was aber zum "Verhungern" (Starvation) rangniedriger Prozesse führen kann.
- Um dies zu verhindern, werden dynamische Prioritäten verwendet, die das Betriebssystem zyklisch anpasst. Kriterien dafür können
- Shortest Elapsed Time (SET) - die Priorität sinkt bei wachsender Bearbeitungszeit,
- Shortest Remaining Processing Time: Die Priorität wächst mit kleiner werdender verbleibender Bearbeitungszeit der Prozesse
- Highest Response Ratio Next (HRRN): Die Priorität ist abhängig vom Quotienten aus Bearbeitungszeit und Wartzeit (=B + W) die Erhöhung der Priorität bei langer Wartezeit (Aging) sein.
- Aging: Die Priorität wächst mit zunehmendem „Alter“ des Prozesses
Zeitabhängige Scheduling-Verfahren ähneln dynamischen Prioritäten, legen den Fokus aber auf die Einhaltung strikter Zeitbedingungen, was für den Echtzeitbetrieb (z.B. Robotersteuerung) unerlässlich ist. Die Ergebnisse eines Prozesses müssen hierbei garantiert rechtzeitig vorliegen.
Diese Verfahren erfordern eine ständige Kontrolle des Systems und eignen sich am besten für "geschlossene Systeme" mit (weitgehend) fester Prozessanzahl oder für periodische Prozesse, weniger jedoch für "offene" Dialogsysteme. Strategien wie Earliest Deadline First (EDF) priorisieren den Prozess mit der am nächsten liegenden Deadline, während Least Laxity First (LLF) den Prozess mit dem geringsten zeitlichen Spielraum (Laxity) bevorzugt.
- Welche Konsequenzen für den gesamten Ablauf des Prozesssystems hat es bei einem Round-Robin-Scheduling, wenn die Zeitscheibe für jeden Prozess a. sehr kurz, b. sehr lang?
- Welche der folgenden Verfahren sind gleichermaßen fair zu allen Prozessen? a. Round Robin b. Statische Prioritäten c. Deadline-Scheduling
1.5.3. Verklemmungen (Deadlocks)
Eine Verklemmung (deadlock) ist ein gefährlicher Zustand in einem System paralleler Prozesse, bei dem einige Prozesse derart wechselseitig aufeinander warten, dass grundsätzlich keiner von ihnen mehr voranschreiten kann.
Eine Verklemmung ist eine besonders kritische Situation, bei der mehrere Prozesse in einen permanenten Wartezustand geraten. Dies passiert, wenn sie auf Bedingungen oder "Hilfe" warten, die nur von anderen Prozessen erfüllt werden können, welche jedoch ihrerseits auf Bedingungen der ersten Gruppe warten. Wenn diese Abhängigkeit zirkulär ist, bleiben alle beteiligten Prozesse auf Dauer blockiert.
Es ist wichtig, diese permanente Blockade von einem zeitweiligen Warten auf eine Ressource zu unterscheiden. Verklemmungen entstehen typischerweise im Zusammenhang mit der exklusiven Benutzung von Ressourcen. Ein weiteres Merkmal ist ihre Zufälligkeit: Sie können selbst dann auftreten, wenn die Koordinierungsmittel (wie Semaphore) logisch korrekt implementiert sind, die Reihenfolge der Anforderungen durch die Prozesse aber zufällig "unzweckmäßig" war und so zur gegenseitigen Blockade führt.
Verklemmung durch Semaphore
Das ist das klassische "Dining Philosophers"-Problem (oder "Kreuzungs-Problem") in Reinform.
In diesem Beispiel entsteht eine zirkuläre Wartebedingung:
- Prozess P1 schnappt sich Ressource R1 (z. B. Semaphor S1).
- Prozess P2 schnappt sich Ressource R2 (z. B. Semaphor S2).
- Jetzt will P1 weitermachen und fordert R2 an. Das Betriebssystem blockiert P1 (setzt ihn auf "wartend"), weil P2 diese Ressource exklusiv besitzt.
- Gleichzeitig will P2 weitermachen und fordert R1 an. Das Betriebssystem blockiert P2, weil P1 diese Ressource exklusiv besitzt.
Das Ergebnis: P1 wartet auf P2, und P2 wartet auf P1. Keiner von beiden kann jemals den Code-Abschnitt erreichen, in dem er seine erste Ressource wieder freigibt (v-Operation), weil er auf die zweite Ressource wartet, die der andere blockiert. Sie sind permanent verkeilt.

Zur Erinnerung: p-Operation (proberen/wait): Fordert eine Ressource an und blockiert den Prozess (setzt ihn auf "wartend"), falls die Ressource nicht verfügbar ist. v-Operation (verhogen/signal): Gibt eine Ressource wieder frei und weckt einen eventuell wartenden Prozess auf.
Ursachen von Verklemmungen
Eine Verklemmung (Deadlock) ist ein dauerhafter, zufälliger Stillstand, der nur eintreten kann, wenn vier Bedingungen erfüllt sind.
Die ersten drei sind notwendige Bedingungen:
- Exklusive Ressourcennutzung (B1): Die Prozesse nutzen die Ressourcen exklusiv (durch Realisierung des wechselseitigen Ausschlusses).
- Kein Ressourcenentzug (B2): Einem Prozess können bereits zugewiesene Ressourcen nicht entzogen, sondern sie müssen von ihm selbst freigegeben werden
- "Hold and Wait" (B3): Die Prozesse fordern irgendwann weitere Ressourcen nach, ohne zuvor die bisher bereits belegten (zugeteilten) Ressourcen freizugeben
- Eine Verklemmung tritt jedoch erst tatsächlich ein, wenn auch die hinreichende Bedingung erfüllt ist: 4. Zirkuläres Warten (B4): Es entsteht eine geschlossene Kette von Abhängigkeiten (z. B. P1 wartet auf P2, P2 wartet auf P1).
1.5.4. Gegenmaßnahmen (Verklemmungen)
Es gibt verschiedene Gegenmaßnahmen gegen Verklemmungen. Die einfachste ist das Ignorieren, der "Vogel-Strauß-Algorithmus", bei dem man annimmt, dass Verklemmungen selten sind und dem Benutzer die Beseitigung (z.B. Abbruch eines Prozesses) überlässt.
Die zweite Maßnahme ist die vorbeugende Verhinderung (prevention), die darauf abzielt, dass mindestens eine der notwendigen Entstehungsbedingungen für Verklemmungen generell unterbunden wird, was jedoch Restriktionen für Programmierer bedeutet.
Die Vermeidung (avoidance) ist eine weitere Kategorie, bei der das Beztriebssystem jede Ressourcenanforderung auf "sichere Zustände" hin prüft, ist aber in der Praxis sehr aufwendig.
Die letzte Gruppe ist die Erkennung und Beseitigung (detect and delete). Hierbei sucht das Betriebssystem nicht, Verklemmungen zu verhindern, sondern aktiv nach ihnen, etwa durch die aufwendige Analyse des Betriebsmittelgraphen auf Zyklen.
Wird eine Verklemmung erkannt, erfolgt die Auflösung (Ressourcen-Rückgewinnung) meist durch den Abbruch eines oder mehrerer der verklemmten Prozesse. In der Praxis bieten die meisten Betriebssysteme wenig automatische Unterstützung und überlassen die Erkennung und Beseitigung dem Benutzer (z.B. Task-Manager). Eine Time-Out-Kontrolle kann zwar Prozesse nach einer Wartefrist befreien, erfordert aber eine spezielle Fehlerbehandlung im Programm.
1.6. Speicherverwaltung
Speicher wird in Betriebssystemen in einer eigenen Komponente verwaltet. Betriebssysteme verwalten sowohl intenen als auch externen (peripheren) Speicher.
1.6.1. Aufgaben der Speicherverwaltung
An die Speicherverwaltung werden hohe Anforderungen gestellt, da Speicher räumlich und zeitlich geteilt werden kann und die Verwaltung stark von der Hardware, wie der Memory Management Unit (MMU), abhängt. Zu ihren Kernaufgaben gehören die Zuteilung und Rücknahme von Speicherbereichen an Prozesse, die effiziente Verwaltung freier und belegter Bereiche sowie der Schutz vor unerlaubten Zugriffen. Sie muss auch technische Beschränkungen verbergen, etwa durch die Verwaltung von Speicherhierarchien und die Organisation der nötigen Ein-/Auslagerung von Daten.
Ein Prozess benötigt Speicher für seinen (meist konstanten) Programmcode und seine statischen Daten, aber auch für einen (veränderlichen) Teil für dynamische Daten und den Stack. Die Zuordnung von Speicher kann statisch beim Prozessstart erfolgen oder dynamisch zur Laufzeit, wenn ein Prozess sie aktiv anfordert, beispielsweise mittels Bibliotheksfunktionen wie malloc().
1.6.2. Einfache Speicherverwaltung
Bei der einfachen Speicherverwaltung wird der physische Speicher räumlich aufgeteilt, typischerweise in einen Bereich für das Betriebssystem und einen für die Anwendungsprozesse. Für die Anwendungsbereiche gibt es zwei grundlegende Strategien.
Die erste Strategie ist die Aufteilung in Partitionen fester Größe. Dies führt unweigerlich zu einem Problem: Wenn ein Prozess (z.B. 10 MB) eine zu große Partition (z.B. 16 MB) zugewiesen bekommt, wird der ungenutzte Speicher innerhalb dieser Partition (6 MB) verschwendet. Dieser Zustand wird als interne Fragmentierung bezeichnet.
Die zweite Strategie nutzt Partitionen variabler Größe. Hier vergibt das Betriebssystem den Speicher "passgenau" und zunächst lückenlos, je nach Bedarf des Prozesses. Probleme entstehen, sobald Prozesse beendet werden oder ihre Größe ändern: Es bilden sich Lücken zwischen den belegten Blöcken. Dies führt zur externen Fragmentierung. Das bedeutet, dass zwar insgesamt genügend Speicher frei sein kann (z.B. drei Lücken à 2 MB), aber ein neuer Prozess, der 5 MB benötigt, nicht gestartet werden kann, da kein einzelner zusammenhängender Block groß genug ist. Der freie Speicher ist "extern" (außerhalb der Partitionen) zerstückelt.
Um diesem Problem der externen Fragmentierung zu begegnen, kann eine Umordnung (garbage collection) durchgeführt werden. Dabei werden alle belegten Bereiche "dicht" an ein Ende des Speichers verschoben, um alle Lücken zu einem großen, zusammenhängenden freien Block zu vereinen. Dieser Vorgang erfordert jedoch einen erheblichen Rechenaufwand.
Eine grundlegende Voraussetzung für flexible Zuteilungen (sowohl bei festen als auch bei variablen Partitionen) ist die Verschiebbarkeit (Relocation) von Programmen. Dies bedeutet, dass die Adressverweise eines Programms zur Laufzeit angepasst werden müssen, je nachdem, in welche physische Partition es geladen wird.
Direkte Addressierung
Direkte Adressierung bedeutet, dass ein Betriebssystem Programme so in den Arbeitsspeicher lädt, dass deren Adressen im Code bereits feststehen und ohne weitere Umrechnung genutzt werden können. Einfache Einprogrammsysteme teilen den Speicher dazu in einen System- und einen Benutzerbereich. Das aktive Programm belegt dort einen einzigen zusammenhängenden Block, der Rest bleibt frei.
Bei dedizierten Systemen ist der Startpunkt des Benutzerbereichs fest definiert. Programme werden deshalb direkt für diese festen Speicheradressen übersetzt. Das macht die Verwaltung sehr einfach – ein Verfahren, das früher bei Mikroprozessoren üblich war und heute noch bei kleinen Steuerungen genutzt wird.
Universelle Systeme verwenden einen Job-Monitor zur Verwaltung einer Warteschlange und einen Absolutlader, der Programme mit bereits vollständig festgelegten Speicheradressen lädt. Auch hier erfolgt der Zugriff direkt auf absolute Speicheradressen.
Beim klassischen Einprogrammbetrieb befindet sich immer nur ein Prozess im Speicher, wodurch keine Konflikte entstehen.
Mit dem Mehrprogrammbetrieb ändert sich dies: Mehrere Prozesse teilen sich den Speicher gleichzeitig, was Schutzmaßnahmen erfordert. Damit Programme sich nicht gegenseitig überschreiben, wird der Speicher oft in feste Partitionen unterteilt, denen Prozesse zugeordnet werden. Zusätzlich müssen Programme beim Laden verschoben (relokiert) werden können. Die Speicherverwaltungseinheit überwacht dabei, dass jeder Prozess nur auf seinen eigenen Bereich zugreifen darf – Verstöße werden an das Betriebssystem gemeldet, um die Stabilität und Sicherheit des Gesamtsystems zu gewährleisten.
Relocation (Verschiebung)
Verschiebung (Relocation) wird nötig, wenn Programme oder Bibliotheksroutinen nicht immer an derselben Speicheradresse liegen können. Bei einfachen Systemen, in denen Programme zusammenhängend in den Speicher geladen werden, entsteht das Problem, dass Bibliotheksroutinen je nach Programmlänge an unterschiedlichen Stellen liegen würden. Eine direkte, feste Adressierung wäre dann nicht mehr möglich und würde zu erheblicher Speicherverschwendung führen, wenn man für jede Routine feste Speicherbereiche reservieren müsste.
Die flexiblere Lösung besteht darin, die Programme so vorzubereiten, dass ihre endgültigen Speicheradressen erst beim Laden bestimmt werden. Dabei kommt ein verschiebender Lader zum Einsatz, der relative Adressen im Programm erkennt und beim Laden in absolute Adressen umrechnet. Durch Addition eines Offsets – also der tatsächlichen Startadresse im Hauptspeicher – können Programme an beliebigen freien Stellen platziert werden. Voraussetzung ist, dass sie intern so geschrieben sind, als würden sie bei Adresse 0 beginnen. Der Ladevorgang dauert dadurch etwas länger, das Programm ist nach dem Laden jedoch fest an seine zugewiesene Speicherstelle gebunden.
Noch flexibler wird die Speicherverwaltung, wenn die Umwandlung von relativen in absolute Adressen nicht beim Laden, sondern erst bei der Programmausführung erfolgt. Dazu benötigt der Prozessor ein spezielles Adressrechenwerk, das einen Basiswert aus einem Register automatisch hinzurechnet. Da der Lader die Befehle nicht mehr umschreiben muss, geschieht das Laden deutlich schneller, und Programme können sogar noch verschoben werden, nachdem sie im Speicher liegen.
Alle diese Verfahren teilen jedoch eine zentrale Einschränkung: Die Programme dürfen nicht größer sein als der physisch verfügbare Hauptspeicher. Um diese Grenze zu überwinden, wurde die Überlagerungstechnik entwickelt – ein Schritt hin zu den virtuellen Speichern, die Programme größer erscheinen lassen, als es der reale Speicher zulässt.
Overlay
Die Overlay-Technik ermöglicht es, Programme auszuführen, die insgesamt größer sind als der verfügbare Hauptspeicher. Dazu wird das Programm in mehrere Abschnitte zerlegt, von denen immer nur diejenigen im Speicher liegen, die gerade benötigt werden. Fehlt ein Abschnitt, wird er dynamisch nachgeladen und überschreibt dabei einen zuvor genutzten Teil. Dieser Vorgang findet während der Laufzeit statt, weshalb man von dynamischem Laden spricht.
