Verhaltensmuster
Bei Verhaltensmustern steht die Zusammenarbeit zwischen Klassen und Objekten im Vordergrund. Sie betrachten die Interaktion und das Verhalten der Objekte untereinander. Dabei wird auch berücksichtigt, welche Objekte welche Zuständigkeiten abbilden.
(2) Das Observer Pattern
Die Ausgangslage: Wie kommunizieren Objekte?
In der Softwareentwicklung tritt häufig das Problem auf, dass ein Objekt Änderungen erfährt (z.B. Nutzereingaben) und andere Objekte sofort darauf reagieren müssen. Hierbei lassen sich vier grundlegende Strategien unterscheiden, um diese Kommunikation zu organisieren.
-
Beim Push-Verfahren ruft das ändernde Objekt direkt die Methoden der abhängigen Objekte auf. Dies führt jedoch zu einer festen Kopplung, da der Code des Senders angepasst werden muss, sobald neue Empfänger hinzukommen.
-
Das Pull-Verfahren kehrt dieses Prinzip um, indem die abhängigen Objekte regelmäßig beim Sender nachfragen, ob es Neuigkeiten gibt. Dies ist oft ineffizient, da entweder unnötig oft gefragt wird oder Änderungen erst verzögert bemerkt werden.
-
Eine dritte Möglichkeit ist der Einsatz eines Nachrichtenbusses als zentrale Vermittlungsstelle, was zwar flexibel ist, aber eine zusätzliche Infrastruktur erfordert.
-
Das Observer Pattern stellt als vierte Option eine objektorientierte Umsetzung des Publish/Subscribe-Prinzips dar. Hierbei melden sich Interessenten einmalig an und werden anschließend vom Sender aktiv, aber anonym informiert, ohne dass eine feste Verdrahtung besteht.
Die Mechanik des Observer Patterns
Das Kernprinzip dieses Musters ist die lose Kopplung, die sicherstellt, dass die beteiligten Klassen so wenig wie möglich voneinander wissen müssen. Das Subjekt, oft auch Observable genannt, fungiert als Informationslieferant und verwaltet eine interne Liste von Interessenten. Entscheidend ist, dass in dieser Liste keine konkreten Klassennamen gespeichert werden, sondern lediglich Referenzen auf Schnittstellen. Das Subjekt bietet Methoden an, um Beobachter in diese Liste aufzunehmen oder daraus zu entfernen, und verfügt über eine Benachrichtigungsfunktion, die bei Änderungen alle Einträge der Liste durchläuft.
Der Beobachter oder Observer nimmt die Rolle des Informationskonsumenten ein. Er muss zwingend ein definiertes Interface implementieren, das eine Update-Methode vorschreibt. Dadurch garantiert er dem Subjekt, dass er benachrichtigt werden kann, ohne dass das Subjekt die konkrete Implementierung des Beobachters kennen muss.
Vorteile
Der Einsatz dieses Entwurfsmusters bietet wesentliche Vorteile für die Softwarearchitektur. An erster Stelle stehen Flexibilität und Erweiterbarkeit, da jederzeit neue Beobachter hinzugefügt werden können, ohne dass der Quellcode des Subjekts verändert werden muss. Das Subjekt operiert unabhängig davon, wer oder wie viele Zuhörer gerade existieren. Dies fördert auch die Wiederverwendbarkeit, da das Subjekt nicht an eine spezifische Benutzeroberfläche oder logische Weiterverarbeitung gebunden ist. Ein weiterer Pluspunkt ist die verbesserte Testbarkeit. Für Unit-Tests lassen sich problemlos einfache Dummy-Beobachter in das System einhängen, die lediglich prüfen, ob eine Benachrichtigung korrekt erfolgt ist.
Nachteile und Risiken
Trotz der genannten Vorteile birgt das Muster auch Risiken, die bei der Implementierung beachtet werden müssen.
