Referenzarchitekturen
(1) Definition von Referenzarchitekturen
Referenzarchitekturen fungieren als standardisierte Blaupausen und Muster für die Softwareentwicklung, indem sie bewährte Methoden und Technologien in einer vordefinierten Struktur bündeln. Sie beschreiben die essenziellen Komponenten, Schnittstellen sowie Interaktionen eines Systems und geben klare Regeln vor, die Entwicklern als gemeinsamer Orientierungsrahmen dienen. Durch diese stabilen Vorlagen müssen Teams das Rad nicht neu erfinden, sondern können auf einer validierten Basis aufbauen, was die Arbeitseffizienz steigert und sicherstellt, dass die Anwendung auf etablierten Technologien fußt. Häufig sind diese Referenzarchitekturen fester Bestandteil größerer Architektur-Frameworks, die Standards und Best Practices für die Implementierung definieren.
Ein wesentliches Merkmal von Referenzarchitekturen ist ihre universelle Einsetzbarkeit über verschiedene Branchen und Technologien hinweg, sei es für Web-Anwendungen, das Internet der Dinge (IoT) oder Event-Driven Architectures. Der operative Nutzen zeigt sich in einer deutlichen Reduktion der Komplexität sowie einer erhöhten Wiederverwendbarkeit von Komponenten. Dies führt nicht nur zu einer verbesserten Skalierbarkeit und Wartbarkeit der Systeme, sondern beschleunigt auch den gesamten Entwicklungsprozess, da Interoperabilitätsprobleme von vornherein minimiert werden. Zusammenfassend bilden sie das Fundament für Qualität und Zuverlässigkeit, indem sie eine einheitliche Kommunikations- und Arbeitsbasis für alle Beteiligten schaffen.
Die Bedeutung von Referenzarchitekturen in der Softwareentwicklung begründet sich vor allem in ihrer Funktion als ordnendes und standardisierendes Element. Sie stellen Entwicklern ein festes Regelwerk und eine verbindliche Struktur bereit, was sich positiv auf fünf zentrale Qualitätsaspekte auswirkt.
Wiederverwendbarkeit
Zunächst fördern sie massiv die Wiederverwendbarkeit von Komponenten. Da die Architektur vorgibt, wie Bausteine konstruiert sein müssen, können diese einmal entwickelten Module kostensparend und zeitbeschleunigend in anderen Projekten erneut eingesetzt werden.
Reduzierung der Komplexität von Softwareanwendungen
Parallel dazu dient die Referenzarchitektur der Reduzierung von Komplexität. Besonders in großen Organisationen, in denen viele Entwickler an umfangreichen Systemen arbeiten, verhindert die Vorgabe einer gemeinsamen Struktur das Entstehen von unübersichtlichem „Wildwuchs“ und hält das Gesamtsystem beherrschbar.
Interoperabilität
Ein weiterer essenzieller Aspekt ist die Interoperabilität. Damit unterschiedliche Anwendungen und Systeme reibungslos miteinander kommunizieren können, erzwingt die Referenzarchitektur einheitliche Standards und Schnittstellen, die als gemeinsame Sprache fungieren.
Skalierbarkeit
Auch für die Zukunftssicherheit ist gesorgt, da die Architekturregeln von vornherein die Skalierbarkeit berücksichtigen. Dies stellt sicher, dass die Software bei steigenden Nutzerzahlen oder wachsenden Datenmengen stabil bleibt und nicht strukturell kollabiert.
Wartbarkeit
Schließlich wird durch die Standardisierung die Wartbarkeit optimiert. Da der Aufbau der Software bekannten Mustern folgt, finden sich Entwickler schneller zurecht, was die Fehlersuche erleichtert und Reaktionen auf Probleme deutlich beschleunigt.
(2.) Typen von Referenzarchitekturen
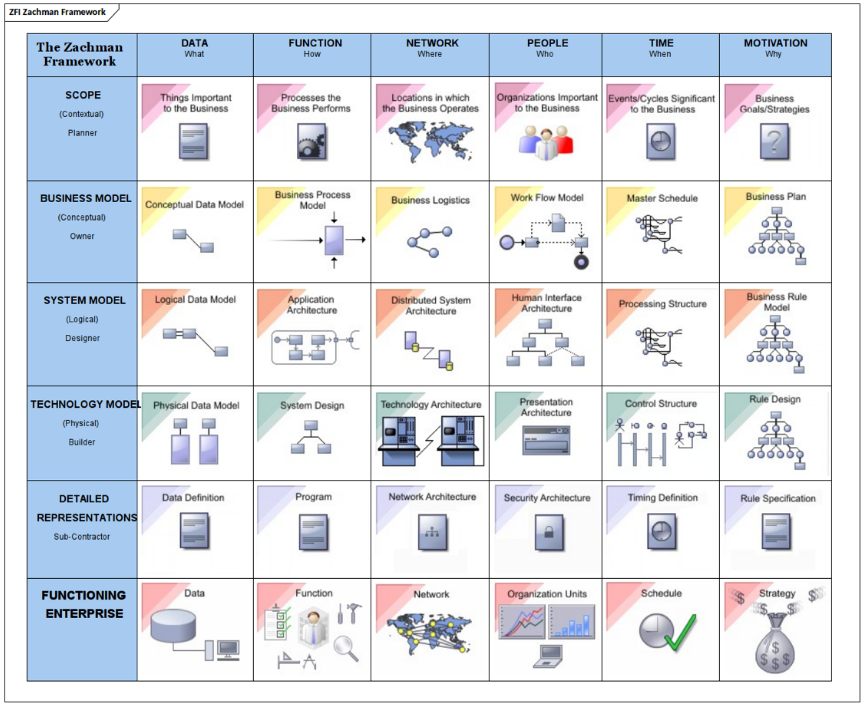
Referenzarchitekturen dienen als standardisierte Modellvorlagen für die Softwareentwicklung und werden je nach Anwendungszweck in verschiedene Typen klassifiziert. Eine fundamentale Kategorie bilden hierbei die Architektur-Frameworks, die meist von großen Organisationen, Regierungsbehörden oder Konsortien herausgegeben werden, um branchenspezifische Standards und Best Practices verbindlich zu definieren. Als klassisches Beispiel wird hier das Zachman Framework angeführt, welches die Unternehmensarchitektur durch eine komplexe Matrix aus sechs W-Fragen und sechs unterschiedlichen Perspektiven systematisch ordnet und analysierbar macht.