Die Struktur der Overlays muss der Programmierer selbst planen, weil nur er sinnvoll entscheiden kann, welche Programmteile nie gleichzeitig benötigt werden. Eine ungünstige Aufteilung führt zu häufigen Nachladevorgängen und damit zu spürbaren Verzögerungen. Typisch besteht eine Overlay-Struktur aus einem dauerhaft im Speicher verbleibenden Kernprogramm, mehreren austauschbaren Unterprogrammen sowie gemeinsamen Daten, die erhalten bleiben müssen. Der dafür vorgesehene Speicherbereich wird als Overlay- oder transiente Zone bezeichnet.
In modernen Betriebssystemen hat diese klassische Form der Überlagerung kaum noch Bedeutung, da virtuelle Speicherverwaltung diese Aufgaben wesentlich flexibler und automatisiert übernimmt.
Implementierung der Speicherverwaltung: Bitmaps und verkettete Listen
Zur Implementierung der Speicherverwaltung gibt es zwei typische Varianten.
Bitmap
Der Belegungsvektor (Bitmap) teilt den gesamten Speicher in gleich große Einheiten, wobei jedes Bit deren Belegungszustand (z.B. 0=frei, 1=belegt) anzeigt. Die Suche nach Speicher wird damit auf die Suche nach einer Folge von aufeinanderfolgenden Null-Bits zurückgeführt. Die Größe dieser Einheiten ist ein Kompromiss: Kleine Einheiten erzeugen eine sehr große Bitmap, während große Einheiten zu interner Fragmentierung führen (da im Schnitt die Hälfte der letzten Einheit ungenutzt bleibt).
Verkettete Listen
Die Alternative sind verkettete Listen, bei denen jeder Speicherbereich als Listenelement (mit Zustand, Anfangsposition, Größe und Zeiger) verwaltet wird, oft in einer separaten Freispeicherliste.
Algorithmen
Bei einer Speicheranforderung muss die Verwaltung einen "passenden" freien Bereich suchen. Dafür gibt es verschiedene Algorithmen, wie First-Fit (der erste ausreichend große Bereich), Next-Fit (wie First-Fit, aber die Suche beginnt ab der letzten Position), Best-Fit (der kleinste, gerade noch ausreichende Bereich) oder Worst-Fit (der größte verfügbare Bereich).
Bei der Freigabe von Speicherbereichen ist es entscheidend, dass das System prüft, ob der neu entstandene freie Teil mit einem oder beiden benachbarten Bereichen verschmolzen werden kann. Dies ist notwendig, um die externe Fragmentierung zu bekämpfen, indem größere, zusammenhängende freie Blöcke gebildet werden.
1.6.3. Speicherhierarchien
Ein Prozessor kann Daten schneller Speichern als diese Daten gespeichert werden können. Moderne Computer enthalten mehrere unterschiedliche Speicherkomponenten, die sich bezüglich ihrer Geschwindigkeit und Kapazität unterscheiden. Diese beiden Eigenschaften verhalten sich leider einander entgegengesetzt, sodass der Idealfall eines sehr schnellen und belieb großen Hauptspeicher nicht gegeben ist.
Aus diesem Grund verwendet man in modernen Computersystemen eine mehrstufige Speicherhierarchie.
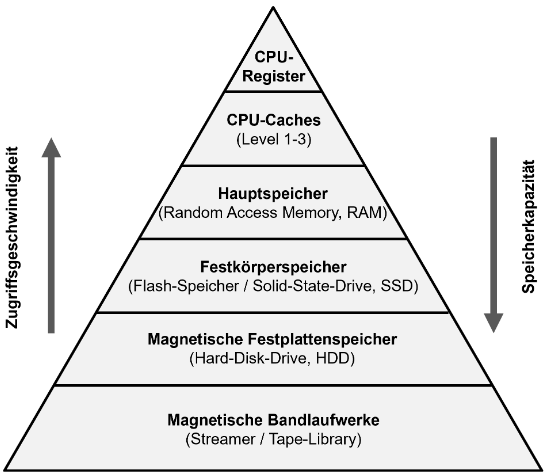
Am schnellsten sind die Prozessorregister, die jedoch kapazitiv auf wenige Hundert Byte limitiert sind. Darauf folgen die Cachespeicher (Level 1, Level 2) mit deutlich höheren Kapazitäten im Megabyte-Bereich. Der klassische Hauptspeicher (RAM) ist wiederum langsamer, bietet aber mehrere Gigabyte an Platz.
Noch langsamer, aber kapazitiv größer, sind Solid-State-Disks (SSDs), die bereits zur Peripherie zählen. Am Ende der Hierarchie stehen externe Speicher wie mechanische Festplatten oder Bandlaufwerke. Sie bieten die höchste Kapazität, haben aber aufgrund ihrer Mechanik extrem langsame Zugriffszeiten (Millisekunden bis Sekunden).
Da alle Programme und Daten zur Verarbeitung im schnellen Hauptspeicher (oder den Registern) vorliegen müssen, dieser aber nicht ausreicht, um alle Prozesse aufzunehmen, muss die Speicherverwaltung einen Kompromiss finden.
1.6.4. Swapping
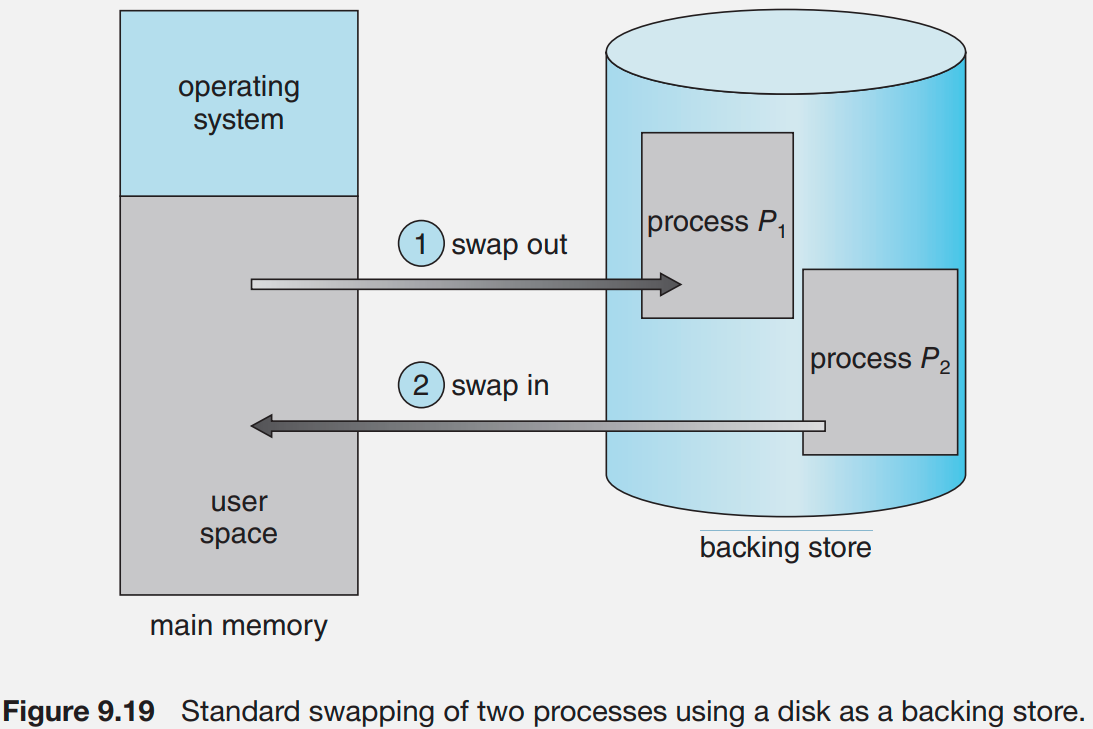
Im Betrieb kann es zu einem Hauptspeichermangel kommen. Um dies zu verhindern wird ein Prozess ausgewählt und alle von ihm belegten Hauptspeicherbereiche vorübergehend auf einen externen Speicher (im sogenannten backing store) ausgelagert. Dieses Austauschverfahren wird swapping bezeichnet.
Dabei wählt das Betriebssystem einen Prozess aus, idealerweise einen unwichtigen, der sich im Wartezustand befindet, und lagert alle von ihm belegten Hauptspeicherbereiche temporär auf einen externen Speicher (z.B. Festplatte) aus.
Dieser Vorgang umfasst den gesamten Adressraum des Prozesses (Code, Daten, Stack und Metadaten) und Teile seines Systemkontexts, die in den Swap-Bereich (meist eine Festplattenpartition oder Datei) geschrieben werden. Dasselbe gilt für Threads (alle Threads relevanten Daten müssen auch ausgelagert werden).
Ausgelagerte Prozesse sind nicht laufbereit und müssen vor einer späteren Fortführung erst vollständig wiedereingelagert werden. Die Verwaltung des Swap-Bereichs selbst (Belegung, Freigabe) erfolgt mit ähnlichen Verfahren wie die der Hauptspeicherverwaltung.
1.6.5. Virtueller Speicher
1.6.3. Virtuelle Speichervewaltung
Die virtuelle Speicherverwaltung ermöglicht es, Programmen eine zusammenhängende, unendlich große Speicherlandschaft vorzugaukeln, obwohl der physische Hauptspeicher begrenzt ist. Der zentrale Gedanke ist, den Adressraum, den die Programme verwenden, vom tatsächlich vorhandenen Arbeitsspeicher zu trennen. Dabei spricht das Programm nur den logischen, virtuellen Adressraum an, während das Betriebssystem zusammen mit spezieller Hardware dafür sorgt, dass diese logischen Adressen auf die physischen Speicherbereiche abgebildet werden. So kann der Programmierer unabhängig von der realen Speichergröße arbeiten.
In der Praxis wird nur der jeweils benötigte Teil eines Programms oder seiner Daten – das sogenannte Working Set – in den Arbeitsspeicher geladen. Alle anderen Teile bleiben ausgelagert und werden bei Bedarf nachgeladen. Dadurch können Programme ausgeführt werden, deren Gesamtgröße die Kapazität des physischen Speichers übersteigt, und gleichzeitig mehrere Programme parallel laufen, ohne dass der Anwender etwas davon merkt.
Die Umsetzung erfolgt durch die dynamische Adressumsetzung: Die logischen Adressen in den Befehlen bleiben unverändert, die Übersetzung in physische Adressen erfolgt erst bei der Befehlsausführung. Wenn ein benötigter Abschnitt nicht im Speicher liegt, unterbricht das Betriebssystem den laufenden Befehl, lädt den Abschnitt nach und setzt die Ausführung korrekt fort. Dieses Zusammenspiel von Hardware und Betriebssystem macht den virtuellen Speicher für den Anwender völlig transparent.
Effizienz wird erreicht, indem nicht einzelne Speicherzellen, sondern größere Abschnitte aus- und eingelagert werden. Die Speicherverwaltung erfolgt dabei typischerweise über Segmentierung oder Paging, die es erlauben, Speicher flexibel zuzuweisen, zu schützen und bei Bedarf zu verschieben. Die virtuelle Speicherverwaltung ist daher eines der zentralen Konzepte moderner Betriebssysteme und hat die ältere Overlay-Technik weitgehend ersetzt.
Relocation von Prozessen und Abstraktion
Das Grundprinzip des virtuellen Speichers (VM) basiert auf der Idee der Verschiebbarkeit (Relocation) und einer dynamischen Adressumsetzung zur Laufzeit. Das Betriebssystem verbirgt die tatsächliche Größe und Anordnung des physischen Hauptspeichers und "spiegelt" stattdessen jedem Prozess einen eigenen, nahezu unbegrenzten und logisch zusammenhängenden (virtuellen) Adressraum vor. Diese Abstraktion befreit den Programmierer davon, sich um reale Speicherbeschränkungen oder die Organisation der Ein-/Auslagerung von Daten kümmern zu müssen. Aus Sicht des Prozesses werden nur die aktuell benötigten Speicherteile im Hauptspeicher gehalten, während der Rest auf einem externen Speicher liegt.
Die Realisierung von virtuellem Speicher erfordert eine Speicherhierarchie (Hauptspeicher und externer Speicher) sowie zwingend eine Hardware-Unterstützung durch die MMU (Memory Management Unit) des Prozessors. Die MMU ist für die dynamische Umwandlung der virtuellen Adressen des Prozesses in reale, physische Adressen im Hauptspeicher verantwortlich. Zur Organisation werden sowohl der virtuelle Adressraum als auch der physische Speicher in Verwaltungseinheiten aufgeteilt. Diese Einheiten können entweder unterschiedlich groß sein (Segmente, Segmenting) oder alle die gleiche feste Größe haben (Seiten, Paging).
Der technische Ablauf der Adressumsetzung läuft für die Anwendung unsichtbar ab. Bei jedem Speicherzugriff innerhalb eines Befehls prüft die MMU mithilfe von Tabellen, ob sich die adressierten Daten bereits im Hauptspeicher befinden. Falls ja, wird die Adresse umgewandelt und der Zugriff erfolgt. Falls nein, löst die Hardware eine Ausnahme (Exception) aus, die den aktuellen Befehl unterbricht, da auf die Daten noch nicht zugegriffen werden kann (dies nennt man einen Seitenfehler oder Segmentfehler).
Das Betriebssystem fängt diese Ausnahme ab, lädt den fehlenden Teil (Seite oder Segment) vom externen Speicher in den Hauptspeicher und aktualisiert die Tabellen. Falls kein freier Platz im Hauptspeicher verfügbar ist, muss zuvor ein anderer, möglichst nicht benötigter Teil auf den externen Speicher ausgelagert werden, um Platz zu schaffen. Nach Abschluss dieses Ladevorgangs wird der ursprünglich unterbrochene Befehl neu gestartet und kann nun erfolgreich auf die Daten zugreifen
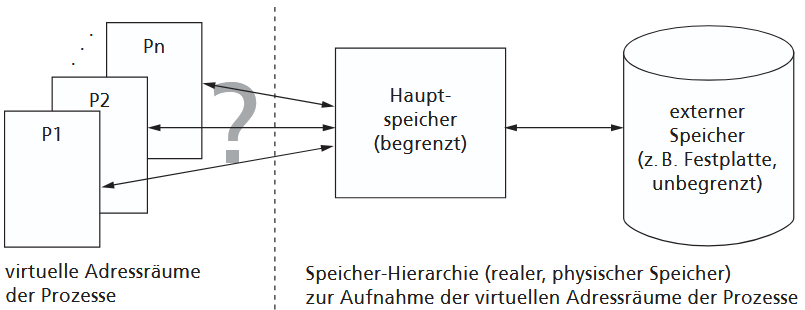
1.6.7 Paging (Seitentechnik)
Beim Paging teilt das Betriebssystem den virtuellen Adressraum eines Prozesses in gleich große Seiten (pages). Der Hauptspeicher wird gleichermaßen in Seitenrahmen (page frames) geteilt; jeder Rahmen kann dabei exakt eine Seite aufnehmen.
Obwohl die Zuteilung von variabel großen Speicherbereichen an Prozessen eine Lösung für die Speicherverwaltung wäre, hat sich bei modernen Betriebssystemen und Prozessoren die Seitentechnik (Paging) primär aufgrund ihrer Einfachheit und Effizienz durchgesetzt. Beim Paging wird sowohl der virtuelle Adressraum eines Prozesses in gleich große Seiten (pages) als auch der Hauptspeicher in gleich große Seitenrahmen (page frames) unterteilt. Jeder Rahmen kann dabei exakt eine Seite aufnehmen.