Performance-Probleme können auftreten, wenn das Subjekt sehr häufig Änderungen meldet und dadurch jedes Mal alle Beobachter aktiviert werden. Oft sind Beobachter gar nicht an jeder kleinen Änderung interessiert und müssen diese intern filtern, was unnötige Rechenzeit kostet. Ein kritisches Risiko stellen zyklische Abhängigkeiten dar, die zu Endlosschleifen führen können. Dies passiert, wenn eine Benachrichtigung eine Aktion auslöst, die wiederum den Zustand des Subjekts ändert und eine erneute Benachrichtigung feuert.
Zudem ist die Reihenfolge, in der die Beobachter informiert werden, meist zufällig und nicht garantiert.
Ein weiteres Problem ist das sogenannte Lapsed Listener Problem, bei dem Beobachter vergessen, sich abzumelden. Da das Subjekt weiterhin eine Referenz auf sie hält, kann der Speicher nicht freigegeben werden, was zu Speicherlecks führt.
Umsetzung in der Praxis
Die Umsetzung variiert je nach Programmiersprache. In Java existierten historisch die Klasse java.util.Observable und das Interface java.util.Observer. Da Java jedoch keine Mehrfachvererbung unterstützt und Observable eine Klasse ist, schränkt dies die Nutzung stark ein, sobald eine Klasse bereits von einer anderen erbt. Daher wird das Pattern in Java meist manuell über Interfaces und Listen nachgebaut. In der .NET-Welt hingegen ist das Konzept durch Delegates und Events bereits fest in die Sprache integriert, was einer nativen Unterstützung des Observer Patterns entspricht und die manuelle Implementierung oft überflüssig macht.
Schritt-für-Schritt-Implementierung
Wenn man das Pattern selbst programmieren muss, kann man diesem Ablauf folgen:
- Interface definieren: Erstelle ein Interface (z. B.
IBeobachter) mit einer Methode aktualisiere(daten), die alle Beobachter haben müssen. - Liste anlegen: Erzeuge im Subjekt (dem Sender) eine Liste (z. B.
List<IBeobachter>), um die Interessenten zu speichern. - Verwaltungsmethoden: Implementiere im Subjekt Methoden, um Objekte in diese Liste aufzunehmen (add) oder zu entfernen (remove).
- Benachrichtigungsmethode: Schreibe eine Methode, die per Schleife durch die Liste geht und bei jedem Eintrag die
aktualisiere()-Methode aufruft. - Auslöser: Rufe immer dann, wenn sich im Subjekt etwas Wichtiges ändert (z. B. in einer Setter-Methode), die Benachrichtigungsmethode auf.
Praktische Implementierung
Interface
Damit wird bei der Erstellung von Abonnenten "gezwungen", die Methode zu implementieren.
interface Abonnent {
void benachrichtigungErhalten(String videoTitel);
}
Das Subjekt (Der Sender)
Es wird zunächst die Liste der Abonnenten als privates Attribut definiert. Diese sind nicht im Voraus bekannt bis auf die Tatsache, dass sie vom Typen (Interface) Abonnent sind. Es können mehrere Methoden zur Kommunikation mit den Observer implementiert werden.
Am wichtigsten ist die letzte Methode im unteren Beispiel, die mit einer Schleife die Liste aller Abonnenten (Observer) durchgeht und die im Interface definierte Methode benachrichtigungsErhalten() aufruft. Somit werden alle Observer informiert.
