Software-Qualitätssicherung
(1) Softwarequalität
(1.1) Begriff und Abgrenzung
(1.1.1) Produkt-, Prozess- und Lebenszyklus-Qualität
Eine umfassende Betrachtung der Softwarequalität geht weit über die bloße Fehlerfreiheit des Programmcodes hinaus. Eine fehlerfreie Ausführung von Testfällen kann zwar auf gute Qualität hindeuten, oft aber auch nur auf unzureichende Tests. Daher erfordert ein professionelles Qualitätsmanagement die Berücksichtigung verschiedener Dimensionen und Betrachtungswinkel.
Die Softwarequalität darf nicht isoliert am Ende der Entwicklung betrachtet werden, sondern muss ganzheitlich verstanden werden. Die wichtigsten Dimensionen umfassen:
-
Produktqualität: Diese bezieht sich nicht nur auf den fehlerfreien Code, sondern auch auf die Qualität der dazugehörigen Begleitdokumente (Artefakte wie Entwickler-, Benutzer- und Systemdokumentationen).
-
Prozessqualität: Die Qualität der Entwicklungsaktivitäten, wie beispielsweise des Testprozesses, ist entscheidend für das Endprodukt.
-
Lebenszyklus-Qualität: Die Qualitätssicherung muss den gesamten Lebenszyklus umfassen, also auch die Erhaltungs- und Evolutionsphasen (Wartung/Maintenance) nach der Auslieferung. Diese Phasen sind oft anspruchsvoller und aufwendiger als die eigentliche Entwicklung.
-
Weitere Faktoren: Bei handelsüblicher Standardsoftware (COTS) müssen zusätzlich die Vertrags- und Produzentenqualität berücksichtigt werden.
(1.1.2.) Sichtweisen des Qualitätsbegriffs
Der Begriff der Qualität wird in der Wirtschaft oft durch das Total Quality Management (TQM) geprägt und erstreckt sich auf alle Aktivitäten der Wertschöpfungskette. Zur genaueren Präzisierung gibt es in der Literatur fünf verschiedene Ansätze:
-
Transzendenter Ansatz: Qualität ist ein universell erkennbares Symptom für hohe Standards, das eher durch Erfahrung empfunden als präzise definiert wird.
-
Produktbezogener Ansatz: Qualität wird als objektiv und präzise messbar angesehen, wie etwa die Fehlerfreiheit eines Produkts.
-
Benutzerbezogener Ansatz: Die Qualität orientiert sich an den Vorstellungen der Nutzer und wird maßgeblich an der Kundenzufriedenheit gemessen.
-
Prozessbezogener Ansatz: Die Qualität wird durch die strikte Einhaltung der Spezifikationen und Vorgaben im Entwicklungsprozess erreicht.
-
Kosten/Nutzen-bezogener Ansatz: Qualität wird als Kompromiss verstanden und zeichnet sich durch ein optimales Preis-Leistungs-Verhältnis aus.
(1.1.3) DIN/ISO/IEC-Normen zur Softwarequalität
Angesichts der wachsenden wirtschaftlichen und gesellschaftlichen Bedeutung von Software existieren zahlreiche internationale Standards und Normen von Organisationen wie ISO, IEC, DIN oder IEEE. Diese Normentwürfe lassen sich in unterschiedliche Bereiche wie Begriffs-, Produkt-, Prozess-, Verfahrens- und Vertragsnormen gliedern.
Wichtige Rahmennormen sind unter anderem die ISO/IEC 25000-Serie (SQuaRE) für die Bewertung von Softwareprodukten, die ISO-9000-Serie für das Qualitätsmanagement sowie SPICE (ISO/IEC 15504) für Entwicklungsprozesse. Die DIN- und ISO-Normen definieren die Produktqualität als die Gesamtheit aller Merkmale eines Softwareproduktes, die sich auf dessen Eignung beziehen, festgelegte oder vorausgesetzte Erfordernisse zu erfüllen. Zur genaueren Bewertung dienen sechs definierte Hauptmerkmale:
- Funktionalität: Das Vorhandensein eines Satzes von Funktionen mit spezifischen Eigenschaften.
- Zuverlässigkeit: Die Fähigkeit der Software, ihr Leistungsniveau unter festgelegten Bedingungen über einen festgelegten Zeitraum aufrechtzuerhalten.
- Benutzbarkeit: Der zur Benutzung erforderliche Aufwand und die individuelle Beurteilung durch die vorausgesetzte Gruppe von Benutzern.
- Effizienz: Das Verhältnis zwischen dem Leistungsniveau der Software und dem Umfang der eingesetzten Betriebsmittel unter festgelegten Bedingungen.
- Änderbarkeit: Der Aufwand, der zur Durchführung vorgegebener Änderungen notwendig ist.
- Übertragbarkeit: Die Eignung der Software, von einer Umgebung in eine andere übertragen zu werden.
(1.1.4) Total Quality Management (TQM)
Den ganzheitlichen, strategischen Handlungsansatz, in dem sowohl der produkt- und prozessbezogene, der benutzer- und mitarbeiterbezogene Ansatz sowie Aspekte des kosten- und nutzenbezogenen Ansatzes zusammengefasst werden, bezeichnet man als Total Quality Management (TQM). TQM umfasst ein Qualitätsbewusstsein und eine Qualitätssicherung in allen Phasen der Wertschöpfungskette, was im Falle der Software die Erstellung und die Instandhaltung betrifft. Dieses Qualitätsbewusstsein sollte bei allen Führungskräften und Mitarbeitern vorhanden sein. Es basiert auf einem Führungskonzept, das auf einer nachhaltigen Kunden- und Mitarbeiterorientierung beruht.
(1.2) Qualitätsmerkmale
(1.2.1) Qualitätsfaktoren und Qualitätskriterien
Die Norm über die grobe Klassifikation von Qualitätsmerkmalen enthält keine überprüfbaren Angaben zur Bewertung der Qualität. Daher müssen die übergeordneten Faktoren weiter in Teilmerkmale beziehungsweise Kriterien verfeinert werden, die sich letztlich bewerten lassen. Dabei können bezüglich unterschiedlicher Faktoren Zielharmonien oder auch Zielkonflikte auftreten. Die Beurteilung und Gewichtung dieser Kriterien kann aus ganz unterschiedlichen Sichtweisen erfolgen, beispielsweise aus der Perspektive des Benutzers, des Entwicklers oder des Software-Managements.
(1.2.2) Qualitätsmodelle
Qualitätsmodelle dienen der Quantifizierung von Merkmalen, um die Produktqualität exakt spezifizieren zu können. Die oberste Ebene bilden die sogenannten Qualitätsfaktoren, welche durch die Angabe von Kriterien operational formuliert werden müssen, wodurch eine Baum- oder Netzstruktur entsteht. Diese Kriterien werden dann durch quantifizierbare Metriken und subjektive Indikatoren gemessen. Ein solches strukturiertes Konstrukt aus Faktoren, Kriterien und Metriken wird als Factor-Criteria-Metrics-Modell (FCM-Qualitätsmodell) bezeichnet. Die eigentliche Bewertung erfolgt dabei ähnlich wie bei einer Nutzwertanalyse. Es ist zu beachten, dass je nach Typ und Anwendungsklasse der Softwarelösung jeweils andere Qualitätsfaktoren dominieren und maßgebend sind.
Eine alternative Methode zur starken Vereinfachung der Qualitätsbeurteilung ist der Goal-Question-Metric-Ansatz (GQM). Hierbei werden die Qualitätsmerkmale so tief detailliert, dass die Beurteilung der Qualität schon durch die Beantwortung einfacher Fragen und das Eintragen von simplen Maßzahlen erfolgen kann. Diese Methode bezeichnet die folgenden Schritte:
- Festlegen der Ziele (Goals)
- Ableiten der Fragen (Questions)
- Wahl der Messverfahren (Metrics)
Die detaillierte Umsetzung in der Praxis ist ein sechsstufiger Prozess. Er beginnt bei der Definition der Auswertungsziele, führt über die Ableitung passender Fragen und Metriken sowie deren Validierung und schließt mit der abschließenden Interpretation der Messergebnisse zur Gesamtbewertung ab.
(1.2.3) Gewichtung von Qualitätsmerkmalen
Die zentrale Herausforderung bei der Nutzung von Qualitätsmodellen besteht darin, die verschiedenen Qualitätsfaktoren und -kriterien für eine Messung zu gewichten und den Erfüllungsgrad zu bewerten. Die Wahl dieser Gewichte wird maßgeblich von zwei Einflüssen bestimmt: Zum einen hängt die Gewichtung stark vom Anwendungstyp der Software ab, da beispielsweise bei Echtzeitsystemen andere Merkmale dominieren als bei einem Internet-Shop. Zum anderen müssen unterschiedliche, oft subjektive Sichtweisen berücksichtigt werden, etwa von Entwicklern, Benutzern, Auftraggebern oder Wartungsingenieuren.
Um die Auswahl und Verteilung der Gewichte für alle Beteiligten transparent und nachvollziehbar zu machen, wird der Einsatz eines Vier-Punkte-Schemas im Rahmen eines unmittelbaren Paarvergleichs vorgeschlagen. Hierbei werden jeweils zwei Qualitätsfaktoren direkt miteinander verglichen und mit Punkten von 0 bis 4 bewertet, wobei 4 Punkte eine absolute Dominanz und 2 Punkte eine Gleichwertigkeit ausdrücken. Die Ergebnisse dieser Paarvergleiche werden in einer Präferenzmatrix zusammengefasst, aus deren Zeilensummen sich schließlich die relativen Gewichte der einzelnen Faktoren bestimmen lassen.
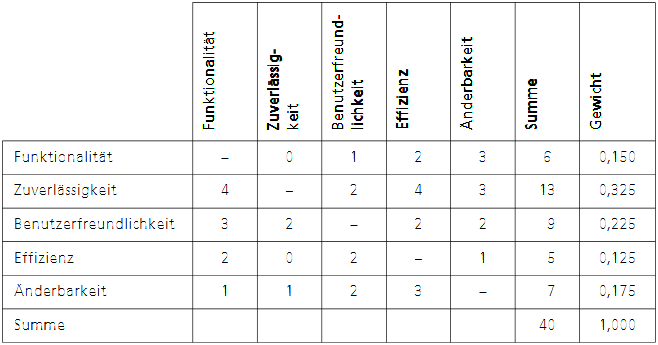
Dieser Prozess kann für die Unterziele (Qualitätskriterien) fortgesetzt werden, wobei die Gewichte auf das Gesamtgewicht des jeweiligen Hauptmerkmals normiert werden. Wird der Erfüllungsgrad für jedes Kriterium mit einem Wert zwischen 0 und 1 gemessen oder bestimmt, erhält man am Ende ein quantifizierbares Qualitätsmaß für das Softwareprodukt.
Hier ist die Zusammenfassung der Kapitel 2 bis 2.1.4, formatiert im Markdown-Layout deiner Dokumentation:
(2) Qualitätssicherung und Qualitätsmanagement
Um Produktqualität zu erzeugen und Prozessqualität dauerhaft zu überwachen, müssen die theoretischen Qualitätsanforderungen in die Praxis umgesetzt werden. In der Softwareentwicklung ist Qualitätssicherung ein individueller Prozess, da Software meist als Einzelprodukt (Prototyp) und nicht in Serie gefertigt wird. Die Aufgaben des Qualitätsmanagements umfassen dabei die Wahrung der Qualitätssicherung sowie die gezielte Qualitätslenkung.
(2.1) Elemente eines Qualitätssicherungssystems
Ein Qualitätssicherungssystem bildet den übergeordneten Rahmen für alle Strategien und Maßnahmen zur Erfüllung von Qualitätsanforderungen. Es setzt sich aus den vier Kernkomponenten Qualitätsmanagement, Qualitätssicherung, Qualitätslenkung und Qualitätsführung zusammen.
(2.1.1) Qualitätsmanagement (QM)
Das Qualitätsmanagement umfasst die gesamte Führungsaufgabe zur Festlegung von Qualitätspolitik, Zielen und Verantwortlichkeiten. Es wird in zwei wesentliche Bereiche unterteilt:
-
Produktorientiertes QM: Es befasst sich mit der Prüfung von Zwischen- und Endprodukten hinsichtlich der Einhaltung definierter Merkmale wie Funktionalität, Zuverlässigkeit oder Änderbarkeit.
-
Prozessorientiertes QM: Dieser Bereich konzentriert sich auf den Entwicklungsprozess selbst. Er umfasst die Wahl der Vorgehensmodelle, Werkzeuge und Standards sowie die Motivation der Mitarbeiter zur Schaffung eines Qualitätsbewusstseins.
(2.1.2) Qualitätssicherung (QS)
Die Qualitätssicherung beinhaltet alle geplanten und systematischen Tätigkeiten, die notwendig sind, um Vertrauen in die Erfüllung der Qualitätsanforderungen zu schaffen. Sie dient dazu, gegenüber Entwicklern und Kunden den Nachweis zu erbringen, dass die geforderte Güte erreicht wird. In der Softwareentwicklung geschieht dies primär durch analytische Maßnahmen.
(2.1.3) Qualitätslenkung (QL)
Die Qualitätslenkung umfasst die konkreten Arbeitstechniken und Tätigkeiten, die zur Erfüllung der Qualitätsanforderungen führen. Sie bezieht sich überwiegend auf die Festlegung und Überwachung konstruktiver Maßnahmen innerhalb des Entwicklungsprozesses.
(2.1.4) Qualitätsführung (QF)
Die Qualitätsführung dient der psychologischen Qualitätssicherung innerhalb eines Teams. Durch die Beeinflussung der Arbeitsatmosphäre wird die Motivation der Mitarbeiter gefördert und eine nachhaltige Qualitätskultur im Unternehmen geschaffen.
Hier ist die Fortführung deiner Dokumentation für die Kapitel 2.2 bis 2.2.2 unter Berücksichtigung der Regel, Bulletpoints nur bei Vorhandensein im Originaltext zu verwenden:
(2.2) Methoden der Qualitätssicherung
Im Qualitätsmanagement werden zwei grundlegende Ausrichtungen unterschieden: die konstruktiven Methoden und die analytischen Methoden. Vereinfacht lässt sich festhalten, dass mit konstruktiven Methoden die Softwarequalität produziert und mit analytischen Methoden die Softwarequalität überprüft wird. Beide Ansätze sind voneinander abhängig und ergänzen sich; ein hoher Aufwand in konstruktiven Maßnahmen reduziert in der Regel die Notwendigkeit für umfangreiche analytische Prüfverfahren.
(2.2.1) Konstruktive Methoden der Qualitätssicherung
Konstruktive Methoden stellen sicher, dass das Softwareprodukt und der Entwicklungsprozess bestimmte geforderte Eigenschaften von vornherein besitzen. Sie werden durch technische oder organisatorische Maßnahmen realisiert. Technische Maßnahmen beziehen sich auf den Einsatz von:
- Methoden (z. B. objektorientierte Programmierung, Strukturierte Analyse).
- Programmiersprachen und Programmierrichtlinien (z. B. Verwendung von Java, Verbot von Goto-Befehlen, Standardisierung der Namensvergabe).
- Werkzeugen (z. B. CASE-Tools, Testwerkzeuge, Debugger).