Ergänzend zu diesen übergeordneten Frameworks existieren technologisch fokussierte Referenzarchitekturen, die speziell für konkrete Anwendungsdomänen konzipiert wurden. Dazu zählen unter anderem Modelle für Web-Architekturen, Datenbankstrukturen, ereignisgesteuerte Systeme (Event-Driven Architecture), das Internet of Things (IoT) sowie Peer-to-Peer-Netzwerke. Jeder dieser spezifischen Typen bringt eigene Merkmale sowie individuelle Vor- und Nachteile für den jeweiligen Einsatzzweck mit sich.
Ungeachtet der spezifischen Ausprägung erfüllen alle Referenzarchitekturen denselben übergeordneten Zweck: Sie bieten Entwicklern einen verlässlichen Rahmen aus festen Strukturen und Regeln.
(2.1.) Architektur-Frameworks
Architektur-Frameworks sind Referenzarchitekturen, die typischerweise von Organisationen, Regierungsbehörden oder Konsortien entwickelt werden, um branchenspezifische Standards und Best Practices zu definieren. Diese Frameworks legen fest, wie eine Architektur modelliert werden sollte und welche Methoden und Technologien bei der Entwicklung von Softwareanwendungen eingesetzt werden sollten.
(2.1.1.) Zachman Framework
Das Zachman Framework bietet einen hochgradig strukturierten Ansatz zur Beschreibung und Entwicklung von Architekturen. Ursprünglich für die Informationstechnologie konzipiert, lässt es sich nahtlos auf die Softwareentwicklung übertragen, um komplexe Systeme ganzheitlich zu erfassen. Das Herzstück dieses Frameworks bildet eine Matrix aus sechs Zeilen und sechs Spalten, die unterschiedliche Perspektiven und Abstraktionsebenen miteinander verknüpft.
Die sechs Spalten repräsentieren dabei die fundamentalen W-Fragen der Architektur. Die Spalte
- "What" (Was) definiert die relevanten Datenobjekte und deren Beziehungen, während
- "How" (Wie) die Prozesse, Algorithmen und Implementierungsdetails beschreibt.
- Die physische und logische Infrastruktur, wie Netzwerke und Hardware, wird in der Spalte "Where" (Wo) verortet.
- Die Akteure, von Entwicklern bis zu Endanwendern, und ihre Verantwortlichkeiten fallen unter "Who" (Wer).
- Zeitliche Aspekte wie Projektphasen und Release-Zyklen werden in "When" (Wann) behandelt, während
- "Why" (Warum) die strategischen Ziele und Motivationen hinter der Entwicklung beleuchtet.
Die sechs Zeilen hingegen bilden die vertikalen Abstraktionsebenen ab, die vom Allgemeinen zum Spezifischen führen. Sie beginnen beim
- Scope (Umfang), der den organisatorischen Gesamtkontext absteckt, gefolgt vom
- Business Model, das die Geschäftsprozesse analysiert. Es schließt sich das
- System Model an, welches die Funktionalität abstrakt beschreibt, bevor im
- Technology Model konkrete Tools und Technologien festgelegt werden. Die
- Detailed Representations beinhalten die tiefsten Spezifikationen und Komponenten, bis schließlich das
- Functioning System das fertige, operative Produkt darstellt.
Durch diese Matrixstruktur fördert das Framework ein umfassendes Verständnis der Architektur und optimiert die Kommunikation zwischen den verschiedenen Stakeholdern, da jeder Aspekt seinen festen Platz hat.
(2.1.2.) C4-Modell
Das C4-Architekturframework ist ein leichtgewichtiges Framework, das zur Visualisierung von Softwarearchitekturen entwickelt wurde. Es ermöglicht die Erstellung von Architekturdiagrammen auf verschiedenen Abstraktionsebenen, um die Kommunikation und das Verständnis der Architektur zu verbessern. Das Framework besteht aus vier Hauptebenen: Context, Container, Component und Code.
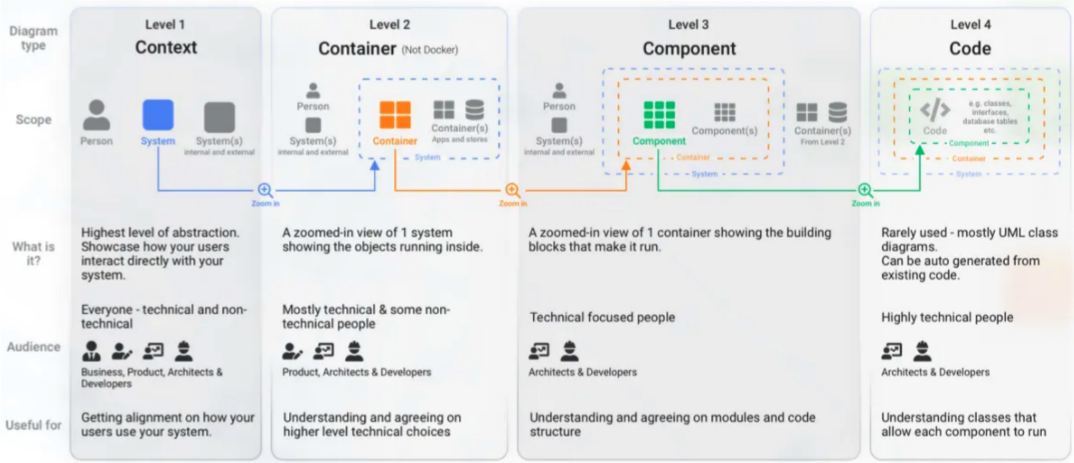
Das C4-Architekturframework verfolgt den Ansatz, komplexe Softwarearchitekturen durch vier verschiedene Abstraktionsebenen verständlich zu visualisieren und so die Kommunikation zwischen Entwicklern und Stakeholdern zu fördern.
- Die oberste Ebene bildet das Context-Diagramm, welches das System in seiner Umgebung mit allen externen Abhängigkeiten wie Benutzern und Fremdsystemen darstellt, um die Systemgrenzen zu definieren.
- Darauf folgt das Container-Diagramm, das in das System hineinzoomt und die wesentlichen ausführbaren Einheiten wie Webanwendungen, Datenbanken oder APIs sowie deren Kommunikationswege aufzeigt.
- Eine Stufe tiefer visualisiert das Component-Diagramm die interne Struktur dieser Container, indem es die wesentlichen Bausteine wie Module oder Dienste und deren Abhängigkeiten identifiziert, was das Verständnis für Modularität und Wiederverwendbarkeit schärft.