Jede logische Seite kann flexibel in einen beliebigen freien Frame geladen werden. Befindet sich im Seitentabelleneintrag keine physische Rahmennummer, ist die Seite noch nicht im Arbeitsspeicher vorhanden, tritt ein Page Fault auf. In diesem Fall lädt das Betriebssystem die Seite vom Sekundärspeicher nach und aktualisiert den Tabelleneintrag.
Dieses Verfahren vereinfacht die Verwaltung erheblich, da die "Transporteinheit" für Ein- und Auslagerungen immer eine Seite ist. Es wird dadurch externe Fragmentierung völlig vermieden; es verbleibt lediglich eine durchschnittliche interne Fragmentierung von ½ Seite pro Prozess.
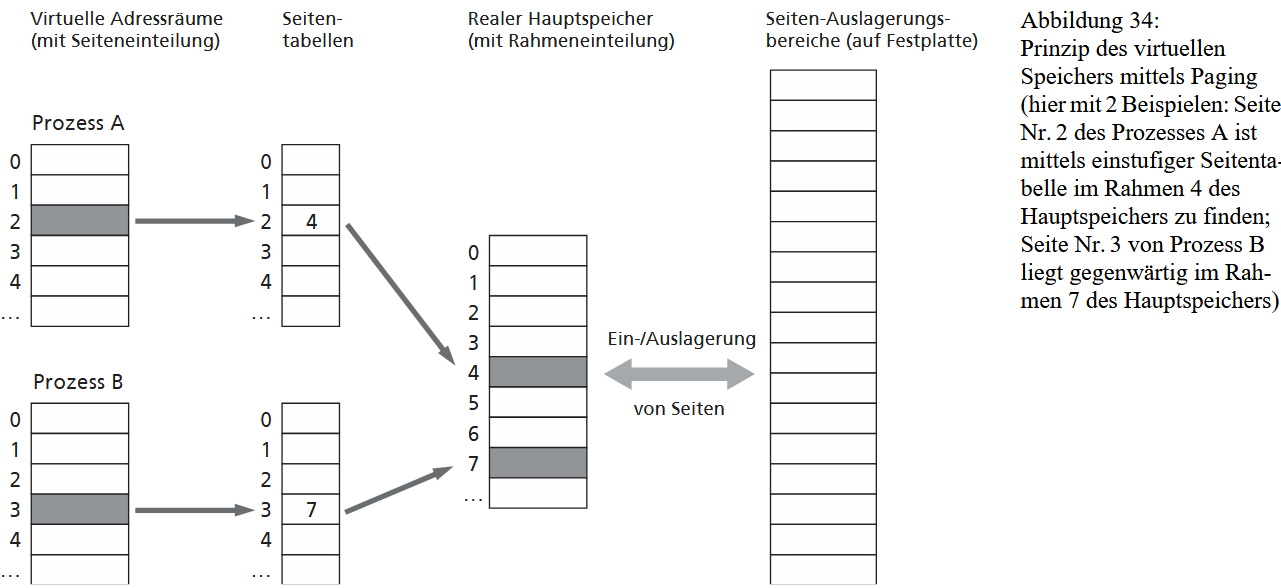
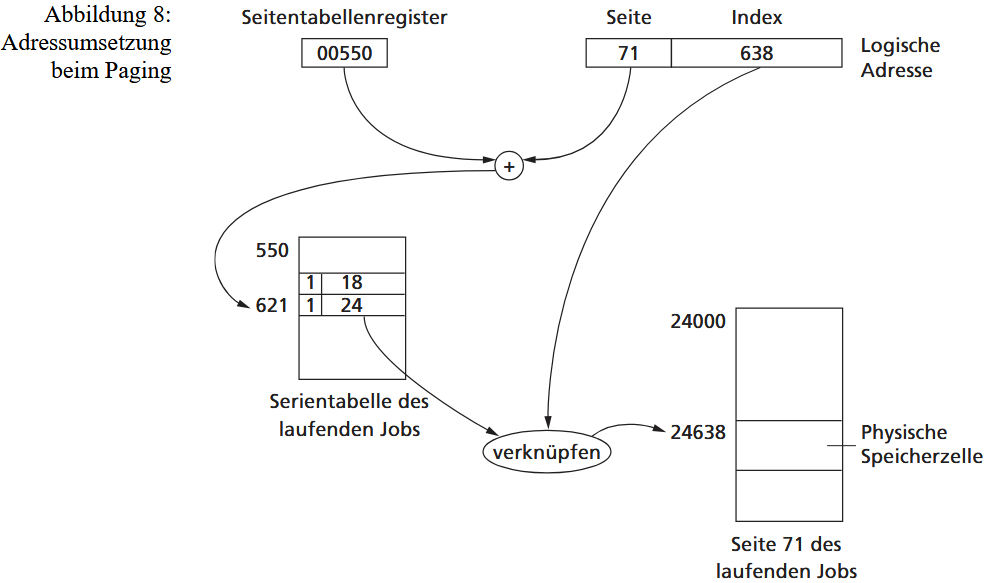
Zur Adressumsetzung zerlegt das Betriebssystem jede virtuelle Adresse in die Seitennummer und ein Offset (Abstand zum Seitenanfang). Die Umwandlung von der virtuellen Adresse [Seitennummer, Offset] in die reale Hauptspeicheradresse [Rahmennummer, Offset] erfolgt dann mithilfe von Seitentabellen (page tables).
Wie die MMU die Adresse umsetzt
- Eingabe (Virtuelle Adresse): [ Seitennummer | Offset ]
- Übersetzung: Die MMU verwendet die Seitennummer, um in der Seitentabelle den zugehörigen Seitenrahmen (Page Frame) zu finden, in dem die Seite physikalisch liegt.
- Ausgabe (Physische Adresse): [ Rahmennummer | Offset ]
Die MMU ersetzt also nur die Seitennummer durch die Rahmennummer und lässt das Offset unverändert. Dadurch wird die virtuelle Adresse in die korrekte physische Adresse umgewandelt.
Die Seitentabelle ist der zentrale Mechanismus des Paging zur Adressumsetzung, wobei die Seitennummer der virtuellen Adresse als Index dient. Jeder Eintrag in der Tabelle enthält entweder die Rahmennummer im physischen Speicher oder eine ungültige Adresse, falls die Seite ausgelagert ist. Ein Präsenzbit kennzeichnet die aktuelle Verfügbarkeit im Hauptspeicher. Durch die Verkettung der gefundenen Rahmennummer mit dem unveränderten Offset der virtuellen Adresse wird die korrekte physische Adresse gebildet. Zusätzliche Bits (z.B. Schutz- oder Modifikations-Bits) dienen der Verwaltung und dem Zugriffsrecht.
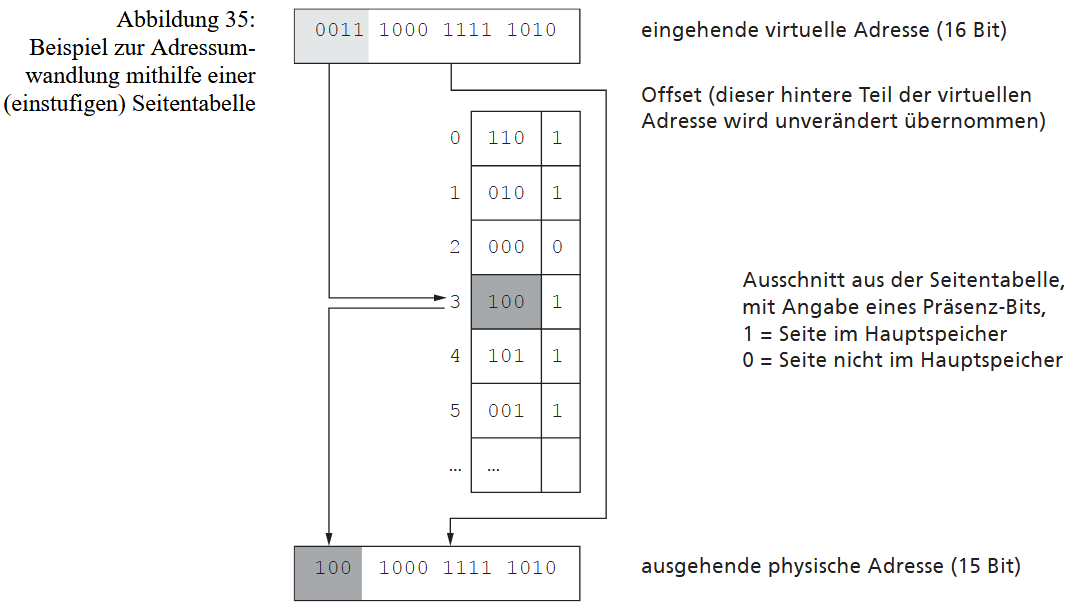
Seitenwechselalorithmus
Bei der virtuellen Speicherverwaltung müssen Seiten oder Segmente nachgeladen werden, wenn sie gerade nicht im Arbeitsspeicher liegen. Dafür muss das Betriebssystem entscheiden, welche alte Seite entfernt werden soll, um Platz für eine neue zu schaffen.
Eine der wichtigsten Methoden dafür ist LRU - Least Recently Used. Dabei wird die Seite ausgewählt, auf die am längsten nicht mehr zugegriffen wurde. Die Idee dahinter: Wenn eine Seite lange ungenutzt war, ist es wahrscheinlich, dass sie auch in Zukunft nicht sofort gebraucht wird. Dadurch trifft man im Durchschnitt bessere Entscheidungen beim Freimachen von Speicherplatz.
Zusätzlich unterscheidet das System zwischen Seiten, die verändert wurden, und solchen, die nur gelesen wurden. Seiten, deren Inhalt nicht verändert wurde, können beim Entfernen sofort überschrieben werden. Seiten, die verändert wurden, müssen dagegen zuerst wieder auf die Festplatte zurückgeschrieben werden. Das kostet Zeit.
Durch das sofortige Überschreiben unveränderter Seiten verkürzt sich die Dauer des Seitenwechsels, was das gesamte System schneller und effizienter macht.

Tabellenlänge und Seitengröße
Da jeder Prozess einen eigenen, sehr großen virtuellen Adressraum (z.B. 64-Bit) besitzt, werden die zugehörigen Seitentabellen gigantisch. Bei einer Seitengröße von 4 KiB sind die Indexanteile der virtuellen Adresse so groß, dass die Tabellen Millionen oder gar Milliarden von Einträgen umfassen würden. Eine Lösung ist die Verwendung größerer Seiten (huge pages, z.B. 2 MiB), was das Problem aber nicht gänzlich beseitigt.
Das Hauptproblem wird durch mehrstufige Tabellen gelöst: Der Indexanteil der virtuellen Adresse wird in mehrere Stufen unterteilt, wobei der Index jeder Stufe auf eine Tabelle der nächsten Stufe verweist. Dies spart Speicher, da nicht genutzte Adressbereiche keine Tabelle der niedrigeren Stufe benötigen.
Da die Adressumsetzung für jeden Speicherzugriff nötig ist und die Tabellen selbst im Hauptspeicher liegen (was einen oder mehrere Zugriffe erfordern würde), wird die Effizienz durch den Translation Look-aside Buffer (TLB) gesichert. Der TLB ist ein schneller Cache innerhalb der MMU, der die Ergebnisse der jüngsten Adressumwandlungen speichert. Nur bei einem TLB Miss erfolgt der langsame Zugriff auf die eigentliche Seitentabelle im Hauptspeicher. Der TLB macht das Paging erst praxistauglich.
- Worin besteht der Unterschied zwischen Swapping und Paging?
- Wie groß kann der virtuelle Adressraum eines Prozesses maximal sein, wenn der Prozessor eine 32-Bit lange virtuelle Adresse liefert?
- Die Einträge in den Seitentabellen beim Paging sind prozessspezifisch, was bedeutet, dass jeder Prozess seine eigene(n) Tabelle(n) hat. Was bedeutet diese Tatsache aber für den TLB und seine Einträge bei einem Prozesswechsel?
1.6.8. Segmentierung
Bei der Segmentierung wird der logische Adressraum eines Programms in Abschnitte variabler Größe unterteilt, die sogenannten Segmente. Diese orientieren sich an den logischen Einheiten des Programms, wie Unterprogramme oder Datenbereiche.
Jede logische Adresse besteht aus einer Segmentnummer und einer Offset-Adresse, die den Abstand zum Beginn des Segments angibt.
Für jedes Segment verwaltet das Betriebssystem die reale Anfangsadresse in einer Segmenttabelle, sodass es genau weiß, wo die einzelnen Programmteile im Arbeitsspeicher liegen.
Im Mehrprogrammbetrieb besitzt jeder Prozess in der Regel eine eigene Tabelle, um Verwechslungen zu vermeiden. Zusätzlich enthält die Tabelle Informationen über die Segmentgröße, sodass unzulässige Speicherzugriffe erkannt und verhindert werden können.
Segmente dienen als kleinste Einheit für den Austausch zwischen Haupt- und Hintergrundspeicher. Wenn kein freier Speicherplatz mehr verfügbar ist, wird ein nicht benötigtes Segment ausgelagert (demand segment swapping).
Die Segmentierung bringt jedoch auch Nachteile mit sich. Externe Fragmentierung entsteht, weil zwischen den geladenen Segmenten Lücken verbleiben, die nicht für neue Segmente genutzt werden können, selbst wenn insgesamt genug freier Speicher vorhanden ist. In solchen Fällen muss das Betriebssystem die Segmente zusammenschieben, was zusätzlichen Aufwand verursacht. Außerdem ist der Austauschalgorithmus komplex und benötigt selbst Speicher und Zeit für die Ausführung, was die Effizienz mindert.
1.7. Ein- und Ausgabe-System
1.7.1. Aufgabe und Struktur
Unter Ein-/Ausgabe (E/A) versteht man alle Vorgänge zum Transport von Daten zwischen Prozessor bzw. Hauptspeicher auf der einen und den angeschlossenen externen Geräten auf der anderen Seite. Das E/A-System hat die Aufgabe, diese Vorgänge zu steuern und zu überwachen. Dabei soll es von konkreten Eigenschaften der Geräte weitgehend abstrahieren und geeignete Schnittstellen anbieten. Es stellt insofern ein typisches Bindeglied zwischen Hard- und Software dar.
Das Ein-/Ausgabe (E/A)-System verdeutlicht den umfangreichen Dienst des Betriebssystems, den Benutzer von technischen Details der Hardware zu entlasten und eine abstrahierte Schnittstelle zu bieten. Dies ist besonders bei der extrem vielfältigen E/A-Hardware (Tastaturen, Drucker, Festplatten, etc.) notwendig. Der Benutzer soll E/A-Operationen unabhängig von den speziellen Geräteeigenschaften durchführen können, ohne sich um Details wie Datencodierung oder Übertragungsgeschwindigkeit kümmern zu müssen. Zum Verständnis der komplexen Architektur des E/A-Systems wird oft ein Schichtenmodell herangezogen.