Die organisatorischen Maßnahmen stützen sich auf die Nutzung von:
- Richtlinien (z. B. Wahl des Vorgehensmodells, Dokumentations- und Kommentierungsrichtlinien, Verbot von Trickprogrammierung).
- Standards (z. B. für Variablenbezeichnungen, Fehlerbehandlung, Schnittstellenaufbau, Testcode).
- Checklisten (z. B. zur Überprüfung der Einhaltung von Qualitätsstandards).
(2.2.2) Analytische Methoden der Qualitätssicherung
Das Ziel analytischer Methoden ist die nachträgliche Prüfung und Bewertung der Qualität von Prüfobjekten wie Programmcode oder Artefakten. Hierbei wird zwischen drei Verfahrensgruppen unterschieden:
Die analysierenden Verfahren verzichten auf eine explizite Programmausführung und erheben stattdessen systematisch Informationen über die Software, wozu insbesondere manuelle Prüfmethoden wie Review, Code-Inspektion, Walkthrough, Durchsprache und Audit gehören.
Die testenden Verfahren basieren auf der Ausführung der Programme unter wechselnden Bedingungen. Dazu zählen dynamische und statische Testverfahren, Simulationen sowie manuell durchgeführte Schreibtischtests.
Mit verifizierenden Verfahren wird versucht, die Korrektheit eines Programms formal nachzuweisen, was jedoch in der Praxis nur in Ausnahmefällen gelingt.
(2.3) Aufgaben des Qualitätsmanagements
Das Qualitätsmanagement (QM) übernimmt eine zentrale Steuerungs- und Überwachungsfunktion im Software-Entwicklungsprozess. Seine Kernaufgaben gliedern sich in Planung, Lenkung, Prüfung sowie die abschließende Dokumentation der Qualitätssicherung.
(2.3.1) Qualitätsplanung
Die Qualitätsplanung hat zum Ziel, die Qualitätsanforderungen an das Produkt und den Prozess in einer überprüfbaren Form zu spezifizieren und diese mit dem Auftraggeber abzustimmen. Hierbei müssen relevante Qualitätsmerkmale festgelegt, gewichtet und durch konkrete Indikatoren oder Metriken messbar gemacht werden. Basierend auf der Art des Produkts und den gesetzten Prioritäten werden allgemeine sowie produktspezifische Maßnahmen zur Qualitätslenkung und -sicherung abgeleitet. Zudem können Messpunkte im Entwicklungsprozess definiert werden, deren Zwischenergebnisse zur Vorhersage der Zielerreichung oder zur Prozessverbesserung dienen.
(2.3.2) Qualitätslenkung und -sicherung
Dieses Teilgebiet fungiert als Controlling-Prozess mit dem Ziel, die Festlegungen der Qualitätsplanung durchzusetzen und zu überwachen. Die Grundlage bildet ein Soll-Ist-Vergleich über den tatsächlichen Einsatz der geplanten konstruktiven und analytischen Methoden. Bei unzureichender Umsetzung müssen entsprechende organisatorische oder technische Korrekturmaßnahmen eingeleitet werden.
(2.3.3) Qualitätsprüfung
Die Qualitätsprüfung führt die analytischen Verfahren durch und überwacht die Umsetzung konstruktiver Maßnahmen. Zu ihren Tätigkeiten gehören:
- Erhebung von Messdaten und Festlegung der Messwerkzeuge (z. B. durch Formulare, Interviews, dynamische Tests des Programmverhaltens oder statische Analysen wie Code-Inspektionen und Reviews).
- Fehleranalyse zur Identifikation von Mängeln in der Qualitätssicherung.
Die Aufbereitung dieser Fehler in Berichten (Software Problem Reports, SPR) ermöglicht eine Ursachenanalyse, um festzustellen, in welchen Phasen Fehler gehäuft auftreten, ob es typische Wiederholungsfehler gibt und wie hoch die Dunkelziffer unentdeckter Fehler in der Software einzuschätzen ist.
(2.3.4) Dokumentation der Qualitätssicherung
Sämtliche Aktivitäten der Planung, Lenkung und Prüfung werden in einem Qualitätssicherungsplan (QS-Plan) dokumentiert. Dieser sollte folgende wesentliche Angaben enthalten:
- Prüfobjekte: Angabe der relevanten Merkmale, Prioritäten und Metriken.
- Zeitplan: Festlegung, wann und wie oft Maßnahmen durchgeführt werden.
- Methodik: Beschreibung der eingesetzten Techniken und analytischen Methoden (z. B. Testformen, Inspektionen).
- Verantwortlichkeiten: Organisatorische Festlegung, wer die Maßnahmen durchführt.
- Kostenrahmen: Das Budget für die Qualitätssicherung sollte in einem angemessenen Verhältnis zur Gesamtentwicklung stehen, wobei in der Praxis oft Veältnisse zwischen 15:85 und 20:80 angestrebt werden.
(2.4) Prinzipien der Qualitätssicherung
Die Qualitätssicherung sollte sich von sieben Grundsätzen leiten lassen und strikt auf deren Einhaltung bestehen.
-
Prinzip der produkt- und prozessabhängigen Qualitätszielbestimmung: Qualitätsziele sollten vor Beginn der Software-Entwicklung explizit sowie nachprüfbar formuliert und sowohl prozess- als auch produktabhängig bestimmt werden.
-
Prinzip der quantitativen Qualitätssicherung: Unter Verwendung von Software-Metriken sollte die Qualitätssicherung so weit wie möglich quantifiziert werden, um einen Soll-Ist-Vergleich zu erleichtern. Da keine allgemeingültigen Metriken existieren, müssen diese jeweils kontextbezogen ausgewählt werden.
-
Prinzip der maximalen konstruktiven Qualitätssicherung: Das Hauptgewicht sollte auf konstruktive Maßnahmen zur Verbesserung des Entwicklungsprozesses sowie auf vorbeugende Maßnahmen zur Fehlervermeidung gelegt werden.
-
Prinzip der möglichst frühzeitigen Fehlerentdeckung und -behebung: Durch laufende Überprüfungs- und Testmaßnahmen sollen Fehler so früh wie möglich entdeckt werden. Die Zeitspanne zwischen Entstehung und Entdeckung eines Fehlers wird als Latenzzeit bezeichnet. Hierbei gilt der Grundsatz, dass die Kosten für die Fehlerbehebung mit zunehmender Latenzzeit drastisch beziehungsweise exponentiell anwachsen.
-
Prinzip der prozessbegleitenden, integrierten Qualitätssicherung: Qualitätssicherung darf nicht erst am Ende der Entwicklung stehen, sondern muss als integraler Teil des gesamten Prozesses aufgefasst werden. Dies fördert das Qualitätsbewusstsein, macht die Qualität jederzeit sichtbar und erleichtert realistische Schätzungen des Projektfortschritts.
-
Prinzip der Unabhängigkeit der Qualitätssicherung: Es wird eine personelle Trennung zwischen der Entwicklung (Entwurf und Implementierung) und der Qualitätssicherung empfohlen. Eine unabhängige Prüfung gewährleistet Objektivität, fördert das Qualitätsbewusstsein der Entwickler und ermöglicht Qualitätsvergleiche über verschiedene Produkte hinweg.
-
Prinzip der Vermeidung der Überwälzung von Qualitätssicherungskosten: Da Zeit- und Kostenziele leichter quantifizierbar sind als Qualitätsziele, besteht oft die Gefahr, unter Termindruck an der Qualitätssicherung zu sparen. Da Qualitätsmängel meist erst spät sichtbar werden, führt dies zu einer Kostenüberwälzung auf spätere Phasen oder die Wartung. Das Qualitätsmanagement muss daher auch bei hohem Druck auf der Einhaltung dieser Prinzipien bestehen, da Qualitätssicherung nicht verhandelbar sein sollte.
(3) Produktorientiertes Qualitätsmanagement
Das produktorientierte Qualitätsmanagement stützt sich bei der Qualitätssicherung auf konstruktive und analytische Maßnahmen. Dabei werden Produkte und Teilprodukte entweder entwicklungsbegleitend unterstützt oder im Anschluss an den Prozess diagnostisch untersucht. Im Mittelpunkt stehen Merkmale wie Funktionalität, Zuverlässigkeit sowie (mit Einschränkungen) Änderbarkeit und Wiederverwendbarkeit. Analysiert und getestet wird sowohl die Qualität einzelner Systemkomponenten als auch deren Zusammenwirken im Gesamtsystem.
(3.1) Konstruktive Maßnahmen
Das konstruktive Qualitätsmanagement umfasst ein System von Maßnahmen in technischen und organisatorischen Bereichen. Der technische Bereich befasst sich mit der Auswahl von Methoden, Sprachen und Entwicklungswerkzeugen, während der organisatorische Bereich Vorgehensmodelle, Standards und Checklisten festlegt. Diese Maßnahmen lassen sich den einzelnen Phasen des Wasserfallmodells zuordnen:
- Phasenübergreifend: Dokumentationsstandards, Glossar, Data Dictionary und Entwicklungs-Repository.
- Anforderungsphase: Structured Analysis, Formale Spezifikation und SREM.
- Analysephase: Simulation und Rapid Prototyping.
- Entwurfsphase: Modular Design, Jackson System Development, Programm-Entwurfssprachen, Endliche Automaten, Petri-Netze und Objektorientierter Entwurf.
- Implementierungsphase: Programmierstandards, Defensive, Strukturierte sowie Höhere Programmierung, Language Subsets, Bibliotheken und Generatoren.
- Integrationsphase: Versions- und Konfigurationskontrolle sowie Automatische Systemgenerierung.
(3.2) Analytische Maßnahmen
Analytische Maßnahmen untersuchen das existierende Qualitätsniveau von End-, Zwischen- oder Teilprodukten. Sie haben einen direkten Einfluss auf die Qualität durch das Aufdecken und Beheben von Fehlern sowie einen indirekten Einfluss, indem gewonnene Erkenntnisse zur Verbesserung des Entwicklungsprozesses beitragen. Folgende Verfahrensgruppen kommen zum Einsatz:
- Analysierende (prüfende) Verfahren: Zur Vermessung von Systemkomponenten und zur Überprüfung bestimmter Eigenschaften.
- Testende Verfahren: Zur gezielten Erkennung von Fehlern.
- Verifizierende Verfahren: Zum Beweis der Korrektheit einer Systemkomponente.
Diese Maßnahmen können in jeder Entwicklungsphase eingesetzt werden und beziehen sich nicht nur auf den Programmcode, sondern auch auf Anforderungen, Spezifikationen und das Design. Je nach Fortschritt der Entwicklung verschiebt sich dabei der Fokus der Analyse. Zu den konkreten Verfahren zählen unter anderem Inspektionen, Reviews, statische Fehleranalysen, diverse Testverfahren sowie Beweisverfahren wie die formale Verifikation.
(3.3) Manuelle Prüfverfahren
Prüfmethoden im Rahmen der analytischen Maßnahmen sind diagnostische Verfahren zur Ermittlung des Qualitätsniveaus von Softwareprodukten oder Teilprodukten. Während Syntax-, Form-, Konsistenz- und Vollständigkeitsprüfungen oft maschinell durch Werkzeuge wie CASE-Tools erfolgen können, müssen semantische und logische Prüfungen manuell durchgeführt werden. Diese manuellen Prüfungen werden allgemein als Reviews bezeichnet. Sie dienen dem Auffinden von Fehlern, Defekten, Inkonsistenzen und Unvollständigkeiten in Dokumenten oder Programmlisten (Artefakten), die in den verschiedenen Phasen der Softwareentwicklung anfallen.
(3.3.1) Inspektion
Die Inspektion stellt eine streng formalisierte, manuelle Prüfmethode dar, um schwere Defekte in schriftlichen Unterlagen oder Programmausdrucken anhand von Referenzunterlagen zu entdecken. Die Ziele umfassen die gemeinsame Fehlersuche in einem Team, die Gewinnung von Prozessinformationen zur Verbesserung der Entwicklungsregeln sowie die abschließende Freigabe des Prüfobjekts für nachfolgende Phasen.
Die Durchführung erfolgt in Gruppensitzungen durch ein Team, das aus einem Moderator, dem Autor, einem Protokollführer und ein bis fünf Gutachtern besteht. Der Prozess gliedert sich in die Planung und Vorbereitung, die eigentliche Inspektionssitzung (ähnlich einem Brainstorming zur Fehleridentifikation) sowie die Nachbereitung, bei der der Autor die Defekte behebt. Ein zentrales Dokument ist das Inspektionsprotokoll, das festgestellte Defekte nach Art, Ort und Schwere dokumentiert, ohne preiszugeben, wer den Fehler gefunden hat.
(3.3.2) Review
Die Review-Methode ist weniger formell als die Inspektion und dient dazu, Stärken und Schwächen eines Prüfobjektes anhand von Referenzunterlagen zu ermitteln. Die Zusammensetzung des Teams und die benötigten Unterlagen entsprechen im Wesentlichen denen der Inspektion. In den Gruppensitzungen nimmt der Autor eine eher passive Rolle ein, während die Bewertungen der Gutachter protokolliert werden. Am Ende gibt das Reviewteam eine Empfehlung ab, ob das Produkt akzeptiert oder überarbeitet werden muss.
(3.3.3) Walkthrough
Ein Walkthrough ist eine abgeschwächte Form des Reviews, an der in der Regel nur der Autor und ein Gutachter beteiligt sind. Der Autor präsentiert seine Lösung und stellt beispielsweise den Programmablauf vor, wobei die Prüfung oft nur stichprobenartig erfolgt. Diese Methode dient neben der Fehleraufdeckung auch dem Know-how-Transfer. Ein wesentlicher Effekt ist, dass der Autor durch das explizite Erläutern seiner Lösung oft selbst Schwachstellen entdeckt.
(3.3.4) Bewertung der manuellen Methoden
Manuelle Prüfmethoden sind eine notwendige Ergänzung zu automatisierten Verfahren, da sie Eigenschaften prüfen, die Werkzeuge nicht erfassen können. Ihr Einsatz ist besonders in frühen Phasen effizient, um bis zu 75 % der aufwendigen Entwurfsfehler aufzudecken. Dem hohen Aufwand von bis zu 20 % der Erstellungskosten steht die wirtschaftliche Rechtfertigung durch die frühzeitige Fehlererkennung gegenüber. Zu beachten ist jedoch der psychologische Druck auf den Autor, der seine Arbeit vor Gutachtern verteidigen muss. Zur Wahrung der Neutralität sollten Vorgesetzte nicht an den Teamsitzungen teilnehmen.
Hier ist die Fortführung deiner Dokumentation für die Kapitel 3.4 bis 3.4.3. In diesem Abschnitt gibt es im Originaltext wieder Aufzählungen, die ich entsprechend übernommen habe:
Danke für den Textauszug! Da habe ich mich in der vorherigen Antwort tatsächlich in der Struktur geirrt, da ich die "Anomalienanalyse" und die "Bindungsarten" fälschlicherweise mit Inhalten aus einem späteren Kapitel (das ich im Hinterkopf hatte) vermischt habe.