- Die detaillierteste Ebene ist das Code-Diagramm, welches die tatsächliche Implementierung, oft mittels Klassendiagrammen, abbildet.
Wichtig ist dabei, dass das C4-Modell keine starre Entwicklungsmethodik vorgibt, sondern sich rein auf die schrittweise und zielgruppengerechte Visualisierung der Architektur konzentriert, um ein gemeinsames Verständnis im Team zu schaffen.
(2.1.3.) RM-ODP (Reference Model for Open Distributed Processing)
Das RM-ODP (Reference Model for Open Distributed Processing) ist ein standardisiertes Architekturframework (ISO/IEC 10746) zur Entwicklung offener, verteilter Softwaresysteme. Ziel ist es, durch formalisierte Spezifikationssprachen eine kohärente, interoperable und wiederverwendbare Architektur zu schaffen, die Systeme unterschiedlicher technologischer Domänen integriert.
Der Kern des Frameworks besteht aus fünf Sichten (Viewpoints), die das System aus unterschiedlichen Perspektiven beleuchten:
- Enterprise View: Definiert den organisatorischen Kontext, die Geschäftsziele, Akteure und betrieblichen Abläufe.
- Information View: Beschreibt die Semantik, Struktur und die Beziehungen der verarbeiteten Daten sowie deren Fluss im System.
- Computational View: Zerlegt das System in funktionale Komponenten und Schnittstellen und definiert die Algorithmen der logischen Verarbeitung.
- Engineering View: Fokussiert auf die technischen Aspekte der Systementwicklung, inklusive der genutzten Werkzeuge, Methoden und Deployment-Prozesse, um die Architekturprinzipien umzusetzen.
- Technology View: Legt die konkrete Infrastruktur fest, inklusive Hardware, Betriebssysteme, Protokolle und Middleware.
Durch die Kombination dieser Sichten entsteht eine vollständige Systembeschreibung, die Konsistenz und technische Machbarkeit gleichermaßen sicherstellt.
(2.1.4.) SABSA Framework
Das SABSA-Framework (Sherwood Applied Business Security Architecture) ist ein spezialisierter Ansatz zur Entwicklung von Sicherheitsarchitekturen, der auch im Softwarekontext Anwendung findet. Es basiert auf einem strikten Top-Down-Prinzip, bei dem die Sicherheitsarchitektur nicht isoliert betrachtet, sondern direkt aus den Geschäftsanforderungen abgeleitet wird. Das Framework umfasst sechs architektonische Schichten und zielt darauf ab, Sicherheitsaspekte von der Anforderungsanalyse bis zur technischen Infrastruktur nahtlos zu integrieren. Ein zentraler Aspekt ist dabei die kontinuierliche Überwachung und Anpassung der Maßnahmen, um sicherzustellen, dass die Sicherheitsarchitektur stets mit den sich wandelnden geschäftlichen Zielen und Anforderungen synchron bleibt.

(2.1.5.) Beispiele von Referenzarchitekturen
Architekturmuster stellen eine konkrete Ausprägung von Referenzarchitekturen dar und bieten bewährte Lösungsansätze für wiederkehrende Probleme in der Softwareentwicklung. Ihr primäres Ziel ist die Steigerung der Effizienz sowie die Verbesserung zentraler Qualitätsmerkmale wie Wartbarkeit, Skalierbarkeit und Interoperabilität durch eine klare Strukturierung des Systems.
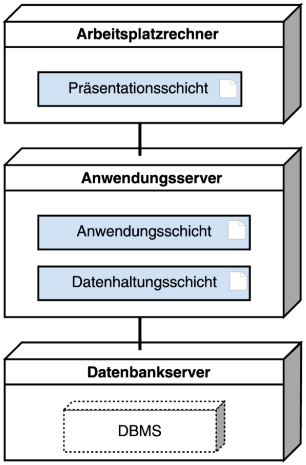
Schichtenarchitektur
Ein fundamentales Beispiel ist die Schichtenarchitektur, welche eine Anwendung horizontal in funktionale Ebenen unterteilt. Durch diese Zerlegung in kleinere, abgegrenzte Bereiche wird die Komplexität reduziert, was sowohl die Entwicklung als auch die spätere Wartung erleichtert.
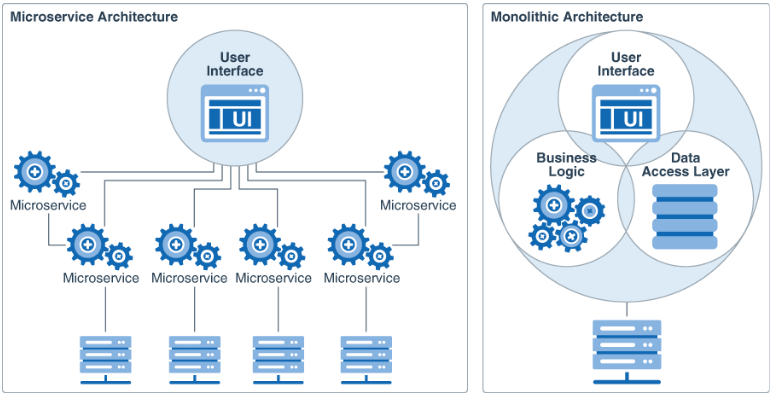
Microservices-Architektur
Im Gegensatz dazu fokussiert die Microservices-Architektur auf eine vertikale Aufteilung des Systems in kleine, voneinander unabhängige Dienste. Jeder dieser Dienste erfüllt eine spezifische Funktion, was zu einer enormen Flexibilität führt und eine gezielte Skalierbarkeit einzelner Komponenten ermöglicht.
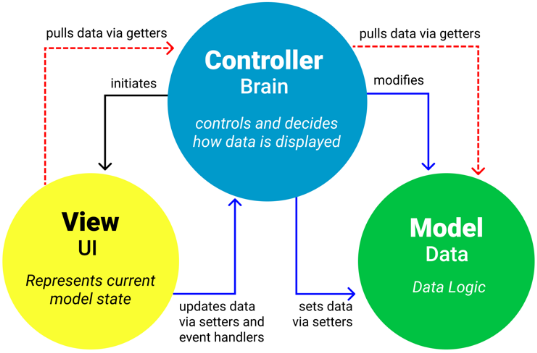
MVC
Das MVC-Muster (Model-View-Controller) hingegen strukturiert die interne Anwendungslogik durch die strikte Trennung von drei Verantwortlichkeiten: Das Modell verwaltet die Daten und Geschäftslogik, die View übernimmt die Darstellung, und der Controller steuert den Ablauf. Diese Entkopplung verbessert die Erweiterbarkeit und Übersichtlichkeit erheblich.