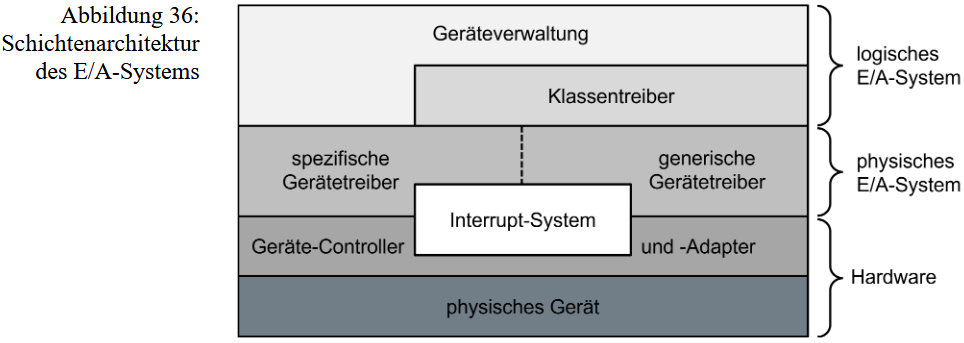
1.7.2 Ein- und Ausgabegeräte
Ein- und Ausgabegeräte (E/A-Geräte) werden meist ins Dateisystem eingebunden und lassen sich für den Anwender wie normale Dateien nutzen, da auf ihnen Lese- und Schreiboperationen ausgeführt werden können. Man unterscheidet reine Ausgabegeräte, reine Eingabegeräte und kombinierte Geräte, die beide Zugriffsarten erlauben.
E/A-Geräte lassen sich grundsätzlich in zwei Kategorien einteilen:
- blockorientierte Geräte, wie Festplatten oder Bänder, arbeiten mit festen Datenblöcken und ermöglichen so eine standardisierte Datenverarbeitung ohne Kenntnis der Hardwaredetails.
- Zeichenorientierte Geräte, wie Terminals, verarbeiten dagegen kontinuierliche Datenströme aus einzelnen Bytes. Einige spezielle Geräte, etwa Timer, lassen sich nicht klar einordnen.
Zur Steuerung der Geräte ist betriebssystemnahe Software notwendig, die aus zwei Ebenen besteht:
- dem Gerätetreiber, der den gerätespezifischen Code enthält und für Initialisierung sowie Lese-/Schreibzugriffe direkt auf den Gerätecontroller zuständig ist, und
- der geräteunabhängigen Betriebssystemsoftware, die eine einheitliche Schnittstelle zum Dateisystem bereitstellt. Diese Schicht übernimmt Aufgaben wie Datenpufferung, Koordination von Lese- und Schreibzugriffen, Geräteschutz, Vergabe exklusiver Zugriffe und Fehlerbehandlung.
Treiber und Schnittstelle abstrahieren die hardwareabhängigen Eigenschaften der Geräte, sodass Anwendungsprogramme standardisiert auf E/A-Ressourcen zugreifen können. Diese Abstraktion ist eine zentrale Aufgabe moderner Betriebssysteme und ermöglicht die einfache Programmierung von Software, ohne dass Details der darunterliegenden Hardware bekannt sein müssen.
Gerätesteuerung
Die Steuerung externer Geräte erfolgt über den Austausch von Statussignalen und Daten zwischen dem Gerät und dem Prozessor. Die dafür zuständige Software sind die Gerätetreiber, deren Komplexität stark vom Verhalten des jeweiligen Geräts abhängt.
Bei der Ein-/Ausgabe gibt es drei gängige Methoden.
- Bei der programmgestützten Ein-/Ausgabe ist die gesamte Steuerung in den Treibern integriert, der Prozessor muss während der Datenübertragung warten, bevor er weitere Aufgaben ausführen kann.
- Um diese Wartezeiten zu vermeiden, nutzt man unterbrechungsgesteuerte Ein-/Ausgabe, bei der der Prozessor nur bei Bedarf durch Interrupts auf Gerätesignale reagiert.
- Für große Datenmengen existiert das DMA-Verfahren (Direct Memory Access). Hier übernimmt die DMA-Steuerung die Datenübertragung zwischen Hauptspeicher und Peripheriegerät ohne Beteiligung der CPU. Dadurch wird die CPU entlastet und kann während der Übertragung andere Aufgaben ausführen. Die Geschwindigkeit des DMA-Betriebs hängt von den Anforderungen des Geräts, der Speicherzykluszeit und der Buskapazität ab.
Exkurs: USB-Farbcodierung als Indikator für Hardware-Fähigkeiten
Um die theoretischen Übertragungsraten der E/A-Hardware (siehe 1.7.3) physikalisch zu unterscheiden, nutzen Hersteller eine standardisierte Farbcodierung der USB-Ports:
- Weiß: USB 1.x (Low Speed 1.5 Mbit/s bis 12 Mbit/s).
- Schwarz: 2.0 (High Speed, bis 480 Mbit/s).
- Blau (Pantone 300C): USB 3.0 / 3.1 Gen 1 (SuperSpeed, bis 5 Gbit/s).
- Rot: USB 3.1 Gen 2 (SuperSpeed+, 10 Gbit/s – 20 Gbit/s).
- Gelb: USB 2.0 und USB 3.0 (Always-On, Passive Power Delivery, 480 Mbit/s – 5 Gbit/s)
- Orange: USB 3.0 Kennzeichnet oft "Always-On" Ports (Stromversorgung auch im Standby des OS = Passive Power Delivery).
Relevanz für das Betriebssystem: Das OS erkennt über den Controller (siehe 1.7.3), welcher Standard vorliegt. Ein blauer Port signalisiert dem Nutzer physikalisch, dass hier die Bandbreite für schnelle Datentransfers (relevant für 1.8 Dateiverwaltung) zur Verfügung steht.
1.7.3. E/A-Hardware und Interruptsystem
E/A-Geräte sind über Bussysteme angeschlossen und arbeiten entweder zeichen- (z. B. Tastatur, Maus) oder blockorientiert (z. B. Festplatte, USB-Stick). Sie werden durch Controller (oder Adapter) gesteuert, die als eigenständige Komponenten oder direkt im Gerät integriert sind. Der Controller bietet Schnittstellen zum Gerät und zum Rechner, organisiert Vorgänge wie Synchronisation und Pufferung, und kommuniziert mit dem Betriebssystem über Register, auf die entweder über E/A-Ports oder Hauptspeicheradressen (Memory-Mapped I/O) zugegriffen wird.
Interrupts sind spezielle Signale, die eine asynchrone Unterbrechung der Arbeit des Prozessors bewirken und durch spezifische Programme (Interrupt Service Routine, ISR) behandelt werden können.
Was genau sind Interrupts?: Interrupts sind Unterbrechungssignale von der Hardware (oder Software) an den Prozessor, die dessen normale Ausführung stoppen und ihn zwingen, sofort eine spezielle Routine zur Behandlung des Ereignisses auszuführen. Sie dienen als grundlegender Mechanismus, damit der Prozessor E/A-Vorgänge starten und sich dann anderen Aufgaben widmen kann, bis ein Signal das Ende der E/A meldet.
Das Interruptsystem spielt eine entscheidende Rolle, indem es den Prozessor von ständigem Abfragen (Polling) entlastet. Der Prozessor stößt einen E/A-Vorgang an und wendet sich anderen Aufgaben zu; der Controller löst einen Interrupt aus, sobald der Vorgang beendet ist. Beim Direkten Speicherzugriff (Direct Memory Access, DMA) wird der Prozessor zusätzlich von der eigentlichen Datenübertragung zwischen dem Gerät und dem Hauptspeicher entlastet. Das Betriebssystem teilt dem Controller lediglich die Anfangsadresse und die Länge des Speicherbereichs mit, den Rest der Übertragung erledigt der Controller selbst.
1.7.4. Physisches Eingabe-/Ausgabesystem
Das physische E/A-System steuert alle E/A-Vorgänge mit den konkret angeschlossenen E/A-Geräten. Diese Vorgänge sind gerätespezifisch und werden durch sogenannte Gerätetreiber (device driver) erbracht.
Der Gerätetreiber dient zur Steuerung eines konkreten E/A-Gerätes und wird daher als physischer Treiber bezeichnet. Zu seinen typischen Aufgaben gehören die Initialisierung des Gerätes, die Vorbereitung und Initiierung von E/A-Operationen, die Übergabe/Übernahme von Daten sowie die Reaktion auf Interrupts und die Energieverwaltung. Der Treiber muss alle Besonderheiten des jeweiligen Gerätes kennen und wird entweder von der darüberliegenden Software oder vom Interruptsystem aktiviert.
Treiber werden von den Hardware-Herstellern als spezifische Treiber zur Verfügung gestellt und sind im Allgemeinen nicht Teil des nativen Kernelcodes. Viele Systeme erlauben das dynamische Nachladen zur Laufzeit, was die Flexibilität erhöht. Obwohl Treiber modular sind und relativ einfach ersetzt werden können, laufen sie bei vielen Betriebssystemen im privilegierten Kernelmodus. Dies macht sie zu einem kritischen Teil des Gesamtsystems, weshalb die Implementierung speziellen "Konstruktionsvorschriften" (Treibermodellen) unterliegt.
1.7.5 Logisches E/A-System
Das logische E/A-System stellt für andere Betriebssystemkomponenten bzw. für Anwendungen Dienste zur geräteunabhängigen Ein-/Ausgabe bereit und benutzt dazu seinerseits Dienste des physischen E/A-Systems.
Das logische E/A-System erfüllt komplexe E/A-Anforderungen, ohne die spezifischen Eigenschaften der peripheren Geräte kennen zu müssen. Typische Aufgaben sind die Vereinheitlichung der Dienste durch die Bildung logischer Geräte (z.B. Plattenlaufwerk für alle Massenspeicher) und die Bereitstellung geräteunabhängiger Dateneinheiten (z.B. Blöcke) sowie deren Pufferung. Dazu zählt auch die zentrale Verwaltung von Geräten, beispielsweise für das Power-Management.
Das logische E/A-System kann weiter in die Geräteverwaltung und Klassentreiber unterteilt sein. Die Geräteverwaltung ist die obere Schicht, die die Gesamtheit der verfügbaren Hardware präsentiert, Statusinformationen bereitstellt und Probleme identifiziert. Klassentreiber hingegen kapseln und zentralisieren Aufgaben für eine gesamte Geräteklasse, wodurch logische Geräte als Repräsentanten für diesen Gerätetyp gebildet werden. Diese Klassentreiber werden oft durch generische Gerätetreiber in der physischen Schicht unterstützt, die Standardfunktionen anbieten und herstellerspezifische Treiber unnötig machen.
Das Konzept von "Plug & Play" ist eng damit verwandt: Die Geräteverwaltung kann neue Hardware über einen Identifizierungscode erkennen und den passenden Treiber zur Laufzeit zuordnen und konfigurieren. Das logische E/A-System kann ferner spezielle E/A-Dienstprozesse außerhalb des Kerns implementieren (Spooling), um langsame Geräte (wie Drucker) von den auftraggebenden Prozessen zu entkoppeln, was gleichzeitig Verklemmungen verhindert.
1.8. Dateiverwaltung
Betriebssysteme stellen eine Komponente zur Verwaltung großer Datenmengen: die Dateiverwaltung. Diese baut auf dem E/A-System.
1.8.1 Dateinkonzept
Was ist eine Datei?
Eine Datei (file) ist eine Menge von logisch zusammengehörenden Daten, die aufeinem geeigneten Medium gespeichert und dort über einen Bezeichner (Dateiname) eindeutig identifiziert werden kann.
Die Dateiverwaltung stellt eine wichtige Abstraktionsschicht des Betriebssystems dar, da der Begriff "Datei" in der darunter liegenden Hardware-Schicht unbekannt ist. Ihre Hauptaufgabe ist es, die Nutzerdaten auf Verwaltungseinheiten abzubilden und Zugriffsverfahren zu den Daten zu realisieren. Zusätzlich ist sie für die Zuordnung und Verwaltung des Speicherplatzes auf den Speichermedien sowie für die Kontrolle des Zugriffsschutzes zuständig.
Wie werden Daten auf einer Festplatte gespeichert?
Eine Festplatte speichert Daten in konzentrischen Spuren (Tracks), die in Sektoren (sectors) unterteilt sind; mehrere Sektoren bilden einen Cluster, der als kleinste praktische Übertragungseinheit zwischen Festplatte und System dient.
- Der Sektor (512 Byte) ist die kleinste Einheit, die die Festplatte physikalisch lesen oder schreiben kann. --> Hardware bezogen
- Der Cluster (auf Deutsch: Block) (4 KiB bzw. 4096 Byte bis 64 KiB)ist die kleinste Einheit, die das Dateisystem (FAT, NTFS) verwaltet. --> Software bezogen (logische zusammenfassung mehrerer physikalischen Speichereinheiten auf der Festplatte)
In der FAT-Tabelle stehen Cluster-Nummern, keine Sektor-Nummern. Das Betriebssystem sagt: "Lies Cluster Nr. 5". Der Festplatten-Treiber rechnet um: "Aha, Cluster 5 entspricht den Sektoren 40 bis 47 auf der Platte" und holt diese.
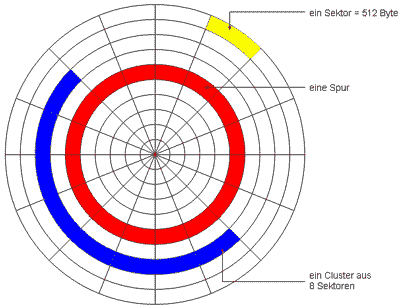
Bevor eine Platte genutzt werden kann, schreibt man durch Formatierung Verwaltungsinformationen wie Spur- und Sektoradressen, Markierungen, Prüfsummen und notwendige Zwischenräume auf das Medium. Beim Zugriff kann der Magnetkopf gezielt auf jede Spur und jeden Sektor positioniert werden, weshalb Festplatten wahlfreien Zugriff bieten. Das Betriebssystem – genauer das Dateisystem – übernimmt die Aufgabe, Dateiinhalte und Dateinamen in diese physische Struktur zu übersetzen und festzulegen, in welchen Spuren, Sektoren und Blöcken die einzelnen Daten abgelegt werden. Dadurch wird die physische Organisation der Platte für den Nutzer vollständig abstrahiert.
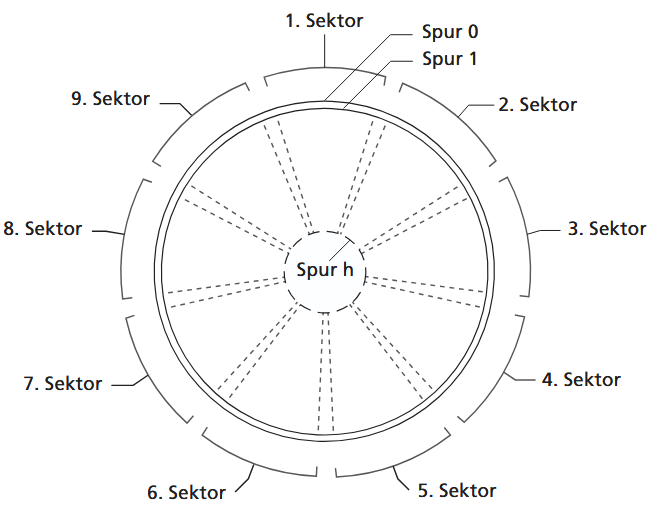
Eine aufwendige Dateiverwaltung ist essenziell,da Daten häufig unabhängig von der Lebenszeit von Prozessen und oft mehreren Prozessen gemeinsam zugänglich gemacht werden sollen. Betriebssysteme nutzen zu diesem Zweck verschiedene Attribute wie die Größe, das Erstellungsdatum, den Besitzer und die Zugriffsrechte.
Zu den konkreten Dateisystemen gehören beispielsweise NTFS (Windows) und ext4 (Linux). Viele Betriebssysteme erlauben die parallele Existenz mehrerer Dateisysteme auf verschiedenen Datenträgern oder Partitionen. Die Regeln zur Gestaltung von Dateinamen (z.B. Unterscheidung zwischen Groß-/Kleinschreibung) variieren dabei je nach konkretem Betriebssystem.