Hier ist die korrekte Zusammenfassung basierend auf deinem Text, unter Berücksichtigung der Regel "Bulletpoints nur, wenn sie im Original vorhanden sind":
(3.4) Analysierende Verfahren
Neben den manuellen Prüfmethoden vermessen und erfassen analysierende Verfahren bestimmte Eigenschaften von Systemkomponenten. In diesen Verfahren spiegeln sich insbesondere die Prinzipien der Modularisierung und der Objektorientierung (OO) wider. Zu den analysierenden Verfahren gehören:
- die Analyse von Bindungen,
- die Anomalienanalyse,
- die Entwicklung spezieller Metriken sowie
- spezielle Testverfahren zum Testen von OO-Software.
Während manuelle Methoden wie Inspektionen, Reviews und Walkthroughs vor allem Eigenschaften prüfen, die automatische Werkzeuge nicht feststellen können, liegt der Fokus der hier behandelten Punkte zunächst auf der Analyse von Bindungen und Anomalien.
(3.4.1) Analyse der Bindungsarten
Bei der objektorientierten Programmierung muss zwischen Bindungen (Cohesions) und Kopplungen (Couplings) unterschieden werden. Bindungen betrachten die Beziehungen von Funktionen und Daten innerhalb einer Komponente und sind ein Maß für deren Kompaktheit. Kopplungen hingegen beziehen sich auf den Nachrichtenaustausch und die Schnittstellen zwischen Objekten, was im Rahmen von Integrationstests analysiert wird. Ein gutes modulares Design verfolgt das Ziel, die Kopplungen zwischen Komponenten zu minimieren und die Bindungen innerhalb einer Komponente zu maximieren.
Man unterscheidet zwischen funktionalen Bindungen und Bindungen von Datenobjekten oder Klassen. Eine enge funktionale Bindung liegt vor, wenn alle Elemente einer Komponente an einer einzigen, abgeschlossenen Aufgabe mitwirken. Dies ermöglicht eine kontextunabhängige Wiederverwendung, geringe Fehleranfälligkeit sowie leichte Wartbarkeit. Bei Datenobjekten und Klassen besteht eine enge Bindung, wenn die Zugriffsoperationen nur auf einer einzigen Datenstruktur operieren. Dies hat folgende Vor- bzw. Nachteile: V– Unterstützung des Geheimnisprinzips, da die Datenstruktur nur zu einer Datenabstraktion gehört. – Einfache Änderbarkeit, da nur eine Datenstruktur betroffen ist. – Alle Operationen werden auf derselben Datenstruktur ausgeführt. N– Es besteht die Gefahr, dass Zugriffsoperationen miteinander vermengt werden.
(3.4.2) Analyse von Anomalien
Die Anomalienanalyse ist eine statische Untersuchung des Programmcodes, um Fehler in der Ablaufsequenz oder im Datenfluss aufzudecken. Dabei wird der Zustand von Variablen (undefiniert, definiert, verwendet, nicht benutzt) während der Programmschritte analysiert. Anomalien liegen vor, wenn Sequenzen von der Norm abweichen, wie beispielsweise: – u r: Es wird eine undefinierte Variable verwendet. – d d r: Eine Variable wird ohne Referenz durch einen neuen Wert überschrieben. – d u: Eine definierte Variable wird nicht benutzt.
Diese Analyse dient als sinnvolle Ergänzung zu testenden Verfahren, da sie einfach durchzuführen ist, Fehler sicher entdeckt und eine unmittelbare Fehlerlokalisierung erlaubt.
(3.5) Metriken für Komponenten und Systeme
Bindung und Kopplung sind Kriterien zur qualitativen Bewertung von Komponenten und Systemen. Sie drücken zwar die „Güte“ eines Systems aus, liefern aber keine Maßzahlen. Um die Qualitätskriterien auch quantitativ bewerten zu können, greift man auf Software-Metriken zurück, welche Eigenschaften, Qualität und insbesondere die strukturelle Komplexität überprüfen.
Jede Metrik quantifiziert dabei immer nur einen begrenzten Bereich und kann ein Software-System niemals als Ganzes erfassen. Um einen verlässlichen Gesamteindruck zu gewinnen, muss stets eine Gruppe von Metriken sorgfältig zusammengestellt und ausgewertet werden.
(3.5.1) Metriken für Komponenten
Die Komplexität einer Systemkomponente kann sich auf zwei Aspekte beziehen:
-
Semantische Komplexität (inhaltliche Komplexität der Bindungen): Hierfür kann man keine Metrik angeben, da es sich um eine qualitative Beurteilung der Bindungen handelt, die auch auf die Kopplungen ausgedehnt werden kann.
-
Prozedurale Komplexität.
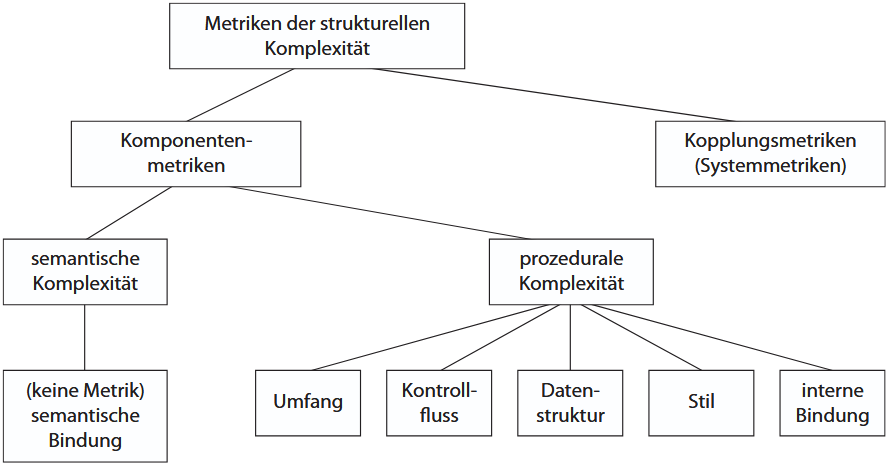
Für die Quantifizierung der prozeduralen Komplexität stehen unterschiedliche Kategorien von Metriken zur Verfügung:
Umfangsmetriken Der Umfang eines Programms und zum Teil auch dessen Komplexität kann beispielsweise mit folgenden Metriken gemessen werden:
- Größe der Programmdatei
- Zahl aller Programmzeilen (LOC: Lines of Code)
- Programmzeilen mit ausführbaren Anweisungen (ELOC: Executable LOC)
- Anzahl der Funktionen
- Halstead-Metrik
- Function-Point-Metrik: Hierbei wird nicht nur der Aufwand, sondern auch die Komplexität berücksichtigt und zwischen Brutto- und Netto-Function-Points (NFP) unterschieden. Die NFP können auch bei der Qualitätssicherung verwendet werden, indem man beispielsweise folgende Maße berechnet:
- Produktivität = NFP / aufgewendete Zeit in Mitarbeitermonaten (MM)
- relative Kosten = Gesamtkosten / NFP
- relative Fehlerrate = Anzahl der aufgetretenen Fehler / NFP
Kontrollflussmetriken Solche Metriken knüpfen an der logischen Struktur des Programms an. Die bekannteste Methode in diesem Bereich ist die McCabe-Metrik.
Datenstrukturmetriken Mit diesen Metriken werden die Anzahl der Variablen, ihre Gültigkeit und Lebensdauer analysiert. Es wird gemessen, ob und wie oft diese Variablen verwendet werden.
Stilmetriken Stilmetriken messen die äußere Form von Programmen (z. B. Einrücken von Anweisungen) und die Konventionen für die Vergabe von Variablenbezeichnungen. Solche Merkmale können nicht objektiv, sondern nur relativ im Vergleich mit dem Programmcode von anderen Komponenten (Vorlagen) gemessen werden.
Bindungsmetriken Diese Metriken analysieren durch Prüfung des Programmcodes die syntaktischen Bindungen (Aufrufe) jeder Systemkomponente. Hieraus kann man das Bindungsverhältnis bestimmen, welches sich aus der Anzahl der funktional gebundenen Komponenten geteilt durch die Gesamtzahl der Komponenten berechnet.
(3.5.2) Halstead-Metrik
Ähnlich wie die Ermittlung der Function-Points liefert auch die Halstead-Metrik ein Maß für den Umfang und die Komplexität eines Programms. Man bestimmt die Zahl der Operatoren (wie Rechenzeichen oder Schlüsselworte) und die Zahl der Operanden (wie Variablen oder Konstanten) und ermittelt daraus die Kenngrößen:
- n1 Anzahl der unterschiedlichen Operatoren,
- n2 Anzahl der unterschiedlichen Operanden,
- N1 Gesamtzahl aller Operatoren im Programm,
- N2 Gesamtzahl aller Operanden im Programm.
Hieraus kann man dann Eigenschaften einer Komponente oder eines Programms wie Vokabular, Programmlänge, Programmvolumen, Schwierigkeitsgrad, Abstraktionslevel und den Programmieraufwand ermitteln.
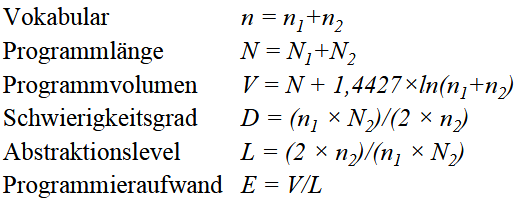
Die Metriken von Halstead können wir folgendermaßen bewerten:
- Sie sind für die Messung des Umfanges und der Komplexität gut geeignet.
- Sie sind einfach (und z. T. automatisch) zu berechnen.
- Sie sind auf alle Programmiersprachen anwendbar.
- Es wird jedoch nur die Implementierung berücksichtigt.
(3.5.3) McCabe-Metrik
Hiermit misst man die strukturelle Komplexität eines Programms. Die Berechnung dieser Metrik stützt sich auf die Betrachtung des Ablaufgrafen (Kontrollflussgrafen) des Programms. Er entsteht, wenn man die im Programm enthaltenen Verzweigungen als Knoten interpretiert und sie durch gerichtete Kanten entsprechend der Programmlogik miteinander verbindet. Man ermittelt hierbei:
- n Anzahl der im Grafen enthaltenen Knoten (nodes),
- e Anzahl der im Grafen enthaltenen Kanten (edges),
- p Anzahl der im Programm benutzten zusammenhängenden Teilkomponenten (Prozeduren).
Die zyklomatische Komplexität V(G) = e - n + 2 * p ermittelt die Zahl der unabhängigen Pfade durch das Programm. Je größer das Maß V(G) ist, desto mehr weicht der Kontrollfluss von dem einfachen linearen Fall ab und desto höher ist die Programmkomplexität. Studien belegen, dass diese Metrik eng mit der Verständlichkeit des Programmcodes korreliert ist. Für die Beurteilung der Komplexität und die Risikobewertung gelten für V(G) bestimmte Klassifikationsgrenzen, die von 1-10 (einfaches Programm, geringes Risiko) bis über 60 (untestbar, extrem hohes Risiko) reichen. McCabe gibt eine Strukturbeschränkung an, die er bei ca. V(G)=15 sieht, was nur in Ausnahmefällen überschritten werden sollte.
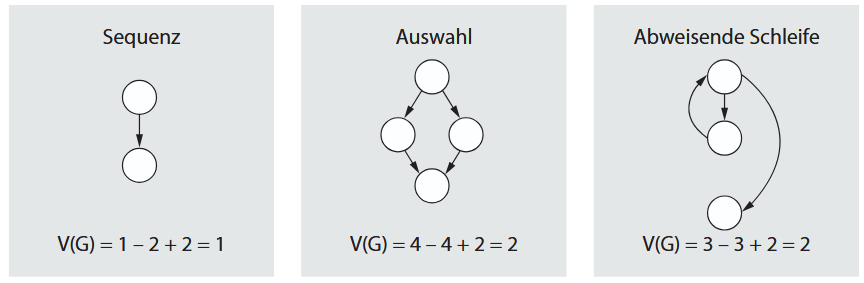
Die McCabe-Metrik ist weit verbreitet. Wir können sie wie folgt bewerten:
- Sie ist einfach zu berechnen.
- Sie hilft die unabhängigen Pfade zu finden und hieraus Testfälle zu konstruieren.
- Es werden nur der Kontrollfluss, nicht der Datenfluss und die Komplexität der Anweisungen und Ausdrücke berücksichtigt.
(3.5.4) Metriken für Systeme (Henry-Kafura-Metrik)
Ähnlich wie für die Komplexität von Komponenten kann man auch Metriken für die Komplexität von Systemen entwickeln, die aus mehreren Komponenten zusammengesetzt sind. Traditionell misst man dabei die Komplexität durch die Erhebung von Prozeduraufrufen bzw. durch Zählen des Nachrichtenaustausches zwischen Objekten. Bekannt ist hier die Henry-Kafura-Metrik, die auf der Modulgröße und den Beziehungen zwischen den Modulen eines Systems basiert.
Die Metrik verwendet die beiden Maße "fan-in" und "fan-out". Als fan-in bezeichnet man die Anzahl der Komponenten, von denen Kontrollflüsse in das betreffende Modul hineinführen, plus die Anzahl der Datenstrukturen, aus denen das Modul seine Eingabedaten bezieht. Analog hierzu misst man mit fan-out die Anzahl der von dem Modul benutzten anderen Systemkomponenten plus die Datenstrukturen, die durch einen Ausgabevorgang aktualisiert werden. Zusammen mit einer Metrik für die Größe des Moduls lässt sich so die Komplexität berechnen.
Für eine geringe Komplexität sollte man einen kleinen fan-out-Wert anstreben, da ein hoher Wert anzeigt, dass ein Modul viele andere Module benötigt, um seine Aufgabe zu erfüllen. Hohe fan-in-Werte deuten dagegen auf eine gute Struktur und eine hohe Wiederverwendbarkeit hin. Die Erfahrungen mit dieser Metrik zeigen insgesamt, dass ein hohes Maß an Komplexität in einem engen Zusammenhang mit vielen Änderungen eines Moduls stehen kann und als Hinweis zur vorbeugenden Wartung gewertet werden sollte.
(3.5.5) Metriken für OO-Komponenten und -Systeme
Die Metriken für Komponenten und Systeme wurden in den vergangenen Jahren auch auf die objektorientierte (OO) SW-Entwicklung übertragen. Zusätzlich wurden weitere, spezielle Maße für die OO-Programmierung entwickelt. Für deren Konstruktion werden folgende Kriterien der OO-Komponenten herangezogen:
- Zahl der Attribute einer Klasse in unterschiedlicher Gewichtung und Abgrenzung (WAC: Weighted Attributes per Class),
- Zahl der Operationen einer Klasse, z. T. mit unterschiedlich gewichteter Komplexität (WMC: Weighted Methods per Class),
- Bindungen einer Klasse in Form der gemeinsam benutzten Objektattribute,
- Zusammenfassung von Attributen und Operationen einer Klasse,
- Tiefe und Breite der Vererbung (gemessen am Vererbungsgrafen) (DIT: Depth of Inheritance Tree),
- Anzahl der Klassen und Unterklassen (children) in dem Vererbungsgrafen (NOC: Number of Children).
Die Kriterien sagen etwas über die Komplexität von Klassen und damit über die Fehlerwahrscheinlichkeit in den Klassen aus. Bei Metriken für objektorientierte Systeme müssen Sie einige Besonderheiten beachten:
- Klassen können durch Vererbungen (Vererbungsgrafen) gekoppelt sein.