import java.util.ArrayList;
import java.util.List;
class YoutubeKanal {
private List<Abonnent> abonnentenListe = new ArrayList<>();
// Methode zum Anmelden
public void abonnieren(Abonnent a) {
abonnentenListe.add(a);
}
// Methode zum Abmelden
public void deabonnieren(Abonnent a) {
abonnentenListe.remove(a);
}
// DAS EREIGNIS: Ein neues Video wird hochgeladen
public void videoHochladen(String titel) {
System.out.println("KANAL: Lade neues Video hoch: " + titel);
notifyAbonnenten(titel);
}
// Die interne Methode, die alle informiert (die "Schleife")
private void notifyAbonnenten(String titel) {
for (Abonnent a : abonnentenListe) {
a.benachrichtigungErhalten(titel);
}
}
}
Der Empfänger (Observer)
class YoutubeUser implements Abonnent {
private String name;
public YoutubeUser(String name) {
this.name = name;
}
// Hier reagiert der User auf die Nachricht
@Override
public void benachrichtigungErhalten(String videoTitel) {
System.out.println(name + " sagt: Hurra! Ich schaue mir sofort '" + videoTitel + "' an.");
}
}
(3) Das Mediator Pattern
Das Mediator Pattern (Vermittler-Muster) kommt dort zum Einsatz, wo das klassische Observer Pattern an seine Grenzen stößt. Dies ist insbesondere der Fall, wenn Beobachter selbst wiederum als Nachrichtenquellen fungieren oder sich die Menge der zu beobachtenden Objekte dynamisch verändert, wie beispielsweise beim Starten und Stoppen von Threads. Das Muster löst dieses Problem durch eine strikte Entkopplung von Informationsquelle (Producer) und Empfänger (Consumer), indem es eine zentrale Vermittlungsinstanz dazwischenschaltet.
Der Mediator verwaltet dabei die Registrierung von Erzeugern und Konsumenten. Dadurch entsteht eine sehr lose Kopplung: Ein Informationslieferant muss nicht wissen, wer ihm zuhört, und der Konsument fordert Informationen oft nur anhand des Typs und nicht bei einer spezifischen Quell-Klasse an. Diese Architektur ähnelt stark einem Nachrichtenbus.
Ein klassisches Anwendungsbeispiel aus der Praxis ist die Enterprise Application Integration (EAI), etwa bei Systemen wie SAP PI. Hier fungiert die Middleware als Mediator, um Daten zwischen unabhängigen Systemen (z. B. ERP und CRM) zu synchronisieren. Wenn sich eine Kundenadresse im ERP ändert, leitet der Mediator diese Info an das CRM weiter, ohne dass die Systeme direkt miteinander kommunizieren müssen. Dies zeigt auch, dass Komponenten oft gleichzeitig Sender und Empfänger sein können.
In der technischen Umsetzung registriert sich ein neuer Producer beim Mediator, um Nachrichten versenden zu können. Die Umsetzung variiert je nach Anforderung: Es gibt einfache Varianten mit getrennten Rollen für Sender und Empfänger, sowie komplexere Ansätze für Netzwerke, in denen jedes Objekt gleichzeitig Sender und Empfänger ist ("ConProd"). Bei letzterem muss die Implementierung sicherstellen, dass ein Sender seine eigene Nachricht nicht als Echo zurückerhält. Der entscheidende Vorteil dieses Musters liegt in der zentralen Koordination, die eine hohe Skalierbarkeit und Flexibilität der Softwarearchitektur gewährleistet.
(4) Das Chain of Responsibility Pattern
Das Chain of Responsibility Pattern, auch bekannt als „Zuständigkeitskette“, verfolgt einen anderen Ansatz als der Mediator oder Observer. Anstatt alle potenziellen Empfänger gleichzeitig oder über eine Zentrale zu informieren, wird eine Nachricht oder Aufgabe hier sequenziell von einem Objekt zum nächsten weitergereicht.
Das Kernprinzip gleicht einer Eimerkette oder einem klassischen bürokratischen Dienstweg: Ein Objekt prüft, ob es für die Anfrage zuständig ist. Wenn ja, kann es die Nachricht verarbeiten und den Vorgang beenden – die nachfolgenden Objekte werden dann nicht mehr belästigt. Wenn nein (oder wenn nur eine Teilverarbeitung stattfindet), reicht es die Aufgabe an den nächsten Verarbeiter in der Kette weiter. Ein kritisches Szenario entsteht, wenn kein einziges Glied der Kette reagiert; daher sollte am Ende oft ein "Default Handler" stehen, der übrig gebliebene Anfragen auffängt.
Die Reihenfolge innerhalb der Kette ist dabei entscheidend und kann strategisch genutzt werden. Stehen wichtige oder spezialisierte Verarbeiter am Anfang, entspricht dies einer Priorisierung. Es ist aber auch möglich, die Kette als "Pipeline" zu nutzen, bei der jedes Objekt die Daten ein wenig anreichert oder modifiziert, bevor es sie weitergibt, um so komplexe lineare Prozesse abzubilden.