Ein Dateisystem (file system) umfasst die Menge aller von einem Betriebssystem in derselben Weise verwalteten Dateien einschließlich aller dafür benötigten Informationen zu ihrer Verwaltung und Organisation.
1.8.2. Dateisysteme
Ein Dateisystem organisiert Dateien auf einer Festplatte, indem es festlegt, in welchen Spuren und Sektoren die Daten gespeichert werden. Da eine Datei meist aus vielen Sektoren besteht, übernimmt das Dateisystem die „Buchführung“ darüber, welche Sektoren zu welcher Datei gehören, in welcher Reihenfolge sie stehen und welche Sektoren frei oder belegt sind. Dazu verwendet es entweder Freilisten wie die FAT oder verkettete Listen freier Blöcke.
Zusätzlich verwaltet das Dateisystem wichtige Dateiinformationen (Attribute) wie Namen, Größe, Typ, Rechte, Zeitstempel und die belegten Sektoren. Bevor eine Festplatte genutzt werden kann, muss sie partitioniert und anschließend formatiert werden, wodurch mehrere virtuelle Laufwerke (Partitionen) entstehen und die Speicherstruktur eingerichtet wird.
Dateien können unterschiedlich aufgebaut sein:
- als einfache Byte-Folge ohne feste Struktur (typisch in Windows, Linux, Unix),
- als Sammlung gleich großer Datensätze (z. B. in Datenbanksystemen) oder
- als baumartig organisierte Datensätze mit Schlüsseln zur schnellen Suche.
Frühere Systeme erlaubten nur sequenziellen Zugriff, heute unterstützen alle modernen Dateisysteme wahlfreien Zugriff. Dadurch kann das System gezielt an eine beliebige Stelle der Datei springen oder direkt bestimmte Datensätze finden. Moderne Platten- und SSD-Technologien nutzen diese Zugriffsmöglichkeiten vollständig und werden durch aktuelle Betriebssysteme optimal unterstützt.
1.8.3 Dateiorganisation
Die Dateiorganisation beschreibt die Anordnung der Daten und die möglichen Zugriffsformen. Die interne oder logische Struktur einer Datei kann hierbei in zwei Hauptformen vorliegen.
Die einfachste und flexibelste Form ist die Folge von Bytes (Bytestream). Hier wird die Datei als unstrukturierte, fortlaufende Bytefolge betrachtet, die sich an der Organisation des Hauptspeichers orientiert. Dies erlaubt eine einfache Überführung von Dateioperationen in Funktionen des E/A-Systems, wodurch beispielsweise unter UNIX/Linux jedes E/A-Gerät wie eine Datei angesprochen werden kann.
Die alternative Form ist die Folge von Datensätzen (Records). Hier ist die Datei in Sätzen fester (selten) oder variabler Länge strukturiert. Diese effiziente und flexible Struktur wird vor allem in Betriebssystemen für die kommerzielle Datenverarbeitung genutzt, während feste Satzlängen heute kaum noch Anwendung finden.
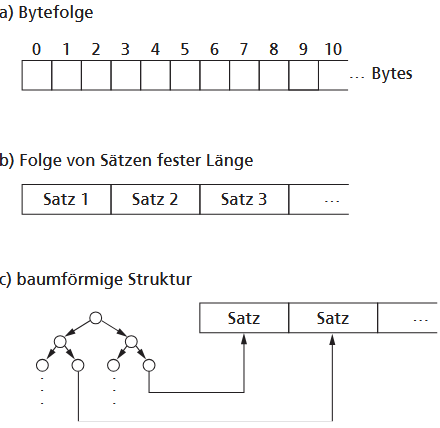
1.8.4. Speicherplatzzuordnung auf externem Speicher
Die Speicherplatzzuordnung auf externen Speichermedien erfolgt in Kooperation mit dem logischen E/A-System. Als Verwaltungseinheit dienen Blöcke fester Größe (Cluster), die typischerweise im Bereich von 1 bis 64 Kibibyte liegen. Die Daten einer Datei werden auf diese Blöcke abgebildet. Für diese Zuordnung und die Verwaltung des freien Speichers werden Verfahren wie verkettete Listen oder Bitmaps genutzt, ähnlich der Hauptspeicherverwaltung.
Zuordnungsverfahren
Die typischen Verfahren zur Zuordnung von Datenblöcken sind:
- Aufeinanderfolgende (Contiguous Files): Die gesamte Datei belegt zusammenhängende Blöcke. Der Zugriff ist schnell, da nur der erste Block und die Blockanzahl benötigt werden. Allerdings muss die maximale Dateigröße vorab bekannt sein, und die Freigabe des Platzes führt zu Fragmentierung.
- Liste aller Blöcke mit interner Verkettung: Der Zeiger auf den nächsten Datenblock ist im Datenblock selbst gespeichert. Dies ergibt nur einen sequenziellen Zugriff, da die Blöcke physisch über die gesamte Platte verstreut sein können.

- Liste aller Blöcke mit externer Verkettung: Die Zeiger werden in einer gesonderten Datenstruktur außerhalb des Datenbereichs gespeichert. Diese Verwaltungsdaten werden oft in den Hauptspeicher geladen, um den Zugriff zu beschleunigen.
Spezifische Verwaltungsstrukturen
Zwei Beispiele für externe Verkettungen sind die File Allocation Table (FAT) und Index Nodes (Inodes).
- FAT: Enthält für jeden Block auf der Platte einen Eintrag, wobei der Eintrag auf den nächsten logischen Block einer Datei verweist.
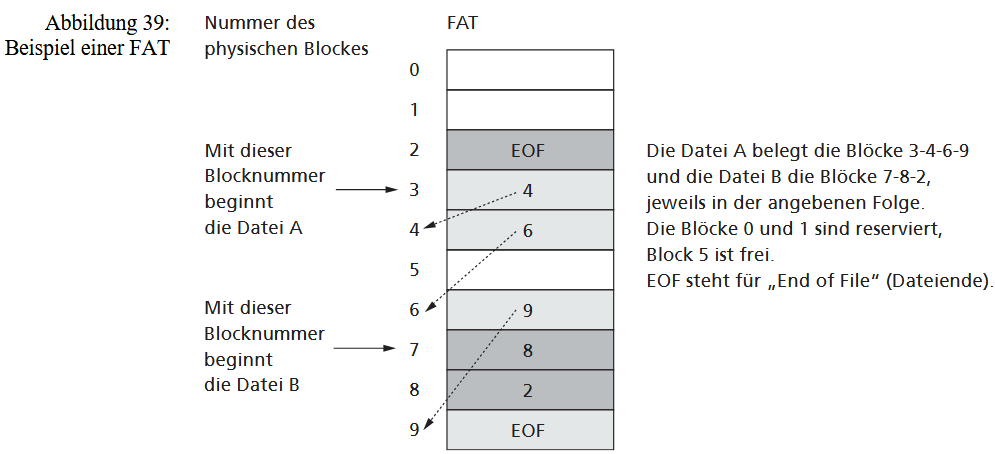
- Inode: Hier wird für jede Datei eine eigene Datenstruktur zur Speicherung von Eigenschaften und der Block-Verkettung genutzt. Um die Inode bei großen Dateien klein zu halten, werden weitere Verkettungsinformationen über einfach oder mehrfach indirekte Verweise in gewöhnliche Plattenblöcke ausgelagert.
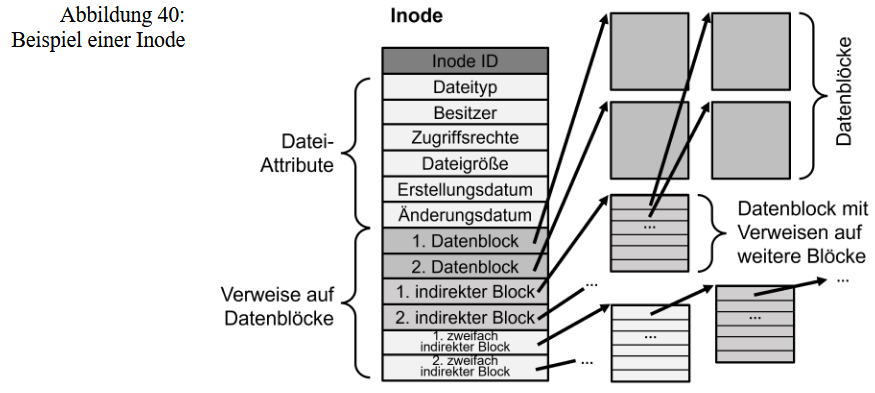
1.8.5 Verzeichnisse
Ein Dateiverzeichnis (Ordner, Katalog, directory) ist eine Datenstruktur, die Informationen über eine Datei enthält und die benötigt wird, um Dateien untereinander logisch zu ordnen und eine effiziente Verwaltung auf dem Datenträger zu unterstützen.
Es bildet eine wichtige Schnittstelle zwischen dem Benutzer und dem Betriebssystem: Für den Benutzer stellt es eine logische Struktur bereit, die völlig unabhängig von der physischen Lage der Dateien ist.
Für die Dateiverwaltung verknüpft das Verzeichnis die vom Benutzer verwendeten Dateinamen mit den internen Verwaltungsstrukturen und den eigentlichen Datenblöcken.
Zu den typischen Eigenschaften, die in einem Verzeichnis gespeichert werden, gehören der Dateiname, Typ, Besitzer, Zugriffsrechte, Größe, Datumsangaben und der Verweis auf die Datenblöcke.
Hard link
Diese Trennung von Name (im Verzeichnis) und Metadaten (in der Inode) ermöglicht es Inode-basierten Systemen, dass mehrere Verzeichniseinträge, auch mit unterschiedlichen Namen, auf dieselbe Inode und somit auf dieselbe Datei verweisen können; ein Verfahren, das als Hard Link bezeichnet wird.
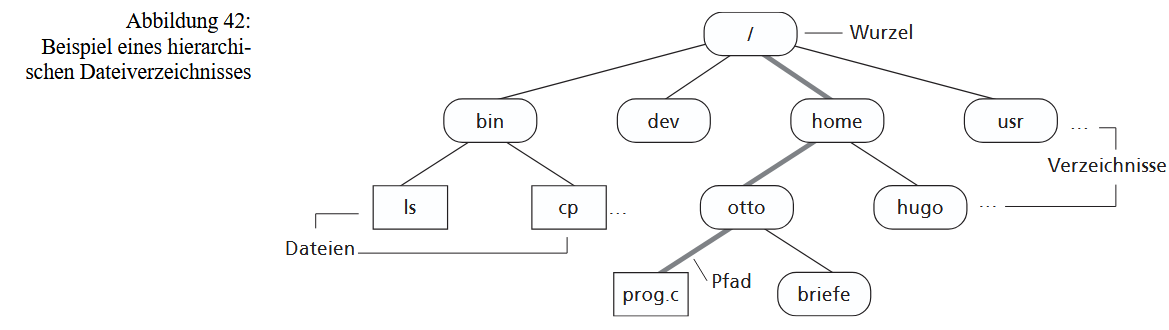
Verzeichnisse, auch Ordner oder Kataloge genannt, fassen mehrere Dateien zu einer logischen Einheit zusammen. Ein Verzeichnis ist selbst eine spezielle Datei, die Informationen über die enthaltenen Dateien speichert, darunter deren Namen und zugehörige Dateiattribute. Verzeichnisse können sowohl normale Dateien als auch weitere Unterverzeichnisse enthalten, wodurch sich eine hierarchische Struktur bildet. An der Spitze dieser Hierarchie steht das Wurzelverzeichnis (root directory).
In Windows-Systemen existiert für jedes Laufwerk ein eigenes Wurzelverzeichnis, gekennzeichnet durch den Laufwerksbuchstaben und Doppelpunkt, z. B. „C:“. Unix-ähnliche Systeme wie Linux, macOS oder FreeBSD besitzen nur ein einziges Root-Verzeichnis, von dem aus alle Dateien und Unterverzeichnisse erreichbar sind.
Um in einem solchen baumartig organisierten Dateisystem eine Datei eindeutig zu identifizieren, reicht der eigentliche Dateiname allein nicht aus. Es muss zusätzlich angegeben werden, in welchem Verzeichnis die Datei liegt. Hierfür werden Pfade verwendet, die den Ort der Datei innerhalb der Verzeichnisstruktur beschreiben.
- Absolute Pfade beginnen beim Wurzelverzeichnis und listen alle Verzeichnisse bis zur Datei auf, wodurch sie immer eindeutig sind.
- Relative Pfade beziehen sich auf das aktuelle Arbeitsverzeichnis des Benutzers und ermöglichen kürzere Pfadangaben, die flexibel zum momentanen Verzeichnis interpretiert werden. In Windows-Systemen wird zur Kennzeichnung von Unterverzeichnissen der Backslash „\“ verwendet, beispielsweise bezeichnet „C:\meier“ das Unterverzeichnis „meier“ auf dem Laufwerk C.
Dateisyteme: CP/M, MS-DOS, UNIX, NTFS, ReFS, EFS
FAT, NFTS Die Art der Speicherung dieser Eigenschaften unterscheidet sich je nach Dateisystem.
- Bei FAT-basierten Systemen werden die meisten dieser Attribute direkt innerhalb des Verzeichniseintrags gespeichert.
- Im Gegensatz dazu enthalten Verzeichniseinträge bei Inode-basierten Dateisystemen (wie ext4 oder ufs) in der Regel nur den Dateinamen und einen Verweis auf die zugehörige Inode. Die Inode selbst ist eine separate Datenstruktur, die alle weiteren Eigenschaften und die Verweise auf die Datenblöcke enthält.
CP/M
Zu Beginn der Entwicklung von Dateisystemen standen einfache Systeme wie CP/M, das nur ein einziges Verzeichnis kannte. Hier bestand das Verzeichnis aus einer Tabelle mit Einträgen fester Länge, in der die Dateien in Blöcken auf der Festplatte gespeichert wurden. War eine Datei länger als 16 Blöcke, wurde ein zweiter Eintrag mit hochgezähltem „Extend“-Feld angelegt. Diese einfache Struktur stieß jedoch schnell an ihre Grenzen, sobald die Anzahl und Größe der Dateien wuchs.
Hierarchisches System: MS-DOS (FAT und FAT32)
Die Lösung war die Einführung hierarchischer Dateisysteme, wie sie beispielsweise in MS-DOS zum Einsatz kamen. Hier enthält ein Verzeichnis nur die erste Blocknummer der Datei, die als Index für die File Allocation Table (FAT) dient, über die die weiteren Blöcke bestimmt werden. Das Wurzelverzeichnis hat eine feste Größe, während Unterverzeichnisse selbst als Dateien behandelt werden. Vor der Nutzung einer Festplatte muss diese partitioniert und formatiert werden, um das Dateisystem einzurichten. Das FAT-System gliedert sich in das Inhaltsverzeichnis, das die Dateinamen und Positionen auf der Platte verwaltet, und den Datenbereich, in dem die Datenblöcke der Dateien unsortiert gespeichert sind.
Mit Windows 95 wurde das FAT-System durch VFAT bzw. FAT32 weiterentwickelt, um längere Dateinamen (bis zu 255 Zeichen) zu unterstützen. FAT32 bietet außerdem eine Pseudounterscheidung zwischen Groß- und Kleinschreibung, wandelt jedoch alte 8+3-Dateinamen in Großbuchstaben um. Moderne Windows-Versionen wie NT, 2000, XP, Vista, 7, 8 und 10 unterstützen zwar noch FAT- und FAT32-Partitionen, sie gelten jedoch als veraltet, insbesondere für Systempartitionen.