(3.) Nutzen von Referenzarchitekturen
Referenzarchitekturen sind in der Softwareentwicklung ein wichtiges Werkzeug, um die Entwicklung und Wartung von Softwareanwendungen zu erleichtern.
(3.1.) Verbesserte Wiederverwendbarkeit von Softwarekomponenten
Ein zentraler Vorteil von Referenzarchitekturen liegt in der deutlichen Verbesserung der Wiederverwendbarkeit von Softwarekomponenten. Indem sie eine klare und einheitliche Implementierungsweise vorgeben, schaffen sie Standards, die es Entwicklern ermöglichen, Bausteine effizient in verschiedenen Kontexten oder Anwendungen erneut zu nutzen. Da die Funktionsweise und Schnittstellen durch die Architektur definiert sind, entfällt der Aufwand, Komponenten jedes Mal neu zu verstehen oder anzupassen.
Dieser Effekt wird maßgeblich durch die Modularisierung verstärkt. Die Architektur fördert die Zerlegung komplexer Systeme in unabhängige, kleine Module. Das steigert nicht nur die Wiederverwendbarkeit, sondern auch die Flexibilität und Erweiterbarkeit des Systems: Einzelne Module lassen sich austauschen, aktualisieren oder entfernen, ohne die Stabilität der restlichen Anwendung zu gefährden (Vermeidung von Seiteneffekten).
Zusammenfassend führen diese Maßnahmen zu einer gesteigerten Produktivität und Softwarequalität. Es ist jedoch essenziell zu beachten, dass die Referenzarchitektur allein kein Garant für Erfolg ist. Damit die Wiederverwendbarkeit in der Praxis funktioniert, müssen die Komponenten zwingend gut dokumentiert sein und über klar definierte Schnittstellen verfügen.
(3.2.) Reduzierung der Softwarekomplexität
Referenzarchitekturen tragen maßgeblich zur Reduzierung der Softwarekomplexität bei, indem sie eine klare und einheitliche Implementierungsstruktur vorgeben. Dies verhindert Verwirrung unter den Entwicklern und stellt sicher, dass alle wesentlichen Aspekte der Anwendung effizient abgedeckt sind. Dadurch sinkt die Anfälligkeit für Fehler und Inkonsistenzen, die oft durch unklare Spezifikationen entstehen.
Ein weiterer Hebel zur Komplexitätsreduktion ist der Einsatz bewährter Methoden und Technologien. Indem die Architektur auf etablierte Muster und Best Practices setzt, wird das technische Risiko minimiert und die Integration aktueller Technologien in geordnete Bahnen gelenkt.
Zusätzlich fungiert die Referenzarchitektur als zentrales Kommunikationsinstrument. Sie schafft ein gemeinsames Verständnis („Single Source of Truth“) für das gesamte Entwicklungsteam. Dies vermeidet Missverständnisse, harmonisiert die Zusammenarbeit und sorgt dafür, dass alle Beteiligten auf einer gemeinsamen Basis effizient zusammenarbeiten.
(3.3.) Interoperabilität
Neben der internen Strukturierung verbessern Referenzarchitekturen maßgeblich die Interoperabilität zwischen verschiedenen Softwaresystemen. Indem sie auf standardisierte Schnittstellen und Best Practices setzen, stellen sie sicher, dass eine Anwendung reibungslos und effizient mit externen Systemen kommunizieren kann.
Dies erleichtert die Integration in bestehende IT-Landschaften erheblich. Wenn verschiedene Anwendungen auf denselben architektonischen Standards und Prinzipien basieren, lassen sie sich deutlich einfacher aneinander anpassen und verknüpfen. Diese technische Kompatibilität minimiert Integrationshürden und steigert die Gesamteffizienz im Zusammenspiel unterschiedlicher Softwarelösungen.
(3.4.) Skalierbarkeit
Referenzarchitekturen sind ein entscheidender Faktor für die Skalierbarkeit von Softwareanwendungen. Sie befähigen Systeme dazu, auf wachsende Leistungsanforderungen flexibel zu reagieren, ohne an Qualität oder Stabilität einzubüßen. Durch klare Implementierungsrichtlinien wird sichergestellt, dass die Anwendung von Beginn an für zukünftiges Wachstum und Erweiterungen ausgelegt ist ("Design for Scalability").
Dabei unterstützen Referenzarchitekturen die Entwickler durch die Bereitstellung bewährter Skalierungsmuster und Technologien. Anstatt ad hoc Lösungen zu entwickeln, werden etablierte Best Practices angewendet. Ein weiterer wesentlicher Aspekt ist die Überwachbarkeit: Die Architektur definiert Werkzeuge und Methoden zum Performance-Monitoring, wodurch Engpässe (Bottlenecks) frühzeitig identifiziert und gezielt optimiert werden können.
(3.5.) Wartbarkeit
Wartbarkeit bezeichnet die Fähigkeit eines Systems, effizient aktualisiert und an sich ändernde Nutzeranforderungen angepasst zu werden. Referenzarchitekturen spielen hierbei eine Schlüsselrolle, indem sie klare Richtlinien für eine wartungsfreundliche Implementierung vorgeben. Durch diese vorausschauende Strukturierung wird sichergestellt, dass die Software von Grund auf für zukünftige Eingriffe und Updates vorbereitet ist.
Zudem fördern Referenzarchitekturen den Einsatz bewährter Wartungsmuster und aktueller Technologien. Anstatt isolierte Lösungen zu schaffen, greifen Entwickler auf etablierte Best Practices zurück, was die Pflege des Systems langfristig erleichtert und die technische Aktualität der Anwendung sichert.
(4.) Einfluss der Referenzarchitektur auf die Softwarequalität
Referenzarchitekturen haben einen direkten, positiven Einfluss auf die Softwarequalität, wie das weit verbreitete MVC-Muster (Model-View-Controller) verdeutlicht. Dieses Muster strukturiert Anwendungen durch eine strikte Trennung in drei Hauptkomponenten:
- Model: Repräsentiert die Datenbasis und die Geschäftslogik.
- View: Ist für die Benutzeroberfläche und Darstellung verantwortlich.
- Controller: Verarbeitet Benutzereingaben und koordiniert den Datenfluss zwischen Model und View.