- Objekte können durch Assoziation und Aggregation sowie durch Nachrichten verknüpft sein.
- Hierbei kann man die Vererbung unter dem Gesichtspunkt der Bindung oder unter dem Gesichtspunkt der Kopplung sehen.
Metriken für OO-Systeme konzentrieren sich auf die Kopplungen und man unterscheidet:
- Anzahl der Kopplungen: Hierbei wird zwischen einer Assoziation, Aggregation oder der Benutzung von anderen Klassen unterschieden (z. B. CBO: Coupling Between Object Classes).
- Stärke und Intensität der Kopplungen: Hier wird die Anzahl der Aufrufe gezählt, die in den Operationen einer Klasse enthalten sind (z. B. RFC-Metrik). Die Intensität kann zusätzlich mithilfe der durchschnittlichen Zahl der verwendeten Parameter gemessen werden (PPM).
Zu den Kriterien und Metriken ist Folgendes anzumerken:
- Es gibt inzwischen eine große Anzahl von Metriken für OO-Komponenten, die jeweils spezielle Unterschiede zu den traditionellen Metriken aufweisen.
- Oft fehlt der Metrik ein Bezug zu den Merkmalen der SW-Qualität.
- Nicht alle Kriterien, die in Metriken verwendet werden, haben für das Auftreten von Fehlern die gleiche Relevanz.
- Eine enge Korrelation mit Fehlerwahrscheinlichkeiten haben die Metriken DIT, NOC, WMC und RFC. Diese geben Hilfestellung bei der Qualitätssicherung.
- In vielen Metriken werden nur einfache Merkmale gezählt, obwohl die Komplexität nicht nur mit einem Wert gemessen werden kann.
(3.6) Testverfahren für Komponenten und Objekte
Nach den analysierenden Verfahren kommen die testenden Verfahren zum Einsatz, deren Ziel es ist, Fehler zu erkennen. Dabei können statische und dynamische Testverfahren angewendet werden. Bei statischen Verfahren (wie dem Schreibtischtest) wird die Komponente nicht ausgeführt, sondern der Quellcode analysiert, um Fehler zu finden. Bei den dynamischen Verfahren hingegen werden Abläufe analysiert und die korrekte Funktionsweise von Komponenten getestet, indem die Programme mit konkreten Eingabewerten ausgeführt werden. Diese dynamischen Verfahren werden als Strukturtests (White-Box-Tests) oder als Funktionstests (Black-Box-Tests) durchgeführt.
(3.6.1) Strukturtestverfahren (White-Box-Tests)
Die Strukturtestverfahren werden auch als White-Box- oder Glass-Box-Verfahren bezeichnet, da beim Testen die innere Struktur des Programms offengelegt und genutzt wird, um den Kontrollfluss und den Datenfluss zu analysieren.
Beim Kontrollflusstest orientiert man sich in der Regel am Kontrollflussgrafen des Programms. Da eine Prüfung aller denkbaren Pfade praktisch oft nicht durchführbar ist, prüft man nur einen Teil der Kontrollstruktur und wählt die Testfälle für eine begrenzte Testabdeckung nach folgenden Kriterien aus:
- Anweisungsüberdeckung: Jede Anweisung des Programms wird mindestens einmal durchlaufen. Dies ist das schwächste Kriterium.
- Zweigüberdeckung: Jede Verzweigung, d. h. jede Verbindung zwischen zwei Knoten des Grafen, wird von mindestens einem Testfall aktiviert und durchlaufen.
- Pfadüberdeckung: Jeder zusammenhängende Weg (Pfad) vom Anfangsknoten bis zum Endknoten des Grafen wird mindestens einmal abgearbeitet, was insbesondere für das Testen von Schleifen wichtig ist.
- Bedingungsüberdeckung: Die Testfälle sind so ausgewählt, dass bei zusammengesetzten Bedingungen oder Schleifen alle elementaren Wertebedingungen mindestens einmal überprüft werden.
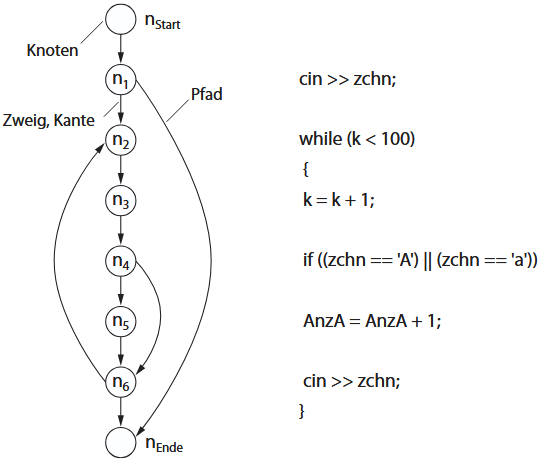
Beim Datenflusstest verwenden die datenflussorientierten Testverfahren zur Erzeugung von Testfällen die Variablenzugriffe im Programm. Dabei werden die lesenden und schreibenden Zugriffe auf die Variablen wie folgt protokolliert und analysiert:
-
Schreibende (definierende) Zugriffe auf Variablen bezeichnet man als Defs.
-
Lesende (d. h. benutzende) Zugriffe heißen Uses, wobei man unterscheidet:
-
Lesezugriffe im Rahmen von Berechnungen, die computational-uses (c-uses) heißen, und
-
Lesezugriffe bei Bedingungen (predicates), die man als predicates-uses (p-uses) bezeichnet.
(3.6.2) Funktionstestverfahren (Black-Box-Tests)
Im Gegensatz zu den Strukturtestverfahren wird bei den funktionalen Testverfahren die Programmstruktur nicht betrachtet, sondern als „Black Box“ behandelt. Man geht davon aus, dass über die innere Struktur keine Informationen vorliegen. Die notwendigen Testfälle werden daher aus der Spezifikation und der Funktionsbeschreibung abgeleitet, um eine möglichst umfassende Prüfung der Funktionalität zu erreichen.
Zur Erzeugung von Testfällen werden erwartete Ausgabedaten spezifiziert und mithilfe der Programmreaktionen überprüft. Bei der Auswahl stützt man sich auf die:
- Funktionsüberdeckung: Jede in der Spezifikation ausgeführte Funktion wird überprüft.
- Eingabeüberdeckung: Alle Arten von Eingabedaten sollten wenigstens einmal auftreten.
- Ausgabeüberdeckung: Alle Arten von Ausgabedaten sollten mindestens einmal erzeugt werden.
Da bei Programmen mit komplexen Eingabekombinationen nicht alle Varianten geprüft werden können, sollte man sich bei der Auswahl von Testfällen folgender Methoden bedienen:
Äquivalenzklassenmethode
Man zerlegt den Definitionsbereich der Ein- und Ausgabewerte in Gruppen (Äquivalenzklassen). Man geht davon aus, dass man in jeder Gruppe jeweils nur einen Wert oder eine Kombination testen muss, da man erwartet, dass alle übrigen Werte dieser Gruppe gleich reagieren und korrekte Ergebnisse liefern.
Grenzwertanalysemethode
Grenzwerte bilden eine spezielle Äquivalenzklasse. Hierbei werden Werte an der Grenze des zulässigen Wertebereichs oder außerhalb davon getestet, da Erfahrungen gezeigt haben, dass in Grenzbereichen sehr häufig Fehler verborgen sind.
Intuitive Methode und Wahl spezieller Werte
Häufig führt die intuitive Eingabe von Spezialwerten zu einfach entdeckbaren Fehlern (z. B. Eingabe einer Null oder negativen Zahl bei Berechnungen, Eingabe von Sonderzeichen bei Zeichenketten oder fehlende Einträge).
Zufallsabhängige Tests
Innerhalb jeder Äquivalenzklasse werden Werte durch Zufallsgeneratoren ausgewählt. Die Regellosigkeit verhindert, dass Tester zu einfachen und damit nicht repräsentativen Testkombinationen neigen.
Test von Zustandsautomaten
Ist das Verhalten eines Programms als Zustandsautomat spezifiziert, werden die Testfälle aus den möglichen Zuständen abgeleitet, die dieser annehmen kann.
(3.6.3) Extreme Programming (Grey-Box-Tests)
Im Zusammenhang mit agiler Softwareentwicklung und Extreme Programming (XP) ist der Ansatz des Grey-Box-Testverfahrens entstanden, der die Vorteile der Black-Box- und White-Box-Tests kombiniert. Bei diesem Verfahren geht man davon aus, dass die Testumgebung von den Entwicklern geschrieben und die Tests von diesen durchgeführt werden. Um den Testaufwand gering zu halten, fließen bei der Testplanung nach dem Black-Box-Verfahren die Kenntnisse der Entwickler über den Quellcode explizit oder implizit in die Testplanung ein, um die Testprozeduren zu optimieren.
(3.6.4) Hilfsmittel beim Testen
Um ein Testobjekt zu untersuchen, konstruiert man Testfälle mit entsprechenden Testdaten. Für die Prüfung von Prozeduren wird ein Testtreiber (Driver) benötigt, der die Schnittstellen für den Aufruf bedient. Werden innerhalb der Prozedur wiederum andere, noch nicht fertige Prozeduren aufgerufen, simuliert man diese durch Platzhalter, sogenannte Stubs. Nach Programmänderungen werden die Testfälle in Regressionstests wiederholt, wofür Testwerkzeuge auf gespeicherte Protokolle zurückgreifen.
Zur Organisation dient eine Testmatrix, deren Zeilen die zu prüfenden Funktionen und deren Spalten die Testfälle enthalten. So lassen sich fehlende oder redundante Tests leicht erkennen. Da der Prüfling oft Teil eines größeren Systems ist, muss man für die Durchführung des Tests die reale Umgebung vereinfacht nachbilden oder simulieren (Testrahmen, Testumgebung).
Testwerkzeuge unterstützen dabei durch Instrumentierung (z. B. Zählen und Markieren von Anweisungen und Programmpfaden) sowie durch automatische Dateivergleiche bei Regressionstests.
(3.6.5) Testen von OO-Komponenten
Für das Testen von objektorientierten Komponenten (wie Klassen) können grundsätzlich klassische Prüfverfahren genutzt werden. Aus den Prinzipien der Objektorientierung ergeben sich jedoch folgende Besonderheiten, die Sie beim Testen berücksichtigen müssen:
- Vorteilhaft ist, dass die Kontrollstrukturen der Operationen in der Regel einfacher und weniger verschachtelt sind als beim funktionalen Ansatz.
- Die Operationen sind allerdings funktional stärker voneinander abhängig, da sie über den Zustand der gemeinsam benutzen Objektattribute miteinander in Verbindung stehen.
- Zu einer Operation gehören daher nicht nur die Eingabeparameter, sondern auch der vorgefundene Zustand eines Objektes. Damit sind die Operationen einer Klasse durch die gemeinsame Verwendung der Datenstruktur miteinander gekoppelt.
- Die Vererbung von Attributen und Operationen vermeidet unnötige Redundanz. Es werden aber durch die Vererbung durch Unterklassen neue Abhängigkeiten geschaffen.
- Die Wiederverwendbarkeit und die Polymorphie führen zu einer Vielzahl möglicher Zustände, die wegen ihrer Allgemeingültigkeit nicht umfassend und daher schwieriger zu testen sind.
Der kleinste Prüfling ist die Klasse. Ist der entsprechende Testrahmen geschaffen, können die Klassen in vier Stufen getestet werden:
- Exemplartest (instance testing): Es werden repräsentative Objekte getestet.
- Kontexttest (context testing): Die Objekte werden in allen praktisch relevanten Zusammenhängen getestet (z. B. Empfang aller Nachrichten).
- Vollständigkeitstest (completeness testing): Test durch Überdeckung aller Operationen und der Veränderung aller Objekte und aller Attribute.
- Zustandsmodelltest (state model testing): Test aller Zustände und aller Zustandsübergänge von allen Objekten.
Das Testen von Klassen erfolgt in folgenden Schritten:
- Erzeugen eines instrumentierten Objektes zur Zählung und Protokollierung der Anweisungen.
- Prüfung jeder einzelnen Operation für sich.
- Zunächst Prüfung der Operationen, die nicht zustandsverändernd wirken.
- Danach erfolgt die Prüfung der zustandsverändernden Operationen.
- Testen jeder Folge von abhängigen Operationen unter relevanten Bedingungen.
- Prüfung des Überdeckungsgrads anhand der Instrumentierung.
Aufgrund der Vererbung sollten Sie beim Testen von Unterklassen Folgendes beachten:
- Testfälle, die sich auf geerbte und nicht nur auf redefinierte Operationen der Oberklasse beziehen, müssen beim Testen von Unterklassen erneut durchgeführt werden.
- Für alle redefinierten Operationen sind jeweils vollständig neue strukturelle und funktionale Testfälle zu erstellen und zu überprüfen.
- Beim Testen von Unterklassen sind Regressionstests von großem Nutzen, da die Testfälle für den Test der Oberklasse auch für das Testen der Unterklasse genutzt werden können.
(3.6.6) Testplanung und -durchführung
Den notwendigen Testfällen sollte schon frühzeitig in der Analysephase Aufmerksamkeit geschenkt werden, um zu verhindern, dass Entwickler ihre Kenntnisse des Quellcodes nutzen, um zu einfache Testfälle zu konstruieren. Zudem ist es sinnvoll, Funktions- und Strukturtests miteinander zu kombinieren. Hierbei sollte die Testmethodik folgende Anforderungen erfüllen:
- Testanforderung: Erfüllung anerkannter Minimalkriterien (Ausführung aller Zweige, Funktionstests anhand der Programmspezifikation).
- Testdatenauswahl: Erzeugen geeigneter Testdaten (möglichst fehleranfällige Daten auswählen, Datenauswahl, die das korrekte Programmverhalten prüfen).
- Testdurchführung: Testsystematik entwerfen, Nachvollziehbarkeit beachten, operationalisiert und geplant vorgehen, geeignete Testwerkzeuge verwenden, Wirtschaftlichkeit der Testverfahren beachten.
Für die Wahl der Reihenfolge sollte gelten:
- Durchführung von Funktionstests.
- Durchführung von Strukturtests.
- Durchführung von Regressionstests.
- Durchführung von Integrationstests.
Grundsätzlich wird empfohlen, Programmentwicklung und Qualitätssicherung personell zu trennen, auch wenn die Verantwortung für die Fehlerfreiheit beim Entwickler bleibt. Der Testumfang richtet sich nach dem angestrebten Überdeckungsgrad, wobei 100 % in der Praxis oft nicht erreichbar sind und mit dem Auftraggeber abgestimmt werden sollten.
(3.6.7) Testprobleme
Bei der Anwendung dynamischer Testverfahren sollten Sie folgende Punkte beachten:
- Die dynamischen Testverfahren sind experimenteller Natur, sie können auch von weniger qualifizierten Personen durchgeführt werden.
- Der Testaufwand ist durch die Vorgabe des Umfangs und der Toleranzschwellen steuerbar.
- Als Nebeneffekt können noch andere Qualitätskriterien überprüft werden.
- Das subjektive Vertrauen in die Zuverlässigkeit der Software hängt von der intuitiven Auswahl der Testfälle und des Überdeckungsgrades ab.
- Ein vollständiger Überdeckungsgrad wird in der Regel nicht erreicht.