Hierarchisches System: UNIX
Unter UNIX wurde ein hierarchisches Dateisystem entwickelt, das auf einer sehr einfachen Struktur basiert. Verzeichnisse sind selbst Dateien, deren Einträge aus dem Dateinamen und einer Nummer bestehen. Diese Nummer verweist auf einen i-node, der alle weiteren Informationen zur Datei enthält und einen festen Platz auf der Festplatte hat. Anders als bei CP/M oder MS-DOS, wo Laufwerke durch Buchstaben und Doppelpunkte gekennzeichnet werden, sind bei UNIX die Platten in das Dateisystem integriert und können an beliebige Unterverzeichnisse angehängt werden. Die Dateinamen waren anfangs auf 14 Zeichen beschränkt, sind heute aber meist deutlich länger.
Hierarchisches System: NTFS
NTFS (New Technology File System) wurde mit Windows NT eingeführt und bietet gegenüber älteren FAT-Systemen erhebliche Verbesserungen. Es unterstützt lange Dateinamen, Unicode-Zeichensätze und sehr große Speicherkapazitäten bis zu 2^64 Bit.
NTFS ermöglicht flexible Clustergrößen und beseitigt damit den bei FAT-Systemen typischen Platzverlust auf großen Festplatten. Sicherheit und Zugriffskontrolle spielen eine zentrale Rolle: Lesen, Schreiben und Löschen von Dateien lassen sich für einzelne Benutzer oder Gruppen gezielt steuern. Das Dateisystem arbeitet transaktionsorientiert bei Metadaten, sodass unvollständige Änderungen nach einem Systemausfall automatisch vervollständigt oder zurückgesetzt werden, um die Integrität zu sichern.
Zentrale Komponente von NTFS ist die Master File Table (MFT), in der jede Datei durch einen Eintrag repräsentiert wird. Die ersten 16 Einträge sind reserviert, z. B. für die MFT selbst, einen MFT-Spiegel oder eine Logdatei zur Wiederherstellung. Ab dem 17. Eintrag folgen die eigentlichen Dateien und Verzeichnisse des Datenträgers. Kleine Dateien oder Verzeichniseinträge können vollständig in der MFT gespeichert werden, größere werden über Suchbäume organisiert, deren Einträge auf externe Cluster zeigen. Jeder Dateieintrag enthält Attribute wie Standardinformationen (z. B. Zeitpunkte der letzten Speicherung), Dateiname, Sicherheitsinformationen (Eigentümer und Zugriffsrechte) und die eigentlichen Daten der Datei.
ReFS (Resilient File System)
ReFS (Resilient File System) wurde mit Windows Server 2012 eingeführt und ergänzt die bisherigen Dateisysteme NTFS und FAT32. Es basiert auf NTFS, soll jedoch robuster, skalierbarer und fehlerresistenter sein. ReFS bietet Kompatibilität mit NTFS-Funktionen, prüft Daten automatisch und korrigiert Fehler, wo möglich. Die Skalierbarkeit ist enorm: Volumen bis 2^78 Byte, Dateien bis 2^64 – 1 Byte und bis zu 2^64 Dateien pro Ordner sind möglich.
Anders als bei früheren Systemen werden alle Informationen – einschließlich Dateien, Verzeichnisse, Metadaten und Dateifragmenten – in verschachtelten Baumstrukturen organisiert. Jedes Verzeichnis verfügt über einen eigenen B+-Baum, was die Verwaltung großer Datenmengen effizient und strukturiert macht und gleichzeitig die Fehlerresistenz erhöht.
EFS
EFS (Encrypting File System) ist ein verschlüsselndes Dateisystem, das Dateien vor unberechtigtem Zugriff schützt. Es arbeitet transparent: Anwendungen greifen auf verschlüsselte Dateien genauso zu wie auf normale Dateien, während EFS die Daten beim Lesen automatisch entschlüsselt und beim Schreiben verschlüsselt. Jede Datei wird mit einem zufällig generierten Dateischlüssel (FEK) verschlüsselt, der seinerseits mit dem öffentlichen Schlüssel des Nutzers „verpackt“ wird. Nur der Besitzer des passenden privaten Schlüssels kann die Datei entschlüsseln. EFS unterstützt auch gemeinsame Nutzung durch mehrere Benutzer und bietet Wiederherstellungsoptionen für verlorene Schlüssel.
BitLocker Drive Encryption ergänzt EFS durch die Verschlüsselung ganzer Festplatten oder Partitionen, inklusive des Betriebssystems. Es verschlüsselt Daten in Echtzeit und nutzt das Trusted Platform Module (TPM) des PCs, um Masterschlüssel sicher zu speichern. Beide Systeme dienen der Datensicherheit, wobei EFS auf Dateiebene arbeitet und BitLocker die gesamte Partition schützt.
Neben Windows-Dateisystemen existieren zahlreiche Dateisysteme für UNIXoide Systeme, wie EXT4 und btrfs für Linux, HFS+ und APFS für macOS, UFS2 für diverse Unix-Varianten sowie ZFS für Solaris und Linux. Moderne Dateisysteme bieten ähnliche Funktionen wie große Dateigrößen, viele Dateien, Journaling und Zuverlässigkeit, Unterschiede zeigen sich meist nur bei Spezialanwendungen wie Datenbanken oder Big Data.
1.8.5. Organisation des Datenträgers
Um beim Systemstart ein Dateisystem korrekt erkennen zu können, setzen Betriebssysteme eine spezifische Strukturierung des Datenträgers voraus. Diese umfasst den Startcode (Boot Code) und Informationen über die Lage der Dateiverwaltungsdaten, die oft in einem speziellen Block (z.B. "Superblock") gespeichert sind. Zu diesen zentralen Daten gehören der Datenträgername, die Strukturen zur Verwaltung freier und belegter Blöcke sowie das Wurzelverzeichnis. Aufgrund ihrer Wichtigkeit werden diese Informationen häufig redundant gespeichert.
Viele Betriebssysteme erlauben die Koexistenz verschiedener Dateisysteme auf einem Datenträger. Dazu werden getrennte Bereiche, sogenannte Partitionen oder logische Laufwerke, eingerichtet. Die notwendigen Informationen über diese Aufteilung werden in einer Partitionstabelle gespeichert, die von speziellen Hilfsprogrammen (Partition Managern) verwaltet wird.
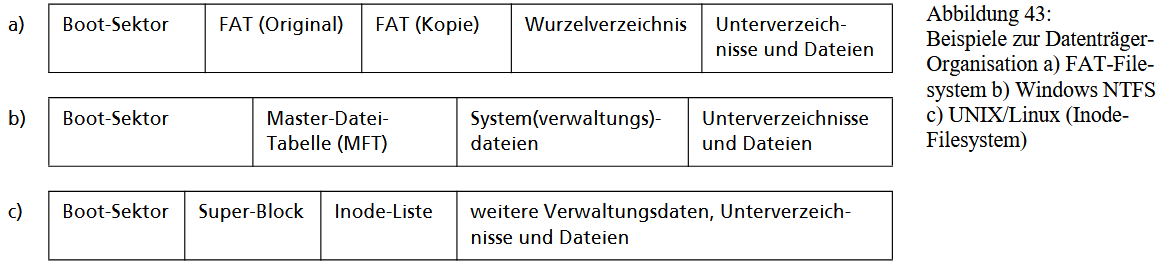
1.8.6. Datensicherheit
Der Datensicherheit kommt eine besondere Bedeutung zu, da der Verlust von Daten, im Gegensatz zu einem reinen Anwendungsabsturz, oft katastrophale wirtschaftliche Schäden nach sich zieht. Betriebssysteme implementieren daher verschiedene Maßnahmen, um die Integrität der Daten zu gewährleisten. Dazu gehört
- die Registrierung fehlerhafter Plattenblöcke, die als defekt erkannt und dauerhaft aus der Verwaltung der freien Blöcke entfernt werden, um eine zukünftige Zuteilung zu verhindern.
- Eine weitere zentrale Maßnahme ist die Sicherung der Konsistenz des Dateisystems. Inkonsistente Zustände, oft verursacht durch unvollständig ausgeführte interne Verwaltungsoperationen (z.B. durch einen Stromausfall), können dazu führen, dass Blöcke "verloren gehen" oder fälschlicherweise mehrfach in Datenstrukturen auftreten. Das wichtigste Verfahren zur Konsistenzsicherung ist die Protokollierung, bekannt als Journaling oder Write-Ahead Logging (WAL). Hierbei wird jede Änderung am Dateisystem wie eine Transaktion behandelt, die vor Beginn im Journal eröffnet und nach erfolgreichem Abschluss geschlossen wird. Bei einem unvorhersehbaren Abbruch ist im Journal exakt vermerkt, welche Transaktion die Inkonsistenz verursacht hat, sodass diese gezielt beseitigt werden kann.
- Darüber hinaus wird die Datensicherheit durch das Cache-Management beeinflusst. Da Daten im Cache aktueller sein können als auf dem Datenträger, müssen Schreiboperationen zuverlässig auf den Datenträger übertragen werden, beispielsweise sofort (Write Through) oder mit kurzer Verzögerung (Write Behind).
- Schließlich bieten Dateisysteme oft eigene Sperrmechanismen wie Datei-Sperren (File Locking) oder Satzsperren (Record Locking) an, um den wechselseitigen Ausschluss bei Dateizugriffen zu sichern und Konkurrenzsituationen zu verwalten.
Datensicherung
Eine wirksame Datensicherung (Backup) ist eine zentrale, wenngleich oft vernachlässigte Aufgabe des Administrators. Sie umfasst das Anlegen einer Kopie oder eines Archivs von Dateien, Verzeichnissen oder ganzen Datenträgern auf einem Ersatzmedium, wie externen Festplatten oder Magnetbändern. Eine effiziente Methode ist die inkrementelle Sicherung, bei der nur die Daten archiviert werden, die sich seit der letzten Sicherung verändert haben. Darüber hinaus existieren komplexe, hardwarebasierte Lösungen wie RAID-Systeme (Redundant Array of Independent Disks), die durch verschiedene Redundanztechniken die Ausfallsicherheit erhöhen und Geschwindigkeitsvorteile bieten können.
Zugriffschutz
Der Zugriffsschutz ist besonders im Mehrbenutzerbetrieb und in Netzwerken entscheidend, um Daten vor Missbrauch oder Zerstörung zu schützen. Die Konzepte hierfür sind vielfältig und beginnen bei der Authentifizierung der Benutzer durch eindeutige Kennungen (Login-Name) und individuelle Passwörter, wodurch Zugriffe einem Benutzerkonto zugeordnet werden. Des Weiteren werden Dateien mit Attributen und Zugriffsrechten (z. B. Lese-, Schreib-, Ausführungsrechte) für unterschiedliche Benutzerklassen ausgestattet. Typische Schutzmaßnahmen sind Zugriffssteuerlisten (ACLs) oder Berechtigungen (Capabilities). Auch die Verschlüsselung gespeicherter Daten dient als wirksames Mittel des Zugriffsschutzes.
Leistungserhöhung
Da Zugriffe auf externe Speicher um Größenordnungen langsamer sind als Hauptspeicherzugriffe, zielt die Leistungserhöhung primär auf die Verminderung von Datenträgerzugriffen ab.
Eine praktische Maßnahme ist die Zwischenpufferung (Caching), um die Zahl der physischen Plattenzugriffe durch Pufferung von Datenblöcken zu minimieren. Dieses Vorgehen ähnelt den Algorithmen der virtuellen Speicherverwaltung.
Eine weitere Maßnahme ist die effiziente Organisation und eine „günstige“ Lage von Verwaltungs- und Benutzerdaten auf dem Datenträger. Dazu können Verwaltungsdaten auch verteilt gruppiert werden, statt sie nur an einer zentralen Stelle zu konzentrieren.
1.8.7. Systemdienste zur Dateiverwaltung
Betriebssysteme bieten für den Programmierer auch durch die API-Schnittstelle Dienste zur Dateiverwaltung. Einige typische Funktionen sind beispielsweise:
CreateFile(): Anlegen einer neuen Datei, Festlegung von Attributen.DeleteFile(): Löschen einer Datei, d. h. Freigabe des belegten externen Speichers und Austragung aus dem Dateiverzeichnis und den anderen Verwaltungsstrukturen.OpenFile(): Vorbereitende Aktionen zur Bearbeitung einer Datei, z. B. Prüfung von Attributen/Rechten, Beschaffung von Informationen zum Datenzugriff (Größe, Lage der Datei).CloseFile(): Abschließen der Bearbeitung einer Datei, z. B. Aktualisierung von Attributen, Rechten und weiteren Verwaltungsinformationen, z. B. in Verzeichnissen.ReadFile(): (fortlaufendes) Lesen von Daten aus der Datei in einen Puffer des Pro- zesses.WriteFile(): (fortlaufendes) Schreiben von Daten aus einem Puffer des Prozesses in die Datei.- ``GetFileAttributes(), SetFileAttributes(): Abfrage bzw. Änderung von Dateiattributen.
1.8.8. Verteilte Dateisysteme
Dateien können in einem Netzwerk auf mehreren Rechnern verteilt sein. Verteilte Dateisysteme ermöglichen den Zugriff auf diesen Datenen von jeden beliebigen Rechner im Netz, weswegen man sie auch Netzwerkdateisysteme bezeichnet.
Wenn es um einen einzigen Prozess im Netzwerk geht, ist ein verteiltes Dateisystem relativ einfach: Eine Datein wird nicht im lokalen Dateisystem angelegt (gelesen, usw.), sondern wird dieser Arbeit an ein anderes Rechnersystem im Netz weitergereicht, das diese Arbeit durchführt.
Wenn mehrere Prozesse (sprich Rechner) auf dieselbe Datei zugreifen sollen, dann ist eine Zusammenarbeit, beispielsweise durch verschiedene Sperrmechanismen von Dateien und durch intensive Kommunikation zwischen den Prozessen erreichen. Ein verteiltes Dateisystem lässt sich unter anderem mithilfe der Interprozesskommunikation implementieren.
Dabei ist der Dateiservice ein eigenständiger Prozess auf der Serverseite.
1.8.9. Virtuelle Dateisysteme
Betriebssysteme müssen oft mehrere Dateisysteme gleichzeitig verwalten, wie eine lokale NTFS-Festplatte und einen externen exFAT-USB-Stick. Während Windows dieses Problem pragmatisch durch die Vergabe von Laufwerksbuchstaben löst, verfolgen UNIX/Linux-Systeme mit dem virtuellen Dateisystem (VFS) ein abstrakteres Konzept. Das VFS integriert alle verschiedenen Dateisysteme in eine einzige, gemeinsame, hierarchische Verzeichnisstruktur.
Das Wurzelverzeichnis des VFS ist typischerweise das der Betriebssystempartition. Andere Dateisysteme, auch von Netzwerken, werden dann an bestimmten Punkten in diesen Verzeichnisbaum "eingehangen" (gemountet). Für den Benutzer wird das spezifische, dahinterliegende Dateisystem abstrahiert und ist beim Navigieren nicht direkt ersichtlich.
Dieses Konzept folgt oft dem Paradigma "everything is a file". Dabei werden nicht nur Dateien und Verzeichnisse, sondern auch Geräte, Netzwerkverbindungen und Interprozesskommunikationskanäle als spezielle Dateien im Verzeichnisbaum repräsentiert. Dadurch werden alle Systemressourcen dem Benutzer auf eine einheitliche Weise zugänglich gemacht.