Der zentrale Qualitätsgewinn entsteht durch diese Trennung der Zuständigkeiten (Separation of Concerns). Da Daten, Darstellung und Steuerung entkoppelt sind, verbessert sich die Wartbarkeit enorm: Änderungen bleiben auf die jeweilige Komponente beschränkt und beeinflussen nicht das restliche System. Zudem lassen sich die isolierten Komponenten wesentlich einfacher und unabhängiger testen.
Generell ermöglicht der Einsatz solcher etablierten Referenzarchitekturen den Rückgriff auf bewährte Designmuster („Best Practices“), was Entwicklungsfehler und Inkonsistenzen reduziert. Abschließend gilt jedoch, dass keine Architektur universell passt; die Auswahl muss stets basierend auf den spezifischen Anforderungen und Zielen des jeweiligen Projekts erfolgen.
(5.) Einfluss der Referenzarchitektur auf die Arbeitsorganisation
Der Einsatz einer Referenzarchitektur nimmt direkten Einfluss auf die Arbeitsorganisation in der Softwareentwicklung. Sie fungiert als Effizienztreiber, indem sie klare Strukturen schafft, die das Risiko von Fehlern minimieren und die Qualität der Endprodukte steigern.
Zudem optimiert sie die Zusammenarbeit innerhalb des Teams. Durch die gemeinsame architektonische Basis können Entwickler effektiver kooperieren und deutlich schneller auf sich ändernde Anforderungen oder neue Marktbedingungen reagieren.
(5.1.) Das Gesetz von Conway
Das Gesetz von Conway besagt, dass die Struktur von Softwarearchitekturen zwangsläufig die Kommunikationsstrukturen der Organisation widerspiegelt, die sie entwirft. Die sozialen Dynamiken und Interaktionswege innerhalb eines Unternehmens prägen somit direkt das technische Design.
Dies verdeutlicht das Beispiel spezialisierter Teams (z. B. Frontend, Backend, Datenbank): Arbeiten diese Gruppen isoliert voneinander, entsteht fast zwangsläufig eine strikt modulare Architektur, bei der die Komponenten getrennt betrachtet werden und Schnittstellen oft suboptimal abgestimmt sind. Im Gegensatz dazu führt eine enge, teamübergreifende Zusammenarbeit zu einer integrierten Gesamtlösung mit nahtlosen Datenflüssen. Folglich sind organisatorische Faktoren – insbesondere Kommunikation und Koordination – entscheidend für die Qualität und Effektivität der Architektur.
(5.2.) Optimierung der Arbeitsorganisation
Referenzarchitekturen tragen maßgeblich zur Optimierung der Arbeitsorganisation bei, indem sie Arbeitsabläufe strukturieren und standardisieren. Am Beispiel der Microservices-Architektur wird dies besonders deutlich: Durch die Zerlegung des Systems in eigenständige, lose gekoppelte Komponenten können Teams unabhängig voneinander agieren.

Dies führt zu einer klaren Aufteilung der Verantwortlichkeiten, da jedes Team die volle Eigenverantwortung („Ownership“) für seinen spezifischen Service übernimmt. Gleichzeitig ermöglicht die Unabhängigkeit eine Parallelisierung der Entwicklung, was Arbeitsprozesse beschleunigt und die Time-to-Market verkürzt. Auch die Skalierung der Teams wird flexibler, da Personalressourcen gezielt dort angepasst werden können, wo es die Projektanforderungen eines einzelnen Services verlangen.
Hinsichtlich der Zusammenarbeit sorgen definierte Schnittstellen und Protokolle für reibungslose Integrationstests und ein einfacheres Management von Abhängigkeiten. Schließlich fördert die modulare Struktur die Wiederverwendbarkeit von Funktionalitäten, wodurch Redundanzen vermieden und die Entwicklungseffizienz bei neuen Features gesteigert wird.
(6.) Pflege und Wartung der Architektur
Die langfristige Relevanz von Referenzarchitekturen erfordert eine kontinuierliche Pflege und Wartung, da Technologien und Geschäftsanforderungen einem stetigen Wandel unterliegen. Ohne regelmäßige Updates veralten Standards, neue Frameworks werden ignoriert, und die Architektur verliert ihre Wirksamkeit als Leitfaden für Qualität und Skalierbarkeit.
Wichtige Gründe für die Wartung sind:
- Aktualität & Anpassungsfähigkeit: Integration neuer Technologien und Ausrichtung auf geänderte Geschäftsziele sorgen für Agilität.
- Qualität & Sicherheit: Durch das Beheben von Schwachstellen und Aktualisieren von Sicherheitsstandards werden Fehler und Risiken minimiert.
- Wissensmanagement & Konsistenz: Neue Erkenntnisse werden zentral dokumentiert, was eine einheitliche Arbeitsweise und die Zusammenarbeit zwischen Teams sichert.
Zur praktischen Unterstützung kommen spezifische Tools zum Einsatz:
- Architektur-Repositories & Modellierungswerkzeuge: Dienen der Verwaltung, Durchsuchbarkeit und Visualisierung der Architektur (z. B. Enterprise Architect, Lucidchart, Jira).
- Code-Analyse & Automatisierte Tests: Stellen sicher, dass Richtlinien eingehalten werden und die Architektur technisch funktioniert (z. B. durch statische Code-Analyse zur Identifikation von Sicherheitslücken).
(7.) Referenzarchitektur für die Webentwicklung
Webanwendungen sind heute essenziell und reichen von einfachen Seiten bis zu komplexen Systemen. Um Entwicklungszeiten zu verkürzen, Wartungskosten zu senken und die Qualität zu steigern, kommen spezifische Referenzarchitekturen zum Einsatz. Der Fokus liegt dabei auf zwei zentralen Bereichen:
-
Portalsoftware: Diese wird häufig im Unternehmensumfeld genutzt und stellt hohe Anforderungen an Sicherheit, Skalierbarkeit und Verfügbarkeit. Spezielle Referenzarchitekturen helfen dabei, diese kritischen Kriterien durch standardisierte Strukturen zu erfüllen.
-
Serverlose Webanwendungen (Serverless): Als relativ neuer Ansatz bieten serverlose Architekturen eine kosteneffiziente und hoch skalierbare Lösung. Referenzarchitekturen unterstützen hierbei, die spezifischen Merkmale dieses Modells optimal für die Entwicklung moderner Web-Apps zu nutzen.