Technisch gibt es zwei Varianten der Verwaltung:
- Externe Verwaltung: Eine eigene Klasse steuert den Durchlauf durch die Liste der Handler. Das ist sehr flexibel, aber komplexer.
- Verkettete Liste (Selbstverwaltung): Dies ist der klassische Ansatz (siehe Abbildung). Jeder Handler kennt nur seinen direkten Nachfolger (next). Die Kette entsteht dynamisch, indem man beim ersten Objekt das zweite als Nachfolger setzt (setNext), beim zweiten das dritte und so weiter.
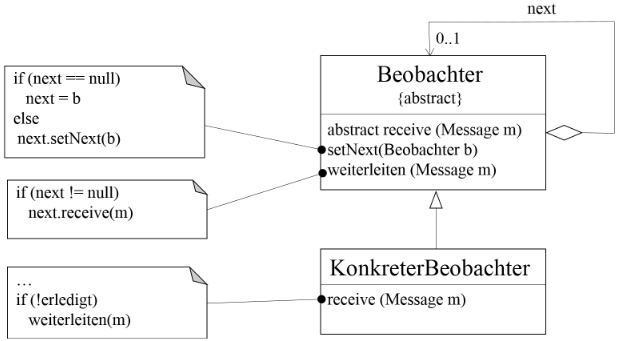
Für die Implementierung bedeutet dies konkret: Man erstellt verschiedene Handler-Klassen, die alle auf die gleiche receive()-Methode reagieren. Innerhalb dieser Methode wird entschieden: "Kann ich das lösen?". Wenn nicht, wird die weiterleiten()-Methode aufgerufen, die die Anfrage an das next-Objekt übergibt. Der Vorteil liegt in der Entkopplung: Der Absender der Nachricht muss nicht wissen, wer genau die Anfrage bearbeitet – er wirft sie einfach oben in die Kette ein, und das System sucht sich selbstständig den richtigen Verarbeiter.
(5) Das State Pattern
Wenn das Verhalten eines Objekts stark von seinem aktuellen Zustand abhängt, führen herkömmliche Implementierungen oft zu komplexen und unübersichtlichen Konstrukten aus zahlreichen Fallunterscheidungen. Diese sind schwer zu warten und fehleranfällig bei Erweiterungen. Das State Pattern löst dieses Problem, indem es die Zustände nicht als bloße Werte (wie Integers), sondern als eigenständige Objekte kapselt. Dies erhöht durch die Nutzung von Aufzählungstypen (Enums) zudem die Typsicherheit.
Das Kernprinzip besteht darin, eine abstrakte Oberklasse zu definieren, die Methoden für alle theoretisch möglichen Zustandsübergänge bereitstellt. In der Standardimplementierung werfen diese Methoden eine Fehlermeldung, um ungültige Übergänge abzufangen, etwa das direkte Abschließen einer noch offenen Tür. Die konkreten Zustände werden als Unterklassen realisiert, die nur jene Übergangsmethoden überschreiben, die für sie tatsächlich zulässig sind. Das eigentliche Objekt (der Kontext) hält eine Referenz auf sein aktuelles Zustandsobjekt und delegiert Anfragen an dieses weiter. Um den Zustand zu wechseln, benötigt das Zustandsobjekt oft einen Rückverweis auf den Kontext oder liefert den neuen Zustand als Rückgabewert.
Der wesentliche Vorteil dieses Musters liegt in der sauberen Trennung der Zustandslogik. Ungültige Übergänge werden strukturell verhindert, und neue Zustände lassen sich durch neue Klassen einfach ergänzen, ohne den bestehenden Code massiv verändern zu müssen. Demgegenüber steht als Nachteil die deutlich steigende Anzahl an Klassen. Daher empfiehlt sich der Einsatz des State Patterns erst, wenn die Zustandslogik eine gewisse Komplexität erreicht hat, da der Overhead bei trivialen Problemen sonst den Nutzen übersteigt.