1.9. Praktischer Einsatz von Betriebssystemen
1.9.1. Installation und Konfigurierung
Die Installation eines Betriebssystems ist die Voraussetzung für die Arbeit mit dem System und beinhaltet die Konfigurierung. Konfigurierung ist die Auswahl und Zusammenstellung von Hardware- und Software-Komponenten, wobei nur die individuell benötigten Teile des Betriebssystems in den Hauptspeicher geladen und zu einer angepassten Form zusammengefügt werden. Die Auswahlentscheidungen trifft das Setup-Programm entweder durch Abfrage des Bedieners oder durch selbstständige Hardware-Erkennung.
Nach der Installation speichert das Betriebssystem die gewählte Konfiguration in speziellen Systemdateien, wie der Registry bei Windows, damit sie bei jedem Neustart sofort bekannt ist und geladen werden kann. Diese Dateien sollten nur mit speziellen Hilfsprogrammen und genauer Kenntnis bearbeitet werden.
Eine Rekonfigurierung ist die nachträgliche Änderung dieser Konfiguration, oft ausgelöst durch Hardware-Änderungen, wie die Installation eines neuen Treibers. Viele Systeme unterstützen dies dank Plug & Play sogar dynamisch zur Laufzeit. Muss die Installation auf vielen Rechnern identisch erfolgen, kann dieser aufwendige Vorgang als "unbeaufsichtigte Installation" (unattended installation) automatisiert werden.
1.9.2 Bootstrapping
Sobald ein Computer eingeschaltet wird, muss das Betriebssystem bereit sein. Dazu muss er aber erst geladen und gestartet werden. Das Betriebssystem selbst steht aber noch nicht zur Verfügung. Wie wird also das Betriebssystem geladen, ohne dass der Benutzer direkt auf die Hardware zugreifen muss?
Das Bootstrapping (Booten / Booting / Boot-Vorgang)
Die technische Lösung heißt Bootstrapping: Ein systemspezifisches Programm wird beim Einschalten des Computers gestartet, das an einer definierten Stellen im ROM des Computers steht (BIOS oder UEFI). Das Programm führt einen Selbsttest (POST, Power On Self Test) ermittelt und speichert die Hardware-Konfiguration und initialisiert wichtige Komponenten, z.B. die Controller. Das Startprogramm hierzu befindet sich in einem eigenen Speicherbereich (ROM oder EPROM) und wird vom Hersteller genau an die aktuelle Hardware des Systems angepasst
Im nächsten Schritt wird der Bootstrap Loader ("Urlader" oder Anfangslader) vom Bootsektor (in der ROM) geladen und gestartet. Dieser lädt Betriebssystemteilen und Konfigurationsdaten vom Datenträger nach. Erst werden Dateien mit definiertem/r Namen/Stelle (z.B. im Wurzelverzeichnis) geladen. Erst durch diese Dateien wird das gesamte Betriebssystem arbeitsbereit, sodass es nun selbst die Steuerung übernehmen kann.
Der Bootloader startet anschließend den Kernel des Betriebssystems, welcher in einem ersten Schritt eine Selbstinitialisierung durchführt. Hierbei werden u.a. das Laden von zusätzlichen Gerätetreibern und Anpassungen an die Hardware vorgenommen sowie das Speichermanagement und der Scheduler vorbereitet und bereitgestellt. Ist der Betriebssystemkern vollständig gestartet und bereit, können Anwendungsprogramme gestartet und vom Betriebssystem verwaltet werden
In Systemen mit mehreren Betriebssystemen (Multi-Boot) liegen diese meist auf verschiedenen Partitionen derselben Festplatte und können beim Start über ein Boot-Programm ausgewählt werden. Dieses Programm erkennt die Speicherorte und die Aufteilung der Festplatte anhand der Partitionstabelle, die sich beispielsweise im Master Boot Record (MBR) befindet.
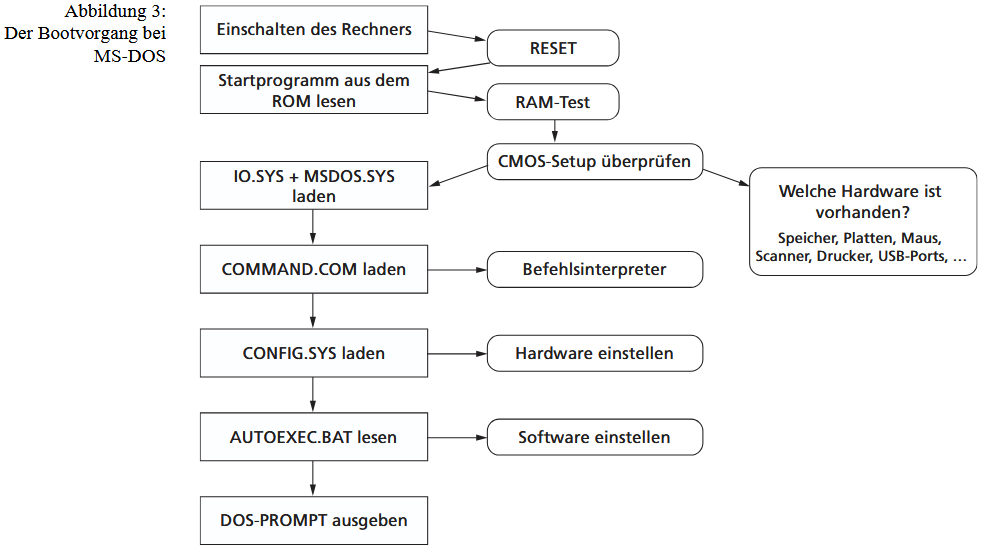
1.9.3. Administration
Im kommerziellen Umfeld übernimmt ein Administrator (super user, Systemverwalter) mit speziellen Zugriffsrechten die Systemverwaltung. Ein Schwerpunkt liegt auf der Wartung und Pflege, was die Installation von Updates und Patches sowie die Konfiguration von Hard- und Software umfasst.
Ein weiterer Kernbereich ist die Benutzerverwaltung, bei der Profile angelegt und Rechte vergeben werden. Gleichzeitig überwacht der Administrator den laufenden Betrieb, kontrolliert Ereignismeldungen, wehrt illegale Zugriffe ab und gewährleistet durch Backups die IT-Sicherheit.
Abschließend fallen organisatorische Aufgaben an. Dazu zählen die Durchführung von Benutzerschulungen, die Erstellung von Dokumentationen, die Unterstützung des Managements durch Berichte sowie die Kontaktpflege zu Herstellern.
1.9.4. Benutzerverwaltung
In Mehrbenutzersystemen erhält jeder Benutzer eine klar abgegrenzte Arbeitsumgebung, damit er von anderen getrennt bleibt und sicher arbeiten kann. Prozesse eines Benutzers dürfen die Prozesse anderer nicht beeinflussen, und auf Dateien kann nur mit ausdrücklicher Berechtigung zugegriffen werden. Für gemeinsam genutzte Ressourcen werden feste Zugriffsrechte vergeben, und auch Nutzungsdauer oder Speicherplatz können begrenzt werden.
Bevor ein Benutzer arbeiten kann, muss er sich beim Login authentisieren, also seine Identität nachweisen. In sicherheitskritischen Umgebungen kann für bestimmte Programme sogar eine zusätzliche Authentisierung erforderlich sein. Viele dieser Schutzmechanismen, wie Prozess- und Dateischutz, sind direkt im Betriebssystem verankert, während der Login-Vorgang über ein eigenes Programm gesteuert wird.
Zusätzlich führt die Benutzerverwaltung Protokolle über Anmeldezeiten, verbrauchte Rechenzeit, Prozesslaufzeiten und genutzte Ressourcen. Diese Daten werden in Logfiles gespeichert und können später statistisch ausgewertet werden.
Authorisierungsarten
Bei der Autorisierung prüft ein System, ob ein Benutzer wirklich zugangsberechtigt ist. Dazu werden unterschiedliche Methoden der Authentifizierung genutzt, die grundsätzlich auf drei Prinzipien beruhen: Wissen, Besitz und Biometrie.
Beim Wissen setzt man auf Passwörter, PINs oder Sicherheitsfragen. Diese Methode ist leicht umzusetzen, aber anfällig für Missbrauch, da solche Informationen gestohlen oder erraten werden können.
Besitz bedeutet, dass der Benutzer ein physisches Token wie eine Smartcard oder einen Sicherheitsschlüssel verwendet. Diese Methode ist komfortabel, fälschungssicherer, aber auch teurer und Tokens können verloren gehen.
Bei Biometrie werden körperliche Merkmale wie Fingerabdrücke oder Gesichtserkennung genutzt. Diese Verfahren sind sehr bequem, da man nichts merken oder mitnehmen muss, und biometrische Merkmale schwer zu kopieren sind. Moderne Geräte wie Smartphones haben diese Technik stark verbreitet.
Passwörte und Multifaktor Authentisierung
Passwörter gelten als kritischer Punkt der Benutzerauthentisierung. Um ihre Sicherheit zu erhöhen, werden sie heute nicht mehr im Klartext gespeichert, sondern mithilfe von Einwegfunktionen – meist kryptografischen Hashfunktionen – in Hashwerte umgewandelt. Diese lassen sich nicht zurückrechnen; bei der Anmeldung wird das eingegebene Passwort erneut gehasht und nur die Hashes werden verglichen. Zusätzlich erhöhen Regeln wie Mindestlängen, das Vermeiden einfacher Wörter, regelmäßige Änderungen und absolute Geheimhaltung die Passwortsicherheit. Trotzdem bleiben Passwörter anfällig, weil ihr Schutz stark vom Verhalten der Benutzer abhängt, das oft nachlässig ist.
Da Passwörter allein nicht mehr ausreichen, setzt man zunehmend auf stärkere Verfahren wie das Challenge-Response-Prinzip. Dabei benötigt der Benutzer ein Token (z. B. SecureID), das nach Eingabe einer persönlichen PIN eine Antwort auf eine zufällig erzeugte Challenge berechnet. Das entstehende Einmalpasswort gilt nur für eine Sitzung und kann nicht wiederverwendet werden, selbst wenn es abgefangen wird. Durch die Kombination von Wissen (PIN) und Besitz (Token) entsteht eine deutlich höhere Sicherheit. Moderne Smartcards übernehmen diese Abläufe weitgehend automatisch: Sie prüfen die PIN oder ein biometrisches Merkmal, berechnen die Response intern und senden sie sicher an das System. Dadurch wird starke Authentisierung einfacher, komfortabler und zuverlässiger.
1.9.5. Bewertung eines Betriebssystems
Zur Bewertung von Betriebssystemen werden zahlreiche Kriterien herangezogen, die verschiedene Aspekte des Systems charakterisieren. Typische Bewertungsgrößen sind:
- Einsatzfähigkeit/Nutzen: Hierzu zählen Hardwareunterstützung, Portabilität, Stabilität, Bedienkomfort sowie Sicherheitskonzepte.
- Qualitative technische Merkmale: Aspekte wie Architektur, Skalierbarkeit, Zuverlässigkeit, Standards und Scheduling-Verfahren.
- Quantitative technische Merkmale: Messbare Werte wie Prozesswechsel-Zeit oder Interrupt-Latenz.
- Wirtschaftliche Größen: Gesamtkosten für Anschaffung, Betrieb und Wartung (TCO).
Für die konkrete Leistungsbewertung (Performance Evaluation), die oft von der Hardware beeinflusst wird, existieren verschiedene methodische Ansätze:
- Messung: Erfassung leistungsrelevanter Daten, oft mittels Benchmarks.
- Analytische Modelle: Mathematische Untersuchung von Strategien, vorrangig für geschlossene Systeme.
- Grafische Modelle: Nutzung z. B. von Petri-Netzen zum Nachweis von Verklemmungsfreiheit.
- Simulation: Nachbildung von Vorgängen zur Identifizierung von Engpässen.
1.9.6. Datenschutz und Sicherheit
Schutzmaßnahmen zur Sicherung von Integrität und Verfügbarkeit sind in modernen Betriebssystemen essenziell, verursachen jedoch einen erheblichen Leistungsaufwand. Zur Realisierung dieser Zugriffskontrolle (Autorisierung) werden alle Einheiten in aktive Subjekte (z.B. Nutzer, Prozesse) und passive Objekte (z.B. Speicherbereiche, Dateien) unterteilt, für die definierte Schutzbereiche gelten.
Wichtige Konzepte sind Zugriffssteuerlisten (ACLs) und Berechtigungen (Capabilities). ACLs legen für jedes Objekt feingranular fest, welcher Benutzer welche Operationen, wie Lesen oder Schreiben, ausführen darf. Capabilities hingegen sind dem Subjekt zugeordnet und definieren dessen Befugnisse gegenüber Objekten.
Zusätzlich stellen Schadprogramme wie Viren und Trojaner eine erhebliche Gefahr dar, weshalb der Einsatz aktueller Viren-Scanner unerlässlich ist. Dennoch bleiben Betriebssysteme anfällig für Sicherheitslücken. Diese entstehen oft durch inkonsistente Systemzustände, undokumentierte Schlupflöcher, fehlerhafte Installationen oder Mängel bei der Benutzeridentifizierung.
1.9.7. Betriebssysteme für spezielle Einsatzgebiete
1.9.7.1. Echtzeit-Betriebssysteme
Der Echtzeit-Betrieb stellt hohe Anforderungen an das zeitliche Verhalten und die Ausfallsicherheit, insbesondere unter Hochlast. Man unterscheidet zwischen harten Echtzeitbedingungen, bei denen Zeitüberschreitungen unter keinen Umständen auftreten dürfen (z. B. Airbag-Steuerung), und weichen Bedingungen, wo geringfügige Verzögerungen tolerierbar sind.
Für die Implementierung solcher Systeme sind spezielle Hardware-Voraussetzungen wie ein Unterbrechungssystem für Interrupts und eine präzise Zeitverwaltung nötig. Beim Scheduling kommen verdrängende Verfahren zum Einsatz, die Fristen berücksichtigen oder Einplanungen garantieren, wie etwa das ratenmonotone Scheduling. Auch die Synchronisation muss mit minimalen Latenzzeiten und Zeitüberwachung erfolgen.
Eingebettete und mobile Systeme müssen oft mit beschränkten Ressourcen auskommen und ROM-fähig sein, um ohne langsame Ladevorgänge zu starten. Zudem werden höchste Robustheit und Stabilität im Dauerbetrieb ohne Bedienereingriffe sowie häufig eine (drahtlose) Netzwerkfähigkeit erwartet.
1.9.7.2. Netzwerk-Betriebssysteme
Netzwerk-Betriebssysteme verwalten in einem Netzwerk gekoppelte Systeme und steuern die Client-Server-Kommunikation. Zentral sind hierbei die verteilte Ressourcennutzung, Lastausgleich sowie Sicherheitskonzepte.
Als Plattformen dienen meist Universalbetriebssysteme wie Windows Server oder Linux, die Mehrnutzerbetrieb unterstützen, oder speziell für Netzwerke optimierte Systeme wie Cisco IOS (Internetwork Operating System Software). Letztere laufen direkt auf den Netzwerkkomponenten (Routern, Switches).
Bei Netzwerkbetriebssystemen unterscheidet man grundsätzlich zwischen dedizierten und nicht-dedizierten Servern.
- Dedizierte Server sind ausschließlich für Serverdienste vorgesehen und können nicht als normale Arbeitsstation genutzt werden.
- Nicht-dedizierte Server erledigen beides gleichzeitig, also Serveraufgaben und Benutzerarbeit.