(7.1.) Portalsoftware
Die Referenzarchitektur für Portalsoftware bildet die Grundlage für Webanwendungen, die als zentraler Aggregationspunkt dienen. Ein solches Portal bündelt Informationen, Anwendungen und Dienste aus verschiedenen internen wie externen Quellen auf einer einzigen, einheitlichen Benutzeroberfläche.
Um die Anforderungen an Sicherheit, Skalierbarkeit und Integration zu bewältigen, wird die Architektur typischerweise in fünf Schichten unterteilt:
- Benutzeroberflächenschicht: Realisiert die Interaktion mit dem Nutzer (z. B. via Widgets und Navigation) unter Einsatz von Webtechnologien wie HTML, CSS und JavaScript.
- Anwendungslogikschicht: Beinhaltet die Kernfunktionalität, steuert Services und verarbeitet die Geschäftslogik.
- Datenzugriffsschicht: Verwaltet den Zugriff auf Datenbanken und externe Systeme zum Abruf oder zur Speicherung von Informationen.
- Sicherheitsschicht: Da Portale oft sensible Daten bündeln, kümmert sich diese Schicht zentral um Authentifizierung, Autorisierung und Verschlüsselung.
- Integrations- und Erweiterungsschicht: Stellt über APIs und Schnittstellen die Verbindung zu Drittsystemen her und sichert die Erweiterbarkeit des Portals.
Dieser strukturierte Rahmen hilft Entwicklern, Portale effizient in bestehende IT-Ökosysteme einzubetten und dabei bewährte Praktiken für Wiederverwendbarkeit und Sicherheit einzuhalten.
(7.2.) Serverlose Webanwendungen
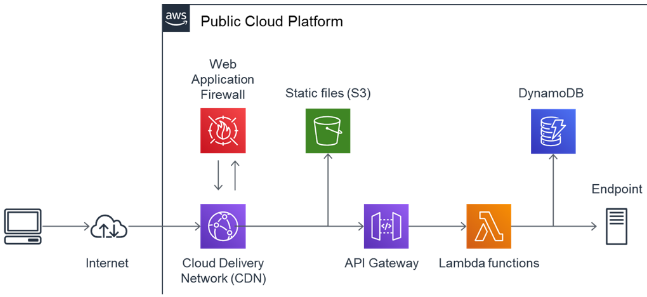
Eine serverlose Webanwendung basiert auf dem Konzept des Serverless Computing, bei dem die gesamte Infrastrukturverwaltung und Skalierung vom Cloud-Anbieter übernommen wird. Dies ermöglicht es Entwicklern, sich voll auf die Implementierung der Geschäftslogik zu konzentrieren, während sie von automatischer Skalierung und effizientem Ressourcenmanagement profitieren.
Die Architektur gliedert sich typischerweise in vier zentrale Bereiche:
- Die Benutzeroberfläche wird mit klassischen Webtechnologien (HTML, CSS, JavaScript) erstellt und kommuniziert über RESTful-APIs oder Websockets mit dem Backend.
- Ein API-Gateway dient als zentraler Einstiegspunkt für externe Anfragen und übernimmt Aufgaben wie Authentifizierung, Autorisierung und das Routing zu den entsprechenden Diensten.
- Die eigentliche Kernlogik residiert in Funktionen (wie AWS Lambda oder Azure Functions), die als unabhängige Code-Einheiten auf Ereignisse reagieren und spezifische Aufgaben erfüllen.
- Für die Datenhaltung werden serverlose Datenbank- und Speicherlösungen (beispielsweise AWS DynamoDB oder S3) genutzt, auf die die Funktionen zum Speichern und Abrufen von Informationen zugreifen.
(8.) Referenzarchitekturen für Datenbankmodelle und Data Warehouse
Datenbanken und Data Warehouses bilden das Rückgrat der IT-Infrastruktur, da sie die Basis für datengetriebene Geschäftsentscheidungen liefern. Die Wahl der passenden Referenzarchitektur ist dabei ausschlaggebend für die Leistung, Skalierbarkeit und Flexibilität der Systeme.
Der Fokus liegt auf zwei zentralen Bereichen:
-
Architektur für Datenbankmodelle: Hierbei geht es um die Optimierung der Datenbankstruktur und Performance, insbesondere bei relationalen Systemen wie Oracle, Microsoft SQL Server oder MySQL.
-
Architektur für Data Warehouses: Dieser Bereich konzentriert sich auf die effiziente Verarbeitung und Analyse großer Datenmengen. Moderne Referenzarchitekturen wie Amazon Redshift, Microsoft Azure Synapse Analytics oder Google BigQuery zielen darauf ab, diese Datenverarbeitungsprozesse massiv zu beschleunigen.
(8.1.) Datenbankmodelle
Referenzarchitekturen für relationale Datenbanken spielen eine wichtige Rolle bei der Entwicklung effizienter, skalierbarer und zuverlässiger Datenbanklösungen. Eine gute Referenzarchitektur bietet bewährte Praktiken, Standards und Empfehlungen für das Design, die Konfiguration und die Verwaltung relationaler Datenbanken. Sie ermöglicht es Entwicklern und Datenbankadministratoren, von bewährten Methoden zu profitieren und Zeit bei der Entwicklung von Lösungen zu sparen.
Die Wahl der richtigen Referenzarchitektur ist entscheidend, um eine solide Grundlage für den Aufbau einer effektiven Datenbankumgebung zu schaffen. Je nach Anbieter und spezifischen Anforderungen gibt es verschiedene Referenzarchitekturen, die von Unternehmen wie IBM, Oracle, Microsoft und Amazon Web Services entwickelt wurden.
(8.1.1.) ANSI-SPARC Architecture
Das ANSI-SPARC Architecture-Modell (auch bekannt als „Drei-Schema-Modell“) stammt aus den 1970er-Jahren und bildet das fundamentale Konzept für den Aufbau moderner Datenbanksysteme. Das primäre Ziel ist die Datenunabhängigkeit: Durch die Trennung von Design, Entwicklung und Nutzung wird die Anwendungslogik strikt von den physischen Datenstrukturen entkoppelt.
Das Modell gliedert sich in drei Hauptkomponenten:
- Externes Schema: Beschreibt die Sicht der Benutzer und Anwendungen auf die Datenbank. Durch Datenabstraktion wird sichergestellt, dass Nutzer nur Zugriff auf für sie relevante Informationen haben.
- Konzeptionelles Schema: Repräsentiert die globale, logische Struktur der Daten (Entitäten, Beziehungen, Regeln) und fungiert als Vermittler zwischen der externen und der internen Ebene.