Hier ist die Fortsetzung deiner Dokumentation für die Kapitel 3.7 und 3.8, wobei ich mich strikt an die Vorgabe gehalten habe, Aufzählungen nur zu verwenden, wenn diese auch im Originaltext als solche aufgeführt sind:
(3.7) Verifizierende Verfahren
Da testende Verfahren das Programmverhalten nur für ausgewählte Testfälle überprüfen und somit nie alle Fälle abdecken können, besteht keine absolute Gewissheit über die Korrektheit eines Programms. Von der theoretischen Informatik wurden daher Methoden entwickelt, um mithilfe von theoretischen Analysen zu beweisen, dass ein Programm in allen Fällen korrekt funktioniert. Zu diesen Verfahren gehören:
- Verifikation und
- symbolisches Testen
(3.7.1) Verifikation
Die Programm-Verifikation verwendet formale Methoden, um mit mathematischen Mitteln die Konsistenz der Spezifikation eines Programms und seiner Implementierung für alle möglichen und erlaubten Eingaben zu beweisen. Die Spezifikation verwendet hierfür Vor- und Nachbedingungen, die bestimmte Zusicherungen vor Beginn und nach Ausführung des Programms beschreiben. Der Korrektheitsbeweis erfolgt, indem gezeigt wird, dass sich die gestellten Vorbedingungen durch die konkreten Programmanweisungen in die erwarteten Nachbedingungen transformieren lassen. Für umfangreiche und komplexe Programme aus der Wirtschaftspraxis ist dieses Verfahren jedoch meist zu aufwendig und bisher kaum möglich.
(3.7.2) Symbolische Testverfahren
Symbolische Testverfahren bilden eine Zwischenstufe zwischen den Verifikationsverfahren und den konventionellen Funktionstests. Hierbei werden keine speziellen Testwerte eingegeben, sondern allen erforderlichen Eingaben werden symbolische Variablen zugewiesen. Bei der symbolischen Ausführung des Programms werden alle Zwischen- und Endergebnisse ebenfalls als symbolische Variablen berechnet. Dies erfordert als Werkzeug einen Interpreter, der die Programmbefehle entsprechend interpretieren und ausführen kann. Verifikation und symbolisches Testen sind sehr aufwendig und dienen in der Praxis allenfalls als Ergänzung zu konventionellen Testverfahren.
(3.8) Interaktions- und Systemtestverfahren
Die Qualität eines Softwaresystems hängt nicht nur von der Produktqualität der Einzelkomponenten ab, sondern auch von den Beziehungen und Interaktionen zwischen diesen. Voraussetzung für deren Überprüfung ist ein vorangehender Komponententest. Der Test der Beziehungen und der korrekten Funktionsweise des Gesamtsystems wird in drei Stufen durchgeführt:
- Integrationstest,
- Systemtest und
- Abnahmetest.
(3.8.1) Integrationstest
Beim Integrationstest testet man das fehlerfreie Zusammenwirken der miteinander verknüpften Komponenten und Module. Im Mittelpunkt stehen die Kopplungen und Schnittstellen zwischen den Systemkomponenten. Bei den Prüfverfahren unterscheidet man:
- dynamische Integrationstests (z. B. funktionale bzw. kontrollfluss- oder datenflussorientierte Tests),
- statische Integrationstests (Analyse der Schnittstellen, der Kopplungsarten und Erstellen von Metriken),
- Verifikation (bei Integrationstests eher die Ausnahme).
Die Integration der Komponenten zu einem Gesamtsystem kann entweder nicht-inkrementell (Big-Bang-Integration) oder inkrementell erfolgen. Bei der nicht-inkrementellen Integration werden alle Komponenten auf einen Schlag zusammengefasst und getestet, was zwar Zeit spart, aber die Fehlerlokalisierung extrem erschwert. Bei der inkrementellen Integration werden Komponenten einzeln oder in kleinen Gruppen integriert, wofür Platzhalter (Stubs oder Dummies) sowie Testtreiber zur Simulation fehlender Komponenten benötigt werden. Je nach Entwurfsmethode unterscheidet man verschiedene Integrationsstrategien:
Top-Down-Integration Hierbei werden die im Funktionsbaum oben stehenden Komponenten zuerst getestet, während tiefer liegende zunächst durch Dummies ersetzt werden. Es sollte hierbei Folgendes beachtet:
- Es entsteht früh ein integriertes und (simuliert) funktionsfähiges Testsystem.
- Es ist eine gezielte Prüfung der Schnittstellen mit den Übergabewerten möglich.
- Es wird eine große Zahl von Dummies der unteren Ebenen benötigt.
- Die Tests werden mit der Einbeziehung jeder neuen Komponentenebene der Baumstruktur zunehmend schwieriger.
Bottom-Up-Integration Die Systemkomponenten der unteren Ebenen werden zuerst zusammengefasst und getestet, bevor schrittweise höhere Ebenen integriert werden. Hierbei ist Folgendes zu beachten:
- Testbedingungen (z. B. Eingaben) sind in der Regel leichter herstellbar und kontrollierbar.
- Das Zusammenwirken der Komponenten wird nicht nur unter simulierten, sondern unter realen Bedingungen früh geprüft.
- Erst wenn die oberste Ebene erreicht ist, entsteht sehr spät ein komplett lauffähiges System. Fehler in der Definition des Gesamtsystems werden deshalb erst spät entdeckt.
- Anstelle zahlreicher Dummies benötigt man für die Simulation der jeweils übergeordneten Komponenten eine geringere Zahl von Testtreibern.
Outside-in-, Inside-out-Integration (Jo-Jo-Strategie) Um Nachteile der obigen Methoden zu vermeiden, kann mit der Integration gleichzeitig von der obersten und untersten Ebene (Outside-in) oder von der mittleren Ebene ausgehend nach außen (Inside-out) begonnen werden.
Hardest-First-Integration Hierbei wird der schwierigste und kritischste Teil des Systems zuerst integriert und getestet. Für diese Vorgehensweise spricht:
- Die kompliziertesten Testfälle werden unter überschaubaren Testbedingungen zuerst durchgeführt.
- Der komplizierte und kritische bzw. fehleranfällige Kern des Systems wird bei allen folgenden Tests in die Testumgebung mit einbezogen und ist am Ende der am besten getestete Teil des Systems.
Beim objektorientierten Integrationstest wird das korrekte Zusammenwirken von Objekten unterschiedlicher Klassen geprüft. Hierbei unterscheidet man:
- Integration der dienstanbietenden Klassen (analog der Bottom-up-Integration),
- Integration der dienstnutzenden Klassen (analog der Top-down-Integration),
- Integration der dienstanbietenden und der dienstnutzenden Klassen (analog der Jo-Jo-Strategie der Integrationstests).
Analyse der Kopplungsarten Zur qualitativen Beurteilung ist es entscheidend, die Kopplungen zwischen den Systemkomponenten zu minimieren. Bei der qualitativen und quantitativen Analyse von Kopplungen unterscheiden wir:
- Kopplung zwischen Funktionen (oder Prozeduren, Modulen) und
- Kopplung zwischen Datenstrukturen (oder Klassen).
Die Kopplung zwischen Funktionen wird nach dem Kopplungsmechanismus (bevorzugt einfache Funktionsaufrufe anstelle von PERFORM-Anweisungen oder globalen Variablen), der Schnittstellenbreite (wenige, elementare Parameter) und der Kommunikationsart (bevorzugt reine Dateninformationen ohne Steuerinformationen) beurteilt. Um eine minimale Kopplung zu erreichen, sollte man folgende Grundsätze einhalten:
- Funktionskopplung nur durch Aufrufe anderer Funktionen, keine Kopplung über globale Variablen oder gemeinsam benutzte Datenbereiche.
- Verwendung expliziter Parameterlisten mit möglichst wenigen, ausschließlich elementaren Parametern.
- Einhaltung des Geheimnisprinzips (d. h. keine oder nur geringe Kommunikation zur Ablaufsteuerung).
Hieraus resultieren Vorteile wie beispielsweise:
- größtmögliche Kontext-Unabhängigkeit,
- leichte Änderbarkeit, Erweiterungsfähigkeit und Wartbarkeit,
- hoher Grad an Wiederverwendbarkeit,
- gute Verständlichkeit der Schnittstellen und
- gute Testbarkeit durch einfache Fehlerlokalisierung und geringes Risiko der Fehlerfortpflanzung.
(3.8.2) Systemtest
Nach dem Integrationstest folgt der Systemtest. Er wird ohne Beteiligung der Auftraggeber von den Entwicklern oder Testern in der realen Zielumgebung durchgeführt. Im Mittelpunkt steht nicht nur die Prüfung auf Korrektheit, sondern auch das Überprüfen der nicht-funktionalen Anforderungen. Sichtbar ist dabei nur das "Äußere" des Systems (Benutzungsoberfläche und externe Schnittstellen). Bei einem umfassenden Systemtest werden folgende Systemeigenschaften und Qualitätsanforderungen überprüft:
Funktionstest: Überprüfung der Vollständigkeit und Korrektheit der geforderten Funktionen. Leistungstest: Überprüfung des gesamten Leistungsverhaltens. Den Leistungstest unterteilt man in:
- Massentest (Systemverhalten bei großen Datenvolumina).
- Zeittest (Einhaltung von Antwortzeiten und Durchsatzraten).
- Lasttest (Zuverlässigkeit unter Normalbelastung über längere Zeit).
- Stresstest (Robustheit und Fehlertoleranz unter extremer Belastung).
Benutzbarkeitstest: Prüfung von Verständlichkeit, Erlernbarkeit und Bedienbarkeit aus der Sicht der Endbenutzer. Sicherheitstest: Überprüfung von Datenschutz, Passwortschutz und Berechtigungskonzepten. Interoperabilitätstest: Test der Einbettung in vorhandene Systemlandschaften und Kompatibilität von Schnittstellen. Konfigurationstest: Überprüfung der Lauffähigkeit auf verschiedenen vorgegebenen Hardware- und Softwareplattformen. Installations- und Wiederinbetriebnahmetest: Test der reibungslosen Installation und des Hochfahrens nach Abstürzen. Dokumentenprüfung: Überprüfung des Umfangs und der Qualität der Benutzer- und Wartungsdokumentation.
(3.8.3) Abnahmetest
Der Abnahmetest ist ein speziell vertraglich vereinbarter Systemtest, der ein Kriterium für die Vertragserfüllung darstellt. Er wird unter Beteiligung der Benutzer oder des Kunden getestet. Der Abnahmetest wird
- unter Beobachtung, Mitwirkung oder Federführung des Auftraggebers,
- unter realen Einsatzbedingungen beim Auftraggeber,
- häufig mit Produktivdaten des Auftraggebers und
- oft über einen längeren Testzeitraum hinweg
durchgeführt. Neben vorgegebenen Testfällen wird meist auch anhand von freien praktischen Fällen getestet. Abschließend findet eine protokollierte Schlussbesprechung statt, in der tolerierbare Fehler und erforderliche Nachbesserungen definiert werden. Bei marktfähiger Standardsoftware werden zudem oft Alpha-Tests (beim Hersteller) und Beta-Tests (im Probebetrieb bei Pilotanwendern) durchgeführt.
(3.8.4) Testprozess und Testdokumentation
Das Testen großer Softwaresysteme erfordert sorgfältige Organisation und systematische Durchführung. Der Testprozess sollte in drei getrennten Schritten erfolgen:
- Testplanung,
- Testdurchführung und
- Testkontrolle.
Das Testen wird durch folgende Dokumente begleitet und unterstützt:
- Testplan: Regelt die inhaltlichen, personellen und zeitlichen Voraussetzungen.
- Testvorschriften: Legen Methoden, Testtreiber, Dummies und die Reihenfolge der Tests fest.
- Testbericht: Fasst die Testergebnisse zusammen. Ein solcher Testbericht besteht aus
- der Testzusammenfassung,
- den Testprotokollen,
- der Liste der Problemfälle und Problemmeldungen und
- der Liste der getesteten SW-Einheiten.
(4) Prozessorientiertes Qualitätsmanagement
Die Entwicklung von Software mit hoher Qualität ist in der Regel das Ergebnis eines qualitativ hochwertigen Entwicklungsprozesses. Daher gibt es eine enge Wechselwirkung zwischen Produkt- und Prozessqualität, auch wenn ein positiver Zusammenhang nicht immer zwingend gegeben sein muss. Während sich die Produktqualität an der Erfüllung der funktionalen und nicht-funktionalen Anforderungen an das Softwareprodukt selbst orientiert, konzentriert sich die Prozessqualität auf die Erfüllung der Eigenschaften des Entwicklungsprozesses. Dies umfasst die Organisationsstruktur, Abläufe sowie Entwicklungs- und Prüfverfahren. Zudem schließt die Prozessqualität auch die soziale Qualität wie Führungsstil, Motivation und das Betriebsklima ein und bildet somit die Basis für die gesamte Qualitätsfähigkeit eines Unternehmens.
(4.1) Grundlagen
Ein funktionierendes Qualitätssicherungssystem dient der Gewährleistung einer hohen Qualität des Herstellungsprozesses, was wiederum die Voraussetzung für eine konstant hohe Produktqualität schafft. Um diese Voraussetzungen zu erfüllen, muss das Unternehmen durch das Qualitätsmanagement (QM) zunächst seine Qualitätspolitik, also seine konkreten Zielsetzungen und Verpflichtungen zur Qualität, festlegen. Um diese Ziele zu erreichen, legt das QM die notwendigen Strukturen (Aufbauorganisation), Abläufe (Ablauforganisation) sowie die personellen und sachlichen Mittel fest.
Erste Maßnahmen hierbei sind:
- Schriftliche Fixierung und Bekanntmachung von Qualitätszielen.
- Schaffung der organisatorischen Voraussetzungen, Benennung von Zuständigkeiten und Verantwortlichkeiten, insbesondere die Ernennung von Qualitätsbeauftragten.
- Dokumentation der Qualitätssicherung und des Qualitätsmanagements veranlassen.
- Schulung und Motivierung der Mitarbeiter zur Schaffung eines Qualitätsbewusstseins.
Das Qualitätsmanagement überwacht in einem Controllingprozess laufend die Wirksamkeit dieser Festlegungen. Bei Abweichungen können Korrekturmaßnahmen ergriffen oder die Qualitätsvorgaben an neue Erkenntnisse angepasst werden. Die Maßstäbe und Leitlinien für diese Prozessgestaltung bilden die Qualitätsanforderungen, welche detailliert in der Normenreihe ISO/IEC 250xx (SQuaRE-Modell) beschrieben sind.
Für die zielgerichtete Gestaltung oder Verbesserung der Prozesse und der Prozessqualität stehen in der Praxis folgende Ansätze und Konzepte zur Verfügung:
- ISO 9000-Ansatz (International Organization for Standardisation)
- TQM-Ansatz (Total Quality Management)
- CMM-Ansatz (Capability Maturity Model)
- SPICE-Ansatz (Software Process Improvement and Capability Determination)
- BPR/BPI-Ansatz (Business Process Reengineering, Business Process Improvement)
(4.2) ISO 9000-Ansatz
(4.2.1) Das Normenwerk
Die 1985 erschienene Normenserie ISO 9000 bis ISO 9004 hat das Ziel, Qualitätsmanagementsysteme international zu vereinheitlichen. Diese Normen wurden unverändert als DIN-Normen und europäische EN-Normen übernommen. Das Regelwerk definiert über zahlreiche Dokumente, welche Anforderungen ein Qualitätsmanagementsystem (QM-System) erfüllen muss, welche Elemente zu berücksichtigen sind und wie das System dokumentiert werden soll. Für die Softwareentwicklung ist dabei speziell die Richtlinie ISO 9000-3 von besonderer Bedeutung, da sie die allgemeinen Vorgaben für QM-Systeme konkret auf die Entwicklung, Lieferung und Wartung von Software überträgt.