Während ältere Netzwerkbetriebssysteme stark zentralisiert waren, werden moderne Serverdienste heute meist verteilt betrieben. Statt eines einzigen großen Servers gibt es typischerweise viele spezialisierte Systeme für Dateien, Datenbanken, E-Mail, Webdienste oder bestimmte Anwendungen. Diese Entwicklung hängt auch damit zusammen, dass früher wichtige Netzwerkprotokolle wie TCP/IP nicht überall verfügbar waren; heute sind sie Standard auf allen Systemen.
Da moderne Betriebssysteme nahezu überall Netzwerkfunktionen bereitstellen, kann man sie grundsätzlich alle als Netzwerkbetriebssysteme betrachten – vorausgesetzt, passende Dienste wie Datei- oder Druckfreigaben, Backup oder Kommunikationsdienste sind installiert.
Historische Netzwerkbetriebssysteme waren durch bestimmte Merkmale geprägt, die heutzutage jedoch in allen Systemen üblich sind. Dazu gehören eine Serverplattform, die Kernfunktionen wie Dateisysteme, Prozessverwaltung oder File- und Printdienste bereitstellt, sowie Client-Software, die den Zugriff auf Netzressourcen transparent ermöglicht. Auch Aspekte wie Leistung und Zuverlässigkeit des Netzes – etwa Datendurchsatz, Verkabelung und Netzkomponenten – spielen eine große Rolle. Ebenso wichtig ist die Sicherheit, beispielsweise Passwort- und Dateischutz, Server- und Netzwerksicherheit. Schließlich stützen sich Netzwerkbetriebssysteme auf zahlreiche Standards, etwa für Protokolle, Interprozesskommunikation und Softwarearchitekturen.
Remote Procedure Call (RPC)
Remote Procedure Call (RPC) ist ein Verfahren, das es ermöglicht, Funktionen auf einem entfernten Server so aufzurufen, als wären sie lokal auf dem eigenen Rechner vorhanden. Es wurde in den 1970ern entwickelt und später von Sun Microsystems für NFS genutzt. Ein RPC funktioniert ähnlich wie ein normaler Funktionsaufruf: Eine Anwendung übergibt Parameter, wartet auf ein Ergebnis und arbeitet danach weiter. Der Unterschied besteht darin, dass der Aufruf nicht direkt im eigenen System ausgeführt wird, sondern von der RPC-Bibliothek in ein Nachrichtenpaket umgewandelt und über das Netzwerk an den Server geschickt wird. Dort wird die entsprechende Prozedur ausgeführt, das Ergebnis verpackt und zurückgesendet. Für die Anwendung wirkt dieser entfernte Aufruf jedoch wie ein ganz normaler lokaler Funktionsaufruf, nur dass im Hintergrund Netzwerkkommunikation stattfindet.
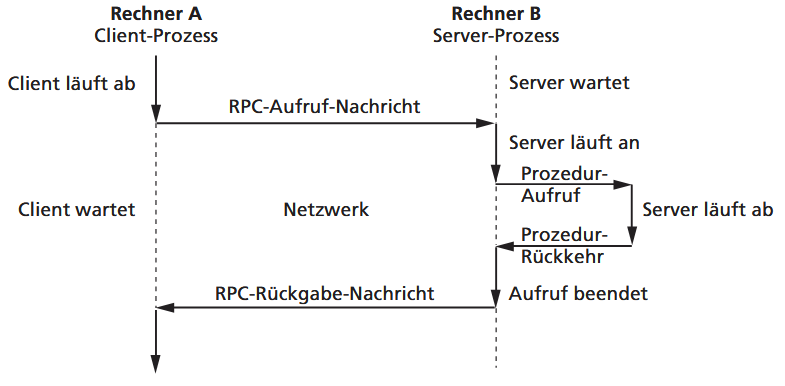
RPC nutzt für den Ablauf sogenannte Stubs (Stellvertreter):
- Client-Aufruf: Das Programm ruft die Funktion auf (z. B. addiere(5, 3)).
- Client-Stub (Marshalling): Ein kleines Stück Software auf dem Client fängt diesen Aufruf ab. Es verpackt den Funktionsnamen und die Parameter (5 und 3) in ein Netzwerkpaket. Diesen Vorgang nennt man Marshalling.
- Übertragung: Das Paket wird über das Netzwerk an den Server geschickt.
- Server-Stub (Unmarshalling): Der Server empfängt das Paket, packt es aus und liest die Parameter.
- Ausführung: Der Server führt die echte Funktion aus.
- Rückweg: Das Ergebnis (z. B. 8) wird verpackt, zurückgeschickt, vom Client-Stub ausgepackt und an das Programm übergeben.
1.9.7.3. Verteilte Systeme
Verteilte Systeme verfolgen das Ziel, dem Benutzer den Eindruck eines homogenen Systems zu vemitteln. Dabei ist auf jedem Rechner dasselbe Betriebssystem installiert oder es gibt eine Middleware (Verteilungskomponente). Verteilte Betriebssysteme weisen einige Besonderheiten und Probleme auf:
- Alle beteiligten Systeme müssen über eine Uhr-Synchronisation verfügen
- Typische IPC-Mittel sind RPC und Sockets
- Es wird im Allgemeinen ein verteiltes Dateisystem für transparenten Zugriff zu FileServern unterstützt, z. B. Network File System (NFS), Hadoop Distributed File System (HDFS)
- In einem verteilten System kann ein Verbindungsweg oder ein Netzknoten ausfallen, daher sind geeignete Gegenmaßnahmen erforderlich.
In Netzwerken ermöglicht transparente Migration die Verlagerung von Dateien, während Replikation durch Kopien die Verfügbarkeit und Fehlertoleranz erhöht. Moderne Parallelrechner sind meist MIMD-Systeme (Multiple Instruction Multiple Data), etwa Cluster unter Linux, bei denen dem Scheduling zur Lastverteilung eine zentrale Rolle zukommt.
Die Architektur wird primär durch die Speicheranbindung unterschieden.
- Bei UMA-Systemen nutzen alle Prozessoren einen physikalisch gemeinsamen Speicher mit einheitlicher Zugriffszeit.
- Im Gegensatz dazu ist bei NUMA der Speicher physikalisch verteilt, wird aber als gemeinsamer logischer Adressraum ("Distributed Shared Memory") präsentiert. Da hier zwischen schnellen lokalen und langsameren fernen Zugriffen unterschieden wird, muss das Scheduling die Prozessor-Affinität berücksichtigen.
- NORMA-Architekturen hingegen, typisch für Supercomputer, verfügen ausschließlich über lokalen Speicher pro Knoten ohne gemeinsamen Zugriff. Auf jedem Knoten läuft ein eigenes Betriebssystem, die Kommunikation erfolgt über Bibliotheken wie MPI. Die Steuerung dieser komplexen Systeme übernimmt in der Regel ein Jobverwaltungssystem auf einer Frontend-Workstation.
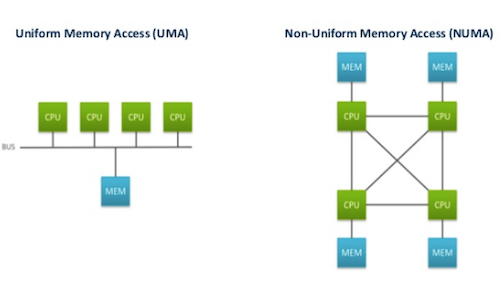
1.10 Virtualisierung
1.10.1. Überblick
Grundsätzlich steht Virtualisierung in der IT für eine Technik, mit deren Hilfe Hard- und/oder Software-Ressourcen aus logischer (virtueller) Sicht zusammengefasst (oder aufgeteilt) werden, um sie den Anforderungen des Benutzers (z. B. hinsichtlich der Auslastung) besser anzupassen. Dem Benutzer wird dadurch eine Abstraktion der Hardware geboten.
Die Virtualisierungstechniken dienen dazu, die physikalische IT-Infrastruktur effizienter, flexibler und sicherer zu nutzen.
Hauptgründe für Virtualisierung
- Serverkonsolidierung: Die Konzentration mehrerer virtueller Server auf einem einzigen physikalischen Server zur Einsparung von Hardware- und Betriebskosten.
- Vereinfachung der Administration: Nutzung spezieller Managementtools zur vereinfachten Bereitstellung und zur Kapselung kritischer Software in sicheren Umgebungen.
- Verfügbarkeitssicherung: Erhöhte Verfügbarkeit durch die Möglichkeit der Migration und Replikation virtueller Systeme.
- Software-Tests: Vereinfachung von Tests durch die Einrichtung unterschiedlicher Betriebsumgebungen ohne zusätzliche physische Hardware.
- Erhalt von Alt-Anwendungen: Sicherstellung der Lauffähigkeit von Legacy-Applikationen auf moderner Hardware.
Methoden zur Realisierung
- Betriebssystem-Virtualisierung: Ausführung mehrerer, potenziell verschiedener, Betriebssysteme auf einer Hardware-Basis.
- Hardware-Virtualisierung: Verwaltung physischer Ressourcen in bedarfsgerechten "Pools" durch Partitionierung.
- Netzwerk-Virtualisierung: Bereitstellung virtueller Netzwerkbereiche (z.B. VLAN oder VPN) auf physischen Netzwerken.
- Software- bzw. Anwendungsvirtualisierung: Virtuelle Installation von Software auf mehreren Rechnern unter Nutzung eines entralen Installationsservers.
1.10.2. Anwendungsvirtualisierung
Die Anwendungsvirtualisierung dient der zentralen Bereitstellung von Software, wobei die Anwendung selbst nicht lokal installiert werden muss. Sie läuft in einer eigens erzeugten, isolierten virtuellen Umgebung, die alle benötigten Dateien und Betriebssystemeinstellungen enthält. Die Software wird dabei "on demand" von einem Installationsserver geladen.
Dieses Konzept reduziert den Administrationsaufwand bei vielen verteilten Computern erheblich, da eine lokale Installation auf allen Systemen entfällt. Im Cloud-Computing wird dies durch das Software as a Service (SaaS)-Paradigma weitergeführt, wobei ganze Anwendungen in die Cloud verlagert und oft nur über einen gängigen Webbrowser als Client zugänglich gemacht werden.
Wesentliche Vorteile der Anwendungsvirtualisierung sind:
- Isolation: Vermeidung von Inkompatibilitäten durch isolierte Ausführung.
- Portabilität: Ausführung der Anwendungen auf verschiedenen Betriebssystemen und Plattformen ohne Anpassung.
- Sicherheit: Verbesserter Schutz vor Schadcode durch isolierte Umgebung.
- Verwaltbarkeit: Vereinfachte und schnelle Aktualisierung durch zentrale Bereitstellung.
- Effizienz: Bessere Auslastung der Systemressourcen und somit Kosteneinsparungen.
1.10.3. Hardwarevirtualisierung
Die Hardwarevirtualisierung ermöglicht es, vormals exklusiv genutzte Ressourcen (wie CPUs oder Speicher) aufzuheben, indem sie durch Partitionierung in kleinere, bedarfsgerechte Einheiten zerlegt werden. Dies dient der Realisierung einer virtuellen Maschine (VM) und erlaubt es, auf einem leistungsstarken Server viele virtuelle Systeme parallel zu betreiben (Serverpartitionierung).
Im Bereich kleinerer Systeme ist besonders die CPU-Partitionierung relevant, die durch Technologien wie Intel VT-x oder AMD-V unterstützt wird. Diese ermöglichen es, Befehle aus Gastsystemen ohne Modifikation durch den Virtual Machine Monitor (VMM) direkt auf dem Prozessor auszuführen, was zeitsparender ist.
Von der Virtualisierung abzugrenzen ist die Emulation. Hierbei wird die komplette Hardwareumgebung mitsamt dem Befehlssatz in Software simuliert, um Programme einer anderen Prozessorarchitektur auszuführen, was jedoch zu erheblichen Leistungseinbußen führen kann.
Hardwarevirtualisierung betrifft generell alle Systemkomponenten. Ziel bei externen Speichersystemen ist die Entkopplung von Verarbeitungs- und Speicherkapazität. Externe Datenspeicher werden logisch getrennt und in einem eigenen Speicherpool konzentriert. Die physischen Verbindungen zwischen Servern und Speichern erfolgen über eigene Netzwerke wie Storage Area Network (SAN) oder Network Attached Storage (NAS).
1.10.4. Betriebssystemvirtualisierung
Die Betriebssystem-Virtualisierung, bekannt seit den 70ern (IBM Mainframes), ermöglicht den parallelen Betrieb mehrerer Betriebssysteminstanzen (Gastsysteme) auf einem Computer. Ein Hypervisor (oder Virtual Machine Monitor, VMM) läuft meist direkt auf der Hardware, verwaltet die Ressourcen und stellt die Umgebung bereit, sodass jedes Gastsystem den Eindruck hat, die Hardware exklusiv zu nutzen.
Hypervisor
Die Betriebssystemvirtualisierung lässt sich unterschiedlich erreichen. Eine Hypervisor-Virtualisierung ist eine sehr mächtige Form der Virtualisierung, gerade, wenn diese in Hardware durch den jeweiligen Prozessor unterstützt wird. In diesem Fall spricht man dann von Vollvirtualisierung.
Hierbei stellt der Hypervisor eine Umgebung bereit, in der unveränderte Gastbetriebssysteme isoliert laufen und über virtuelle Treiber ein Abbild der realen Hardware nutzen. Fehlt diese Hardwareunterstützung, sind Alternativen wie die oft langsamere Emulation des Prozessors oder die Paravirtualisierung nötig. Bei der Paravirtualisierung muss das Gastbetriebssystem jedoch angepasst werden, um spezielle Hypervisor-Aufrufe nutzen zu können.
Bei den Hypervisoren unterscheidet man grundsätzlich zwei Klassen. Typ-1-Hypervisoren (Bare-Metal), wie VMware ESXi, laufen direkt auf der Hardware. Typ-2-Hypervisoren benötigen hingegen ein bereits installiertes Gastgeberbetriebssystem, wie etwa VMware Workstation.
Zusätzlich existieren Hybridlösungen, bei denen das Betriebssystem einen Hypervisor direkt integriert hat. Dabei läuft das Hostsystem selbst unter der Kontrolle dieses Hypervisors, was den parallelen Betrieb weiterer virtueller Maschinen ermöglicht. Bekannte Beispiele für diesen Ansatz sind KVM unter Linux sowie Hyper-V von Microsoft.
Container-Virtualisierung
Die Containervirtualisierung basiert auf der strikten Isolation von Prozessgruppen innerhalb eines einzigen Betriebssystems. Indem jeder Gruppe eine eigene Umgebung (z. B. eigenes Dateisystem, Namensraum, Rechteverwaltung) zugewiesen wird, agieren diese wie in virtuellen Instanzen. Im Gegensatz zu Hypervisor-Lösungen kapselt ein Container eine komplette Laufzeitumgebung, nutzt aber direkt den Kernel des Hostbetriebssystems.
Da kein separates Gastbetriebssystem gestartet werden muss, ist dieser Ansatz deutlich ressourcenschonender. Prozesse laufen weiterhin im Kontext des Hosts, sehen aber nur ihren isolierten Bereich. Rahmenwerke wie Docker nutzen dieses Prinzip, um Anwendungen inklusive aller benötigten Bibliotheken und Werkzeuge in portable Container zu verpacken. Da diese Container nur den Kernel benötigen, lassen sie sich flexibel transportieren und sogar auf anderen Systemen wie Windows ausführen, sofern dort (z. B. via WSL oder Hyper-V) ein kompatibler Linux-Kernel bereitgestellt wird.