- Internes Schema: Definiert die physische Speicherung, inklusive Datenstrukturen und Zugriffspfaden, um die Effizienz der Datenmanipulation zu gewährleisten.
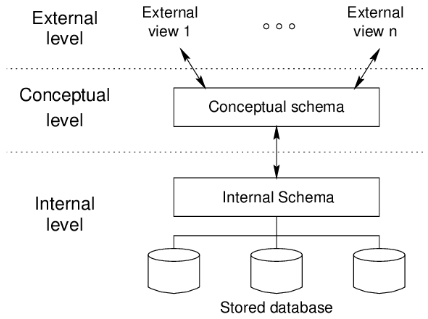
Der zentrale Vorteil dieser Architektur liegt in der Flexibilität: Änderungen an der logischen Struktur oder der physischen Speicherung (internes Schema) haben keine Auswirkungen auf die Anwendungen oder Benutzersichten (externes Schema).
(8.1.2.) IBM Information Management System (IMS)
Das IBM Information Management System (IMS) ist ein hierarchisches Datenbanksystem aus den 1960er-Jahren, das sich durch extreme Robustheit und Leistungsfähigkeit auszeichnet. Es organisiert Daten in einer Baumstruktur (Segmente, Datensätze, Felder) und ist speziell für die effiziente Verarbeitung massiver Datenmengen in Großunternehmen konzipiert.
Eine Kernstärke von IMS ist die Transaktionsverarbeitung: Es ermöglicht hohe Durchsatzraten bei gleichzeitiger Wahrung von Zuverlässigkeit und Datenintegrität - selbst bei Systemausfällen. Ergänzt wird dies durch den Transaction Manager (TM), der die korrekte Steuerung und den Abschluss von Transaktionen überwacht.
IMS ist hochgradig integrationsfähig und lässt sich über Schnittstellen nahtlos mit modernen Webanwendungen oder anderen Datenbanken verbinden. Haupteinsatzgebiete sind geschäftskritische Bereiche wie Banken oder Versicherungen, meist in Mainframe-Umgebungen, was spezialisiertes Expertenwissen für Betrieb und Entwicklung voraussetzt.
(8.1.3.) Oracle Databae Reference Architecture
Die Oracle Database Reference Architecture bietet einen bewährten Rahmen für den Entwurf, die Implementierung und den Betrieb von Oracle-Datenbanken in Unternehmen. Sie fokussiert sich primär auf Skalierbarkeit, Leistung, Verfügbarkeit und Sicherheit, um geschäftlichen Anforderungen gerecht zu werden.
Die Architektur gliedert sich in mehrere funktionale Schichten, die aufeinander aufbauen:
- Infrastruktur-Basis: Ganz unten steht die Hardware-Infrastruktur (Server, Netzwerk, Speicher) sowie das Betriebssystem (z. B. Oracle Linux oder Solaris), auf dem die Datenbank ausgeführt wird.
- Grid & Software: Die Oracle Grid Infrastructure fungiert als Cluster-Software für Hochverfügbarkeit und Ressourcenmanagement, während die Oracle Database Software die eigentliche Datenverwaltung, Transaktionsverarbeitung und Abfrageoptimierung übernimmt.
- Design & Entwicklung: Diese Schicht konzentriert sich auf die Strukturierung der Datenbank, einschließlich der Erstellung von Objekten (Tabellen, Indizes) unter Einhaltung von Designprinzipien.
- Sicherheit & Schutz: Umfasst Maßnahmen gegen unbefugten Zugriff und Datendiebstahl (Verschlüsselung, Rechteverwaltung) sowie Strategien für Hochverfügbarkeit und Notfallwiederherstellung (z. B. Data Guard, Backups).
- Verwaltung: Den Abschluss bildet die Überwachung und Verwaltung, die Leistungsanalysen, Patch-Management und Kapazitätsplanung sicherstellt.
(8.1.4.) Microsoft SQL Server Data Platform Architecture
Die Microsoft SQL Server Data Platform Architecture ist eine umfassende Umgebung für das Datenmanagement in Unternehmen, deren Herzstück die SQL Server-Datenbank-Engine bildet. Diese verwaltet nicht nur klassische relationale Daten, sondern unterstützt auch erweiterte Formate wie XML, Volltextsuche und geografische Informationen.
Um den reinen Speicher herum gruppieren sich spezialisierte Dienste, die den gesamten Datenzyklus abdecken:
- Integration (SSIS): Die Integration Services fungieren als ETL-Tool, um Daten effizient aus verschiedenen Quellen zu extrahieren, zu transformieren und zu laden.
- Analyse (SSAS): Die Analysis Services ermöglichen komplexes OLAP (Online Analytical Processing) und Data Mining mittels mehrdimensionaler Datenmodelle.
- Reporting (SSRS): Die Reporting Services dienen der Erstellung und Bereitstellung von Berichten in Formaten wie Excel, PDF oder HTML.
- Machine Learning: Durch die Machine Learning Services können statistische Analysen und ML-Modelle direkt in der Datenbank ausgeführt werden.
Erweitert wird die Plattform durch die Azure SQL-Datenbank, eine Cloud-native PaaS-Version, die skalierbare, verwaltete Datenbanken in der Cloud bereitstellt und nahtlos mit anderen Azure-Diensten integriert ist.
(8.2.) Data Warehouse
In der Industrie dominieren zwei gegensätzliche Philosophien für den Aufbau von Data Warehouses.
Das Kimball Dimensional Data Warehouse (nach Ralph Kimball) verfolgt den Ansatz des Dimensional Modeling. Ziel ist eine möglichst einfache und benutzerfreundliche Datenstruktur, die Analysen und das Reporting erleichtert. Diese Architektur optimiert die Abfrageleistung und dient als flexible Grundlage, um spezifische Data Marts für einzelne Geschäftsbereiche zu entwickeln.