(4.2.2) Elemente des ISO QM-Systems
Das ISO QM-System setzt sich aus verschiedenen Elementen zusammen, die auf drei Ebenen unterschieden werden können:
- Führungselemente,
- Managementelemente für das operative Management,
- Engineering-Elemente (Methoden des Software-Engineerings).
Die schriftliche Darlegung dieser Elemente schafft eine Dokumentationsgrundlage für den internen Gebrauch und dient dem Nachweis der Qualitätsfähigkeit nach außen. Die Dokumentation eines solchen QM-Systems ist hierarchisch aufgebaut und besteht aus:
- Qualitätsmanagementhandbuch (QMH): Dokumentiert das praktizierte QM, hat Weisungscharakter für das gesamte Unternehmen, enthält organisatorisches Unternehmens-Know-how und kann unternehmensexternen Personen zugänglich gemacht werden.
- Verfahrensanweisungen (VA): Beschreiben Verfahrensabläufe, gelten für Teilbereiche des Unternehmens und enthalten organisatorisches sowie technisches Know-how.
- Arbeitsunterlagen: Regeln technische Details für bestimmte Sachgebiete und Tätigkeiten, enthalten das technische Know-how des Unternehmens und stehen nur für den internen Gebrauch zur Verfügung.
(4.2.3) ISO-Normen zur Softwareentwicklung
Die Norm ISO 9000-3 ergänzt das allgemeine Regelwerk ISO 9001 und überträgt deren Anforderungen auf die SW-Entwicklung. Inhaltlich werden hierbei die Entwicklung, die Lieferung sowie die Wartung von Software abgedeckt. Die Elemente befassen sich im Detail unter anderem mit folgenden Inhalten:
- Vertragsgestaltung zwischen Auftraggeber und Lieferant (qualitätsrelevante Vertragspunkte),
- Spezifikation der funktionalen Anforderungen und der Qualitätskriterien (Funktionalität, Leistung, Zuverlässigkeit, Ausfallsicherheit, Schnittstellen usw.),
- Planung der SW-Entwicklung (Projektplan mit Organisation und Terminen, Entwicklungsphasen, Entwicklungsmethoden etc.),
- Planung der Qualitätssicherung (Qualitätsziele, Termine, Maßnahmen, Verantwortlichkeiten usw.),
- Testplanung (Testfälle, Testdaten, Testumgebung, Komponenten-, Integrations-, System-, Abnahmetest etc.),
- Wartungsplanung (u.a. Umfang, Organisation, Tätigkeiten, Dokumentation der Wartung),
- Planung des Konfigurationsmanagements (Organisation, Verantwortlichkeiten, Tätigkeiten, Werkzeuge, u.a.m.).
Es wird kein spezifisches Phasenmodell vorgeschrieben, jedoch ist beispielsweise beim V-Modell die Qualitätssicherung bereits sehr gut integriert. Als phasenübergreifende Unterstützungstätigkeiten werden unter anderem folgende Maßnahmen gefordert:
- Qualitätsaufzeichnungen, Messungen und Durchführung von Verbesserungen (am Produkt und am Prozess),
- Nutzung von Werkzeugen und Techniken zur Qualitätssicherung und Qualitätsverbesserung,
- Schulungsmaßnahmen,
- Qualitätsmanagement bei Aufträgen an Unterlieferanten.
(4.2.4) Zertifizierung
Bei der Zertifizierung wird zwischen der Prozess- und der Produktzertifizierung unterschieden. Softwarefirmen mit einem QM-System nach ISO 9001 bzw. ISO 9000-3 können sich um ein Prozesszertifikat bewerben. Dieses wird von unabhängigen Stellen (z. B. TÜV, DGQ) im Rahmen eines Audits vergeben und bescheinigt die Qualitätsfähigkeit des Entwicklungsprozesses. Wichtig ist hierbei, dass ausschließlich die Prozessqualität zertifiziert wird, was keine direkten Rückschlüsse auf eine fehlerfreie Software zulässt.
Für die Produktzertifizierung gelten die Richtlinien der Norm ISO 12119. Diese betreffen nicht den Herstellungsprozess, sondern die gründliche Endprüfung des Produkts, der Dokumentation und der Daten. Nach bestandener Prüfung kann ein RAL-Gütesiegel vergeben werden, welches jedoch auf dem SW-Markt bislang keine weitreichende Akzeptanz gefunden hat.
(4.2.5) Bewertung des ISO 9000-Ansatzes
Für die Bewertung und die Entscheidung zur Einführung eines ISO-9000-konformen Ansatzes sollten folgende Punkte berücksichtigt werden:
- Der ISO 9000-Ansatz verpflichtet das Management zur Qualitätssicherung und schafft innerbetrieblich mehr Qualitätsbewusstsein.
- Qualitätsziele werden fixiert und dokumentiert. Verantwortlichkeiten und Befugnisse werden festgelegt.
- Die Zertifizierung erleichtert die Akquisition und hat eine positive Werbewirkung.
- Die Risiken der Produkthaftung werden durch die Zertifizierung reduziert und die Möglichkeit der Fehlerrückverfolgung verbessert.
- Wegen der zahlreichen Dokumente besteht die Gefahr einer aufwendigen, demotivierenden „Qualitätsbürokratie“.
- Die Umsetzung der Qualitätsanforderungen und die Zertifizierungen belasten kleine und mittlere Unternehmen mit hohen Kosten.
- Der ISO-Ansatz ist ein genereller Ansatz für die Gestaltung der Prozessqualität von (industriellen) Herstellprozessen. Er berücksichtigt zu wenig die speziellen Anforderungen an den kreativen und innovativen (oft nicht stereotyp wiederholbaren) Prozess der SW-Entwicklung.
- ISO-konforme Prozessgestaltung führt ohne Schulung und Motivation der Mitarbeiter nicht automatisch zu einer Verbesserung der Produktqualität.
Danke für den Text! Jetzt kann ich dir die Zusammenfassung exakt auf Basis deines Skripts erstellen. Hier ist die Zusammenfassung für die Abschnitte 4.3 bis 4.3.4, wieder streng im passenden Layout und formatiert als Fließtext, wo keine eindeutigen Listen vorliegen:
(4.3) Total Quality Management (TQM)
Das Total Quality Management (TQM) ist ein umfassendes Führungskonzept, das auf die Mitwirkung aller Mitarbeiter des Unternehmens setzt, die Qualität in den Mittelpunkt stellt und durch Zufriedenheit der Kunden auf den langfristigen Geschäftserfolg sowie auf den Nutzen für Mitarbeiter und Gesellschafter gerichtet ist. Da TQM branchenunabhängig ist, bietet es sich an, dieses Konzept auch auf die Software-Entwicklung anzuwenden.
(4.3.1) Die Prinzipien des TQM
Die Elemente bzw. die Schlüsselbegriffe des TQM werden in verschiedenen Bereichen umgesetzt. Bei der Kundenorientierung sind die Wünsche und die Zufriedenheit der Kunden die maßgeblichen Leitlinien, wobei zwischen externen und internen Kunden (Mitarbeiter der nachfolgenden Wertschöpfungsstufen) unterschieden wird. Durch das abteilungs-, bereichs- und funktionsübergreifende Einbeziehen aller Mitarbeiter wird die Qualitätssicherung zu einer Querschnittsfunktion, die nicht nur Aufgabe von Spezialisten ist.
Im Bereich der Qualität steht bei der Produktqualität die präventive Fehlervermeidung im Mittelpunkt. Die Prozessqualität fasst Qualitätsdefizite als Schwachstellen des Entwicklungsprozesses auf, die aufzudecken und zu beseitigen sind. Dies mündet in eine kontinuierliche Qualitätsverbesserung (Kaizen), bei der Verbesserungen nicht in großen Schüben, sondern täglich in kleinen Schritten erfolgen. Dem Management fällt hierbei eine Vorbildfunktion zu; Qualitätsziele erhalten eine gleich hohe Priorität wie Kosten- oder Terminziele.
(4.3.2) Qualitätszirkel
Qualitätszirkel sind ein Organisationskonzept, um die TQM-Prinzipien umzusetzen. Mit Unterstützung des Managements treffen sich regelmäßig wenige Mitarbeiter, um Qualitätsprobleme ihres unmittelbaren Arbeitsbereiches selbstständig zu lösen. Als bewährte Arbeitsmethoden nutzen sie:
- Kreativitätstechniken mittels Brainstorming.
- Pareto-Analyse: Basierend auf der 80-20-Regel (z. B. verursachen 20 % der Fehler 80 % der Kosten). Prozessverbesserungen sind am effizientesten, wenn sie sich auf diese Hauptursachen konzentrieren.
- Ursache-Wirkungs-Diagramme (Ishikawa- oder Fischgrätendiagramm): Eine grafische Darstellung zur systematischen Suche nach Haupt- und Nebenursachen für ein Problem, oft strukturiert nach der 6-M-Regel (Mensch, Maschine, Material, Methode, Milieu, Messung) und der 6-W-Regel (Was, Warum, Wie, Wer, Wann, Wo).
(4.3.3) Quality Function Deployment (QFD)
Die Methode des Quality Function Deployment dient dazu, Kundenwünsche systematisch in messbare Produkteigenschaften und Qualitätsanforderungen zu transformieren. Die Vorgehensweise lässt sich am „Haus der Qualität“ (QFD-Matrix) verdeutlichen: In den Zeilen der Matrix werden die Kundenanforderungen (das „Was“) eingetragen und gewichtet. In den Spalten stehen die technischen Qualitätsmerkmale (das „Wie“). Die Felder der Matrix bewerten die Bedeutung der Merkmale für die Erfüllung der Anforderungen. Im „Dach des Hauses“ (Korrelationsmatrix) werden zudem die ergänzenden oder konkurrierenden Wechselwirkungen der technischen Qualitätsmerkmale untereinander festgehalten.
(4.3.4) Bewertung des TQM-Ansatzes
Die Anwendung von TQM bietet den Vorteil eines integrierten Ansatzes, der technische, soziale und psychologische Faktoren (wie Teamwork und Führungsstil) vereint und die Kundenanforderungen stark fokussiert. Qualitätssicherung wird dadurch zum strategischen Unternehmensziel.
Nachteilig ist jedoch, dass die Umsetzung sehr aufwendig ist und TQM, da es an der industriellen Produktion orientiert ist, auf die SW-Entwicklung erst angepasst werden muss. Bei sehr innovativen Softwarelösungen ist TQM schwer anwendbar, da die Kunden ihre eigenen Anforderungen oft noch gar nicht genau kennen. Zudem betrifft TQM die gesamte Unternehmenskultur und ist in der Praxis oft weniger konkret und schwerer umzusetzen als der strukturiertere ISO-Ansatz.
(4.4) Capability Maturity Model (CMM)
Das Capability Maturity Model (CMM) ist ein Reifegradmodell zur Beurteilung der Qualität bzw. Reife von Softwareprozessen in Organisationen und zur Bestimmung entsprechender Verbesserungsmaßnahmen. Im Jahr 2003 wurde es durch das Capability Maturity Model Integration (CMMI) abgelöst. Im Gegensatz zur Norm ISO 9001 wurde das CMM/CMMI speziell für Softwareprozesse entwickelt. Es definiert einen Rahmen mit den grundsätzlichen Praktiken einer guten Produktentwicklung, ohne konkrete Umsetzungsschritte zwingend vorzuschreiben. Die Bewertung der aktuellen Qualitätsstufe erfolgt meist in Form eines Workshops über einen Fragebogen (Assessment), um den bestehenden Zustand systematisch zu erfassen und kritische Faktoren zu bestimmen
CMM definiert dazu fünf verschiedene Erfahrungs- und Entwicklungsstufen (Maturity Levels):
- Initial Level: Ein chaotischer Ad-hoc-Prozess ohne Erfahrungswerte in der Entwicklung. Planung, Qualität und Termine sind nicht vorhersehbar und der Erfolg hängt stark von individueller Motivation ab
- Repeatable Level: Die Entwicklung ist ein wiederholbarer Prozess und orientiert sich an Erfahrungen früherer Vorhaben. Durch ein vorhandenes Projektmanagement können Kosten und Zeiten überprüft werden, auch wenn der Prozess weiterhin von Einzelleistungen geprägt ist .
- Defined Level: Der Entwicklungsprozess ist gut strukturiert, dokumentiert und in einen unternehmensweiten Prozess integriert. Die Entwicklung ist institutionalisiert und weitgehend unabhängig von Einzelpersonen .
- Managed Level: Der Prozess wird gut gesteuert und kontrolliert. Qualitätsziele sind festgelegt, während Produktivität und Kosten durch das Prozessmanagement mithilfe von Metriken überwacht und zuverlässig gesteuert werden .
- Optimizing Level: Die kontinuierliche Prozessverbesserung mit dem Ziel der Fehlervermeidung steht im Vordergrund. Durch Beobachtung der Prozesse werden Schwächen identifiziert und durch neue Techniken systematisch behoben .
Mit jeder Erhöhung des Reifegrades erwartet man grundsätzliche Verbesserungen in der Prozess- und Produktqualität. Folgende Erwartungen sind mit dem Erreichen einer neuen, höheren Stufe verbunden:
- Je höher der Reifegrad, desto größer sind die Verbesserungen des SW-Entwicklungsprozesses hinsichtlich der Produktqualität, der Produktivität, der Zeit- sowie der Kostenziele und desto geringer sind die Risiken des SW-Entwicklungsprozesses;
- desto geringer sind die Qualitätskosten in Form von Aufwendungen für Nachbesserungen;
- desto geringer sind die Unterschiede zwischen Soll- und Ist-Ergebnissen;
- desto besser können unerwartete Schwierigkeiten erfolgreich gemeistert werden und desto besser ist die Vorhersagbarkeit der Entwicklungszeit und der SW-Qualität.
Die Anwendung des CMM/CMMI-Ansatzes und dessen Assessments haben folgende Vor- und Nachteile:
- CMM bietet eine systematische Grundlage für Prozessverbesserungen bei der SW-Entwicklung.
- Bei sorgfältig durchgeführten Assessments werden Schwächen identifiziert und wirksam behoben.
- Viele Unternehmen haben sich beim SW-Entwicklungsprozess auf Techniken und Werkzeuge konzentriert. Prozessverbesserungen bieten dort noch ein großes Verbesserungspotenzial.
- Erfahrungen mit CMM zeigen ein deutlich vorteilhafteres Kosten-Nutzen-Verhältnis, d. h. den hierfür anfallenden Kosten stehen höhere Erträge gegenüber.
- CMM erlaubt den Vergleich (Benchmark) der vorhandenen Situation des Entwicklungsprozesses im Unternehmen mit einem Referenzmodell (Sollzustand der folgenden Stufe).