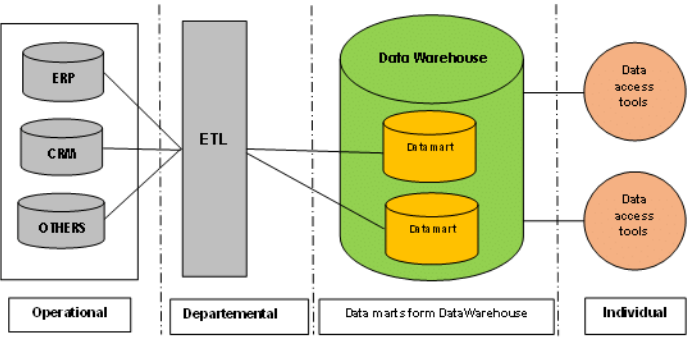
Demgegenüber steht die Corporate Information Factory (CIF). Dieser Ansatz fokussiert sich auf ein zentrales Enterprise Data Warehouse als einheitliche Datenquelle für das gesamte Unternehmen und zeichnet sich durch eine strikte Trennung von operativen und analytischen Daten aus. Die Struktur gliedert sich in vier funktionale Schichten:
- Operational Data Store (ODS): Dient als Zwischenspeicher, in dem operative Daten aus Quellsystemen gesammelt und für schnelle operative Abfragen integriert werden.
- Enterprise Data Warehouse (EDW): Das Herzstück der Architektur. Hier liegen alle Daten in einem einheitlichen Format vor, was komplexe Analysen über verschiedene Geschäftsbereiche hinweg ermöglicht.
- Data Marts: Spezifische Teilbereiche, die aggregierte Daten für bestimmte Abteilungen bereitstellen.
- Meta Data Repository: Speichert Beschreibungen zu Datenstrukturen, Quellen und Geschäftsregeln.
Die Wahl zwischen diesen Ansätzen hängt stark von den spezifischen Integrationsanforderungen und Zielen des Unternehmens ab.
(9.) Weitere Referenzarchitekturen
(9.1.) Event-Driven Architecture
Die Event-Driven Architecture (EDA) stellt Ereignisse (Events) in den Mittelpunkt des Systems. Im Gegensatz zu klassischen Schichtenmodellen, bei denen Daten linear fließen, fungieren hier Ereignisse – von Benutzereingaben bis zu Geschäftsregeln – als primäre Auslöser, die von Knoten zu Knoten fließen. Diese Struktur macht EDA-Systeme hochgradig flexibel und skalierbar, da neue Ereignisse oder Änderungen integriert werden können, ohne die gesamte Architektur umbauen zu müssen.
Ein solches System basiert auf drei zentralen Säulen: Ereignis-Quellen (Generatoren wie Nutzer oder Sensoren), dem eigentlichen Ereignis (eine Tatsache, die auf Reaktion wartet) und der Ereignis-Verarbeitung (Transformation, Filterung oder Validierung der Daten).
Für die konkrete Umsetzung existieren spezialisierte Referenzarchitekturen:
-
Lambda-Architektur: Entwickelt für Big Data, teilt sie das System in drei Schichten: den Batch-Layer (für historische Datenmengen), den Speed-Layer (für Echtzeit-Analysen) und den Serving-Layer (für die Bereitstellung an Nutzer).
-
Kappa-Architektur: Eine Vereinfachung der Lambda-Architektur, die den Batch-Layer eliminiert. Sie setzt vollständig auf Streaming-Verarbeitung in Echtzeit (oft mittels Apache Kafka oder Flink).
-
Reactive Manifesto: Ein Leitfaden für moderne Systeme, die auf vier Prinzipien beruhen: Responsiveness (schnelle Antwortzeiten), Elastizität (Skalierbarkeit), Widerstandsfähigkeit (Resilience) und Nachrichtenorientierung.
-
CQRS (Command Query Responsibility Segregation): Trennt strikt die Verantwortlichkeiten für das Schreiben (Commands) und das Lesen (Queries) von Daten, was die Skalierbarkeit und Wartbarkeit massiv verbessert.
(9.2) Referenzarchitekturen für IoT
Das Internet der Dinge (IoT) basiert auf der Vernetzung intelligenter physischer Objekte, die über Sensoren und Aktoren Daten sammeln und auf ihre Umgebung reagieren. Um die enormen Datenmengen effizient zu nutzen, sind Cloud Computing und Big Data-Technologien zur Echtzeitanalyse essenziell. Ein kritischer Erfolgsfaktor ist dabei die Sicherheit, um die vernetzte Infrastruktur vor unbefugtem Zugriff zu schützen.
Für die Umsetzung existieren verschiedene Hersteller-Architekturen, die meist in Schichten organisiert sind:
- IBM: 4 Schichten (Geräte, Gateway, Cloud, Anwendungen).
- Microsoft: 3 Schichten (Geräte, Cloud, Anwendungen).
- Cisco: 4 Schichten (Geräte, Netzwerk, Datenverarbeitung, Anwendungen).
Darüber hinaus gibt es standardisierte und branchenspezifische Referenzmodelle:
- Industrial Internet Reference Architecture (IIRA): Vom Industrial Internet Consortium entwickelt; fokussiert auf Skalierbarkeit und Interoperabilität mit Komponenten wie Edge Devices und Gateways.
- Open Platform 3.0: Vom Open Group-Konsortium; legt den Schwerpunkt auf die Integration von IoT in Unternehmensprozesse und Big-Data-Analysen.
- Branchenspezifische Modelle: Diese adressieren Nischen wie Stromnetze (Smart Grid), vernetzte Fahrzeuge oder das Gesundheitswesen.
(9.3.) Peer-to-Peer Archiktekturen
Peer-to-Peer-Architekturen zeichnen sich durch ihren dezentralen Ansatz aus, bei dem Daten direkt zwischen gleichberechtigten Endpunkten (Peers) ausgetauscht werden, anstatt über einen zentralen Server zu laufen. Im Gegensatz zur klassischen Client-Server-Architektur fungiert hier jeder Knoten gleichzeitig als Client und Server.
Diese Struktur bietet drei zentrale Vorteile:
- Skalierbarkeit: Das Netzwerk wächst organisch mit jedem neuen Teilnehmer, da jeder neue Peer auch Rechenleistung oder Speicher bereitstellt.
- Verfügbarkeit & Robustheit: Da es keinen zentralen "Single Point of Failure" gibt, bleibt das System auch bei Ausfällen einzelner Knoten stabil und widerstandsfähig gegen Angriffe.
- Kosteneffizienz: Teure zentrale Server-Infrastrukturen entfallen weitgehend.
Bekannte Referenzarchitekturen sind Protokolle wie Gnutella oder BitTorrent sowie Netzwerke wie ehemals Skype. Die Anwendungsbereiche sind vielfältig und reichen von Filesharing und Instant Messaging bis hin zu verteiltem Cloud-Computing. Trotz dieser Stärken bringt die Entwicklung Herausforderungen mit sich, insbesondere im Bereich komplexer Routing-Algorithmen, der Netzwerksicherheit und der Handhabung unterschiedlicher Netzwerkbedingungen.