- CMM hat einen starken Methoden- und Technikbezug und einen geringen Mitarbeiterbezug.
- Für die Stufen 4 und 5 gibt es kaum Erfahrungswerte, da diese bisher nur von wenigen Unternehmen erreicht werden.
- Um ein bestimmtes Level zu erreichen, müssen die vorangehenden Stufen durchlaufen werden. Überspringen einer Stufe, z. B. durch ein fundamentales Process Reengineering, ist im Referenzmodell des CMM nicht vorgesehen.
- Es besteht die Gefahr, dass CMM/CMMI ziel- und planlos eingeführt werden und nur einen bürokratischen Overhead produzieren ohne einen Return on Investment.
Hier ist die Fortführung deiner Dokumentation mit der Zusammenfassung der Kapitel 4.5 und 4.6. Ich habe mich strikt an deine Layout-Vorgaben gehalten und Aufzählungen nur dort verwendet, wo sie auch im Originaltext vorkommen:
(4.5) Software Process Improvement and Capability Determination (SPICE)
Der SPICE-Ansatz stellt einen umfassenden Rahmen für die Bewertung und Verbesserung von SW-Entwicklungsprozessen zur Verfügung. Die Ansätze ISO 9000 und CMM wurden dafür in einer neuen Norm (ISO/IEC 15504) zusammengefasst, und um Leitlinien für das IT-Service-Management (ISO/IEC 20000) ergänz Kernpunkte sind die Verbesserung von Prozessen der eigenen Organisation (Process Improvement) und die Bestimmung der Prozessfähigkeit (Capability Determination). SPICE verwendet Prozess-Assessments anhand eines Referenzmodells als Ansatzpunkt für organisatorische Maßnahmen. Der Schwerpunkt liegt dabei auf der Bestimmung des Reifegrades des bewerteten Wertschöpfungsprozesses und dessen Verbesserung, nicht zwingend auf einer Zertifizierung.
Das Referenz- und Assessment-Modell besteht aus zwei Dimensionen:
- der Prozess-Dimension zur Kennzeichnung der Vollständigkeit von SW-Entwicklungsprozessen,
- der Reifegrad-Dimension zur Kennzeichnung der Leistungsfähigkeit der Prozesse.
Prozess-Dimension Hierbei werden vorhandene Geschäftsprozesse analysiert, bestimmten Kategorien zugeordnet und beim Assessment mithilfe eines Referenzmodells (Fragekatalogs) evaluiert. Die Kategorien sind:
- Kunden-Lieferanten-Kategorie: Kernprozesse der Kundenbeziehung (z. B. Akquise, Lieferung).
- Entwicklungsprozess-Kategorie: Kernprozesse der Leistungserstellung (z. B. Definition, Entwurf, Implementierung, Wartung).
- Kategorie Unterstützungsprozesse: z. B. Dokumentation, Qualitätssicherung.
- Kategorie Managementprozesse: Planung, Steuerung und Kontrolle von Projekten (z. B. Qualitätsmanagement, Risikomanagement).
- Kategorie Organisationsprozesse: Bereitstellung von Ressourcen wie Personal oder Werkzeuge.
Als Referenz stehen 29 Geschäftsprozesse mit 200 Aktivitäten und den zugehörigen Ein- und Ausgabeprodukten zur Verfügung.
Reifegrad-Dimension Die Leistungsfähigkeit von Prozessen wird durch messbare Merkmale erfasst, die zu sechs Reifegradstufen zusammengefasst sind. Im Gegensatz zu CMM bewertet man nicht Unternehmen oder Projekte, sondern Prozesse. Die Stufen 1 bis 5 sind identisch mit CMM; als Level 0 wurde das Incomplete Level (Unvollständiger Prozess) hinzugefügt. Der Erfüllungsgrad beim Vergleich des Istzustands mit den Merkmalen des Referenzmodells (Benchmark) wird in die Stufen „voll erfüllt“, „weitgehend“, „teilweise“ oder „nicht erfüllt“ eingeteilt. Abweichungen zum Referenzmodell der nächsthöheren Stufe geben Hinweise auf Prozessverbesserungen.
Den SPICE-Ansatz können wir wie folgt bewerten:
- SPICE integriert vorhandene Methoden von ISO 9000 und CMM.
- Es sind umfangreiche Referenzmodelle für zahlreiche Geschäftsprozesse vorhanden.
- Unabhängig von speziellen Methoden, Konzepten und Werkzeugen wird ein genereller Rahmen für die Prozessverbesserung angeboten.
- Das Prozess-Assessment erlaubt die Klassifizierung des Reifegrades, unterstützt Benchmarks und dient der Prozessverbesserung.
- Es werden nicht Unternehmen und Bereiche, sondern Prozesse bewertet. Ein Unternehmen kann für einzelne Prozesse unterschiedliche Reifegradstufen erreichen.
- Im Gegensatz zu CMM wird die Kundenorientierung explizit berücksichtigt.
- Es gibt bisher nur wenig praktische Erfahrungen, insbesondere mit den oberen Reifegradstufen.
- Neue Begriffe wurden ohne Rückgriff auf vorhandene betriebswirtschaftliche Begriffe der Geschäftsprozessanalyse eingeführt.
(4.6) Business Process Reengineering (BPR)
Da die Softwareentwicklung als Prozess der betrieblichen Leistungserstellung aufgefasst werden kann, lassen sich deren Abläufe mit Methoden der Geschäftsprozess- und Workflow-Analyse gestalten. Ansätze wie CMM oder SPICE sind evolutionär und werden als Business Process Improvement (BPI) bezeichnet.
Im Gegensatz dazu schlagen Hammer und Champy mit dem Business Process Reengineering (BPR) einen revolutionären Weg vor: Abläufe sollen nicht schrittweise verbessert, sondern fundamental und radikal verändert werden, um Verbesserungen um ganze Größenordnungen zu erzielen. Die Vorgehensweise des BPR lässt sich wie folgt charakterisieren:
- Konzentration auf Kernprozesse (Wertschöpfungsprozesse), die einen unmittelbaren Kundennutzen hervorbringen.
- Schlanke Prozesse, d. h. Verbesserung durch Weglassen, Zusammenfassen, Ändern der Reihenfolge und Parallelisieren von Funktionen.
- Vorgabe von Prozesszielen (Kosten, Zeit, Qualität, Flexibilität) und Einführen von Prozessverantwortung.
- Einführen von Prozessvarianten.
- Delegation von Verantwortung auf die Mitarbeiterebene.
- Reduktion des Steuerungs- und Kontrollbedarfs.
BPR bewerten wir folgendermaßen:
- Für die Neugestaltung der SW-Entwicklungsprozesse ist der revolutionäre BPR-Ansatz zu allgemein und daher kaum geeignet.
- Der evolutionäre Ansatz des BPI (wie in CMM oder SPICE) ist vorzuziehen, da diese speziell für die Verbesserung von SW-Entwicklungsprozessen konzipiert wurden.
- Aus betriebswirtschaftlicher Sicht wäre es sinnvoll, die BPI-Vorgehensweisen mit Begriffen der Geschäftsprozessanalyse zu beschreiben, um unnötige Begriffsvielfalt zu vermeiden und die SW-Entwicklung als branchenspezifischen Wertschöpfungsprozess einheitlich darzustellen.
Hier ist die Zusammenfassung der Kapitel 5 und 5.1 bis 5.1.5 im gewünschten Layout, komplett ohne Zitat-Formatierungen und unter strikter Einhaltung der Regel, Aufzählungen nur so zu verwenden, wie sie im Originaltext stehen:
(5) Wirtschaftlichkeit der Software-Entwicklung
Den SW-Entwicklungsprozess kann man als speziellen Geschäftsprozess der betrieblichen Leistungserstellung auffassen. Die Leistung aus diesem Geschäftsprozess kann bereitgestellt werden für:
- externe Kunden: In diesem Fall wird Individual- oder Standardsoftware für den Markt entwickelt. Es handelt sich um einen Kern- oder Wertschöpfungsprozess eines SW-Unternehmens.
- interne Kunden: In diesem Fall wird z.B. im Rahmen eines internen Projekts Individualsoftware entwickelt. Es handelt sich um einen Unterstützungsprozess, mit einer betrieblichen Leistung im Sinne einer Eigenentwicklung (selbsterstelltes Investitionsgut).
Wie bei Wertschöpfungsprozessen üblich, muss man auch beim speziellen Geschäftsprozess der SW-Entwicklung neben Zeit- und Qualitätszielen die Kostenziele und damit die Wirtschaftlichkeit der Leistungserstellung berücksichtigen. Die Kostenziele werden durch die allgemeinen Grundsätze von sinkenden Stückkosten, hohen Losgrößen und einer abnehmenden Fertigungstiefe geprägt. Diese betriebswirtschaftlichen Prinzipien haben folgenden Bezug zur SW-Entwicklung:
- Wiederverwendbarkeit von Software, d. h. geplante Wiederverwendung von Modulen oder Komponenten,
- SW-Sanierung, d. h. im Gegensatz zur geplanten Entwicklung der Wiederverwendbarkeit, eine ungeplante Wiederverwendung von Anwendungssystemen,
- SW-Beschaffung, d. h. kostengünstige oder kostenfreie Beschaffung (z. B. Nutzung von Open-Source-Software) von einmal produzierten, handelsüblichen SW-Produkten oder von (Standard-)Anwendungssoftware.
- SW-Reproduktion und Maintenance, d. h. Entwicklung eines Prototyps des Softwareprodukts und geplante Wiederverwendung durch Wartung, Weiterentwicklung und Vertrieb von mehreren Exemplaren desselben Produkts (d. h. Mehrfachverkauf desselben SW-Produktes in Form von neuen Releases).
Wirtschaftlichkeit erreicht man hierbei nicht nur durch verbesserte Entwicklungsprozesse, sondern vor allem durch Wiederverwendung bereits vorhandener Software. Durch Weiterentwicklung und Wiederverwendung lassen sich die Produktivität erhöhen, die Qualität durch sorgfältigere Produktion verbessern, die Entwicklungszeiten reduzieren und die Stückkosten drastisch senken.
(5.1) Wiederverwendung
(5.1.1) Voraussetzungen der Wiederverwendbarkeit
Den Einsatz wiederverwendbarer Software bezeichnet man als geplante Wiederverwendung (re-use). Das Erstellen und Bereitstellen solcher Software bezeichnet man als Wiederverwendbarkeit (reusability). Hierbei geht es darum, Komponenten im Vorfeld so zu konzipieren, dass sie später in anderen Systemen einfach wieder eingesetzt werden können. Als Komponente gilt dabei ein Softwareteil, der über eine wohldefinierte Schnittstelle genau festgelegte Funktionen bereitstellt. Wiederverwendbare Komponenten sollten folgende Anforderungen erfüllen:
- hoher Grad an Allgemeingültigkeit (z. B. durch Verwendung von Referenzmodellen),
- hoher Qualitätsstandard und gute Dokumentation.
Bei der Wiederverwendung von Software kann man folgende Typen unterscheiden:
- Wiederverwendung bei Versionenentwicklung (von einem SW-System werden nacheinander mehrere Versionen entwickelt),
- Wiederverwendung bei Variantenentwicklung (von einem SW-System werden durch Parametereinstellung und Customizing mehrere Varianten entwickelt),
- Intraproduktorientierte Wiederverwendung (innerhalb eines Systems wird in unterschiedlichen Subsystemen dieselbe Komponente wiederverwendet),
- Interproduktorientierte Wiederverwendung (eine Komponente wird z. B. in einer Bibliothek zur Verfügung gestellt und kann in verschiedenen Systemen immer wieder eingesetzt werden).
Bei der Implementierung von Komponenten unterscheidet man zudem folgende Arten der Wiederverwendung:
- Black-Box-Wiederverwendung: Die Komponenten sind für ihre Funktionsausführung parametrisierbar. Es besteht kein Zugriff auf das Innere der Komponenten, sodass sie unverändert übernommen werden.
- White-Box-Wiederverwendung: Die Komponenten lassen sich parametrisieren, anpassen und in ihrem inneren Aufbau verändern (z. B. im Rahmen des Customizing). Sie müssen nach der Modifikation jedoch neu getestet werden.
(5.1.2) Softwaretechnischer Ansatz
Die Wiederverwendung wird traditionell durch Modularisierung und Funktionsbibliotheken unterstützt. In Abhängigkeit vom Abstraktionsniveau unterscheidet man bei der Wiederverwendung:
- Funktionale Abstraktion: Hier dienen Funktionen, Prozeduren und Makros der Wiederverwendung.
- Datenabstraktion: Hier werden abstrakte Datenobjekte und Datentypen (mit gekapselten Attributen und Operationen) wiederverwendet.
- Klassen mit Wiederverwendung durch Vererbung und Polymorphie: Klassen und objektorientierte Komponenten bieten die besten Möglichkeiten der Wiederverwendbarkeit. Das Ziel der Wiederverwendung besitzt folgende Charakteristiken:
- Vererbung erlaubt Spezialisierung durch eine Black-Box-Wiederverwendung, bei der die Originalklasse nicht geändert werden muss.
- Minimaler Codierungsaufwand, wenn einer Klasse zusätzliche Eigenschaften hinzugefügt werden sollen.
- Die Komplexität des Systems wird auf den Austausch von Nachrichten verlagert.
- Viele Objektebenen können zu einer unübersichtlichen, im Code schwer durchschaubaren Vererbungshierarchie führen.
Die Komponentenarchitektur beschreibt die statischen und dynamischen Beziehungen von wiederverwendbaren Komponenten, die zu Subsystemen und schließlich zum Gesamtsystem zusammengefasst (komponiert) werden. Hieraus können sehr komplexe, kommerziell erwerbbare COTS-Komponenten (commercial off the shelf) entstehen. Die serviceorientierte Architektur (SOA) erweitert diese Möglichkeiten durch wiederverwendbare Services, die plattformunabhängig und in sich abgeschlossen fachliche Funktionalitäten (oft über das Internet) bereitstellen. Im Mittelpunkt der SOA steht das Angebot von fachlich spezifizierten Diensten (Services), deren Merkmale und Eigenschaften sich wie folgt charakterisieren lassen:
- Ein Dienst ist eine IT-Repräsentation einer fachlichen Funktionalität.
- ist in sich abgeschlossen (autark) und kann eigenständig genutzt werden.
- ist in einem Netzwerk verfügbar.
- hat eine wohldefinierte veröffentlichte Schnittstelle (Vertrag). Für die Nutzung reicht es, die Schnittstelle zu kennen. Kenntnisse über die Details der Implementierung sind hingegen nicht erforderlich.
- ist plattformunabhängig, d. h. Anbieter und Nutzer eines Dienstes können in unterschiedlichen Programmiersprachen auf verschiedenen Plattformen realisiert sein.
- ist in einem Verzeichnis registriert.
- ist dynamisch gebunden, d. h. bei der Erstellung einer Anwendung, die einen Dienst nutzt, braucht der Dienst nicht vorhanden zu sein. Er wird erst bei der Ausführung lokalisiert und eingebunden.
- sollte wenige Kopplungen besitzen, um die Abhängigkeit zwischen verteilten Systemen zu senken.
(5.1.3) Organisatorischer Ansatz
Der reine Einsatz technischer Mittel reicht nicht aus, um Wiederverwendbarkeit zu garantieren. Man muss diese mit folgenden Maßnahmen organisatorisch unterstützen:
- Aufbau, Einrichtung und Betrieb eines Wiederverwendbarkeitsarchivs,
- Evolutionäre Verbesserung der Wiederverwendbarkeit,
- Einbetten des Ziels der Wiederverwendung in den gesamten SW-Entwicklungsprozess.
Die evolutionäre Verbesserung der Wiederverwendbarkeit kann in verschiedenen Ausbaustufen erfolgen:
- Ad-Hoc-Wiederverwendung (z. B. abhängig vom Erinnerungsvermögen eines langjährig tätigen Mitarbeiters).
- Wiederverwendung der bisher entwickelten und verfügbaren Software.
- Gezielte Entwicklung wiederverwendbarer Software: Hierbei wird die wiederverwendbare Software gezielt aufgrund einer Analyse für eine bestimmte Anwendungsdomäne erstellt (z. B. zur Unterstützung von bestimmten betrieblichen Funktionen oder bestimmter Geschäftsprozesse, vgl. SOA).
- Verwendung von Domänenmodellen zur Steuerung der Wiederverwendbarkeit (z. B. Wahl von wiederverwendbaren Komponenten für verschiedene Varianten eines Geschäftsprozesses aufgrund von Geschäftsprozessmodellen; vgl. Prozessauswahlmatrix von SAP R/3) Der Schwerpunkt der Entwicklungsarbeit liegt auf der Abstraktion der Modellierung, nicht auf der Programmierung.
- Ausrichtung der gesamten Software-Entwicklungsorganisation am Ziel der Wiederverwendung.
Durch Integration in den Entwicklungsprozess wird zu Beginn einer Phase nach nutzbaren Komponenten gesucht, diese werden während der Phase genutzt und am Ende der Phase werden neu erstellte Komponenten zur späteren Nutzung archiviert.
(5.1.4) Managementansatz
Die praktische Durchsetzung der Wiederverwendbarkeit ist eine strategische Aufgabe des Innovations- und Changemanagements. Da das Tätigkeitsprofil der SW-Entwickler weg von der Neuentwicklung hin zum Suchen, Anpassen und Montieren von fremden Komponenten wandert, erfordert dieser Kulturwandel langfristige Bemühungen. Hierzu zählen Schulungen, der Abbau psychologischer Vorbehalte gegenüber "fremder" Software und die Etablierung eines Anreizsystems.
(5.1.5) Kosten/Nutzen der Wiederverwendung
Die Einhaltung der Anforderungen an die Wiederverwendbarkeit verursacht zusätzliche Entwicklungskosten von schätzungsweise 30 bis 50 %. Als grobe Faustregel für die Amortisation gilt die 2-mal-3-Regel:
- Software muss dreimal entwickelt werden, bevor sie wirklich wiederverwendbar entwickelt ist.
- Software muss dreimal wiederverwendet werden, bevor der Break-Even-Point der wirtschaftlichen Rentabilität erreicht ist; d. h. erst nach dreimaliger Wiederverwendung haben sich die höheren Entwicklungskosten der Wiederverwendbarkeit amortisiert.
(5.2) Sanierung von Software
In der Praxis der Softwaretechnik beginnt man selten ganz von vorne, da meist bereits viele IT-Systeme im Einsatz sind. Bei diesen Systemen sind Anpassungen und Weiterentwicklungen wirtschaftlich oft sinnvoller als eine komplette Neuentwicklung. Durch die sogenannte Maintenance, bei der die Phasen Entwicklung, Evolution und Erhaltung mehrfach durchlaufen werden, lässt sich die Lebensdauer von Software verlängern. Dies ist ein entscheidender Ansatz, um die Wirtschaftlichkeit eines Softwareprodukts durch eine längere Nutzungsdauer beträchtlich zu verbessern.
(5.2.1) Software-Altsysteme (Legacy-Systeme)
Software unterliegt in der Regel einem Alterungsprozess, der mehrere Ursachen haben kann:
- Änderung der ökonomischen, institutionellen oder gesetzlichen Rahmenbedingungen (z. B. Änderung der Geschäftsprozesse, Euro-Einführung).
- Änderungen der Hardware- und der Softwaretechnik (z. B. Client/Server-Lösungen, neue Programmiersprachen, Objektorientierung).
- Programmänderungen durch laufende Wartungsarbeiten und wiederholte Anpassungsmaßnahmen. Häufige Eingriffe unter Zeitdruck verwässern die Architektur und infizieren die Software mit neuen Fehlern (oft als "ignorant surgery" kritisiert).
Hierdurch entstehen sogenannte Altsysteme oder Legacy-Systeme, die meist noch lebenswichtige Funktionen für das Unternehmen erfüllen, aber schwer zu warten sind. Die Aktivitäten zur Software-Sanierung lassen sich aus dem Wasserfallmodell ableiten und umfassen die Vorwärtsentwicklung (Forward Engineering), die Rückwärtsentwicklung (Reverse Engineering) sowie das Reengineering (Renovation). Der Begriff der Sanierung fungiert als Sammelbegriff für all diese Tätigkeiten, die letztlich zu einem überarbeiteten System führen.
(5.2.2) Techniken der Sanierung
Die Sanierung ist ein Transformationsvorgang, bei dem verschiedene Verfahren zum Einsatz kommen.
Eine einfache Methode ist das Verpacken von Altsystemen (Wrapping), bei dem Elemente eines Altsystems nach außen hin so abgekapselt werden, dass eine objektorientierte Nutzung möglich wird (Wrapper). Dies erlaubt eine stufenweise Migration, hat aber den Nachteil, dass die veraltete interne Architektur unverändert bleibt.
Um ein System tiefgreifender zu sanieren, muss man es zunächst verstehen und bewerten. Hierfür nutzt man Reverse Engineering, um Designinformationen aus dem Quellcode zurückzugewinnen, sowie die Redokumentation, die sich auf statische oder dynamische Analysen stützt. Anschließend kann man das Programm restrukturieren, um Transparenz und Übersichtlichkeit zu erhöhen. Hierbei nutzt man folgende Maßnahmen:
- Reformatierung: Optische Aufbereitung des Quellprogramms.
- Code-Restrukturierung: Entflechtung eines undurchsichtigen Spaghetti-Codes.
- Modularisierung: Zerlegen und Verpacken von Programmteilen in Module und Verkapselung der Daten.
- Daten-Restrukturierung: Standardisierung von Bezeichnungen und Veränderung der internen Datenstrukturen.
Nach dem Verstehen des Altsystems kann man es stufenweise verändern und verbessern. Hierbei unterscheidet man:
- Code-Transformation: Erforderlich bei einem Compiler- oder Sprachwechsel.
- Recodierung: Neucodierung unter Vorlage des Altsystems.
- Refaktorierung: Verbesserung der Quellcode-Struktur, ohne das äußere Programmverhalten zu verändern.
- Portierung: Umstellung auf eine bisher nicht unterstützte Systemumgebung.
- Optimierung: Verbesserung des Laufzeitverhaltens oder Reduzierung des Ressourcenbedarfs.
- Redesign: Neukonzeption von Systemteilen oder Erweiterung der Funktionalität.
(5.2.3) CARE-Werkzeuge
Analog zu CASE-Werkzeugen für das Forward Engineering werden für die Sanierung und das Reverse Engineering sogenannte CARE-Werkzeuge (Computer Aided Reverse Engineering) eingesetzt. Im Mittelpunkt steht auch hier ein Repository. Zu diesen Werkzeugen ist Folgendes anzumerken:
- Besonders hilfreich sind CARE-Werkzeuge für die Restrukturierung, die Redokumentation oder die Code-Transformation.
- Andere Sanierungsmaßnahmen werden nur eingeschränkt unterstützt.
- CARE-Werkzeuge sollten, falls vorhanden, in die CASE-Umgebung integriert sein.
Ihr Einsatz kann den Wartungs- und Sanierungsaufwand verringern und die wirtschaftliche Lebensdauer von Legacy-Systemen erheblich verlängern.
(5.2.4) Kosten/Nutzen der Sanierung
Bei der Abwägung von Kosten und Nutzen sollte man stets folgende Alternativen prüfen:
- Weiterführung der korrektiven und adaptiven Wartung eines vorhandenen Altsystems,
- Sanierung des Altsystems,
- Ablösung des Altsystems und Neuentwicklung (make) oder
- Ablösung des Altsystems und Beschaffung von Standardanwendungssoftware (buy).
Stehen wirtschaftliche Überlegungen im Vordergrund, bewertet man das Altsystem unter softwaretechnischen Qualitätskriterien, unter dem Gesichtspunkt der betriebswirtschaftlichen Bedeutung, unter dem Gesichtspunkt der Änderbarkeit des Systems sowie auf der Grundlage eines Vergleichs des Nutzwertes des alten und neuen Systems und unter Berücksichtigung der Risiken. Zur Visualisierung kann hier eine Portfolioanalyse genutzt werden.
Für jede Alternative müssen die voraussichtlich anfallenden Kosten für die Restlebensdauer kalkuliert werden. Dabei ist Folgendes zu berücksichtigen:
- Die Kosten einer Sanierung betragen in der Regel nur 1/4 der Kosten einer Neuentwicklung.
- Die Risiken einer Neuentwicklung sind in der Regel zwei- bis dreimal so hoch wie bei einer Sanierung. Das bedeutet, dass die Sanierung immer dann eine günstige Alternative ist, wenn die Datenstruktur und die Funktionalität weitgehend konstant bleiben.
- Bei der Neuentwicklung oder der Sanierung konkurrieren die Entwicklungskosten oder die Sanierungskosten mit der Ablösung und der Neubeschaffung einer Standardanwendungssoftware.
- Für den Kostenvergleich einer Neubeschaffung ist von einer Summe auszugehen, die sich aus den Kosten für die Beschaffung der Software und dem Aufwand für das Customizing zusammensetzt. Bei hohem, unsicherem Customizingaufwand kann die Sanierung eines Altsystems eine relativ sichere und kostengünstige Alternative darstellen.
(5.3) Software-Wirtschaft: Reproduktion und Vermarktung von Software
(5.3.1) Kostenarten und Deckungsbeitrag
Bei der betriebswirtschaftlichen Beurteilung der Wirtschaftlichkeit der Entwicklung von marktfähiger Software unterscheidet man zwischen den:
- Kosten der Produktion: Kosten für die (Erst-)Entwicklung eines Prototyps der marktfähigen Standardsoftware und den
- Kosten der Reproduktion: Kosten für das Anfertigen von Kopien, für den Vertrieb und die Verteilung eines marktfähigen SW-Produktes.
Eine gewisse Sonderstellung nehmen hier handelsübliche Softwareprodukte ein, die ohne wesentliche Hilfe des Herstellers installiert werden und direkt an den Kunden übergeben werden (sogenannte Regalsoftware oder COTS). Bei der Softwareproduktion liegt eine atypische Kostensituation mit einer starken Stückkostendegression vor. Die Gesamtkosten der Produktion eines Prototyps bestehen aus einem immens hohen Fixkostenblock. Demgegenüber entstehen bei der Erhöhung der Absatzmenge nur sehr geringe variable Reproduktionskosten (beim Vertrieb über das Internet liegen diese nahezu bei null).
Die sich daraus ergebende Degression der Stückkosten ist der wirtschaftlich eindrucksvollste Effekt der Wiederverwendung von Software. Da die Grenzkosten verschwindend gering sind, erreicht der Deckungsbeitrag (als Differenz aus Verkaufspreis und Grenzkosten) bei jedem verkauften Exemplar nahezu den kompletten Betrag des Verkaufspreises.
(5.3.2) Preispolitik und Geschäftsstrategie
Rechnet man die theoretische Gewinnmaximierung aus, liefert diese als formale Untergrenze für die Preisfixierung die Höhe der Grenzkosten. Das würde bedeuten, dass Software extrem billig sein müsste. Gegen dieses Modell gibt es jedoch zwei gewichtige wirtschaftliche Einwände: Zum einen hängt die Absatzmenge in der Realität vom Preis ab, weshalb die Preiselastizität der Nachfrage berücksichtigt werden muss. Zum anderen klammert das rein theoretische Modell die Cash-Flows aus. Da Entwicklungskosten meist vorfinanziert werden, muss zur Vermeidung einer Insolvenz zwingend auch der Kapitaldienst (Tilgung, Zinsen, Risikoaufschlag) in den Preis einkalkuliert werden.
Aus diesen theoretischen Betrachtungen lassen sich jedoch einige Tendenzen und Geschäftsstrategien ableiten:
- Bei starkem Wettbewerbsdruck erfolgt ein rascher Verfall der SW-Preise bis zu der durch die Grenzkosten vorgegebenen Preisuntergrenze (nahe Null).
- Man kann versuchen, durch Senkung des Preises hohe Stückzahlen zu produzieren bzw. zu verkaufen, wenn die Nachfrage entsprechend elastisch reagiert.
- Bei Grenzkosten nahe null könnte man die Software (zunächst) verschenken und versuchen, durch begleitende Aktivitäten (softwarenahe Dienstleistungen wie Beratung, Schulung, Dokumentation, Verkauf von Publikationen usw.) und durch späteren Kauf aufgrund des Gewohnheitsverhaltens der (unentgeltlichen) Nutzung einen Deckungsbeitrag zu erwirtschaften.
- Durch Kundenbindung, zugehörige Dienstleistungen, Beratung, Werbeeinnahmen, Schulung, Fachliteratur und den Verkauf von Updates oder komplementärer (Soft- und Hardware-)Produkte kann man Deckungsbeiträge erwirtschaften und sich langfristig eine dominierende Markt- und Gewinnposition aufbauen und sichern.
(5.3.3) Open-Source-Software
Eine spezielle wirtschaftliche Situation findet sich auch bei Open-Source-Software. Hierunter versteht man SW-Programme oder Komponenten, deren Quelltext für jedermann einsehbar und frei verfügbar ist und die daher die Entwicklungskosten erheblich senken können. Merkmale und Eigenschaften von Open-Source-Software sind:
- Freier Zugriff auf den offengelegten Quellcode.
- Beliebige Anpassbarkeit an individuelle Bedürfnisse.
- Keine Abhängigkeit von einem SW-Hersteller.
- Kollaborative Entwicklung, Wartung und Weiterentwicklung durch eine große Anzahl von Anwendern.
- White-Box-Wiederverwendung ermöglicht das Aufdecken von Fehlern.
- Kostenlose Entwicklung und Weiterentwicklung auf der Basis einer Aufmerksamkeitsökonomie: Das Interesse der Entwickler besteht in der Regel nicht in einer adäquaten monetären oder materiellen Entlohnung, sondern in einer durch Aufmerksamkeit, Bekanntheit und Anerkennung begründeten (immateriellen) Belohnung.
Firmen, die sich mit hohen Summen an der Entwicklung beteiligen, setzen einerseits auf eine geringere Fertigungstiefe, da sie die Basissoftware wiederverwenden können. Andererseits nutzen sie den Bekanntheitsgrad von Open-Source-Produkten als Absatzförderung. Die eigentlichen Deckungsbeiträge werden in diesem Modell nicht mehr durch die Software selbst, sondern durch nachgelagerte softwarenahe Dienstleistungen wie Customizing, Fachliteratur oder Schulungen erwirtschaftet.