(2) NoSQL-Datenbanken
(1.) Einführung
NoSQL zu verstehen, bedeutet nicht nur, die Technik zu beherrschen, sondern auch die Geschichte und die Philosophie von NoSQL zu kennen. Wenden wir uns daher zuerst der Geschichte von NoSQL zu.
(1.1.) Historie
Die Entwicklung von NoSQL-Systemen verlief parallel zum Aufstieg relationaler Datenbanken und reicht bis ins Jahr 1979 zurück, als Ken Thompson die Key/Hash-Datenbank DBM entwickelte. In den 80er Jahren folgten etablierte Vorreiter wie Lotus Notes, BerkeleyDB und GT.M, die bereits früh Alternativen zum relationalen Standard boten. Der Begriff selbst tauchte erstmals 1998 bei Carlo Strozzi auf, bezeichnete damals jedoch lediglich eine relationale Datenbank ohne SQL-Schnittstelle.
Der entscheidende technologische Schub erfolgte ab dem Jahr 2000 durch das Web 2.0 und die Notwendigkeit, riesige Datenmengen zu verarbeiten. Hierbei gilt Google mit Technologien wie Map/Reduce und BigTable als zentraler Wegbereiter, gefolgt von Internetriesen wie Amazon und Facebook. Parallel dazu entstanden bis 2005 spezialisierte Lösungen wie Neo4j oder memcached, die bereits starken NoSQL-Charakter aufwiesen.
Die heute bekannten klassischen Vertreter - darunter HBase, Cassandra, MongoDB und Redis - etablierten sich massiv zwischen 2006 und 2009. Die formale Benennung der Bewegung erfolgte schließlich im Mai 2009, als Eric Evans den Begriff „NoSQL“ im Kontext eines Meetups für verteilte Datenspeicher neu definierte. Seitdem steht der Begriff für eine starke Gegenbewegung zum langjährigen Monopol relationaler Systeme.
(1.2.) Definition
Die Definition des Begriffs NoSQL fällt schwer, da es keine offiziellen Gremien gibt und der Begriff in der Praxis für unterschiedliche Ansätze verwendet wird. Allgemein lässt sich NoSQL als eine neue Generation von Datenbanksystemen verstehen, die primär für die enormen Datenmengen des Web 2.0 entwickelt wurden („Web-Scale“).
Die wesentlichen Merkmale einer NoSQL-Datenbank umfassen meist folgende Punkte:
- Nicht-relationales Datenmodell: Daten werden nicht in starre Tabellen gepresst (z.B. Graphen oder Dokumente).
- Verteilte Skalierbarkeit (Scale-out): Die Systeme sind darauf ausgelegt, durch das Hinzufügen weiterer Standard-Server (Nodes) horizontal zu wachsen, anstatt einzelne Server aufzurüsten (Scale-up).
- Open Source: Viele, wenn auch nicht alle, Systeme sind quelloffen, oft als Gegenbewegung zu teuren Lizenzmodellen.
- Schemafreiheit: Schwächere Schemarestriktionen ermöglichen eine höhere Agilität in der Entwicklung, da Änderungen (z.B. neue Datenfelder) den Betrieb nicht blockieren.
- Einfache Replikation: Die Verteilung und Synchronisation von Daten auf mehrere Server ist oft inhärenter Bestandteil des Designs.
- Einfache API: Anstelle von komplexem SQL werden oft einfachere Schnittstellen (z.B. REST) genutzt, auch wenn dies komplexe Abfragen erschweren kann.
- Alternatives Konsistenzmodell (BASE statt ACID): Zugunsten der Verfügbarkeit wird oft auf strikte sofortige Konsistenz verzichtet (Eventually Consistent), was für viele Web-Anwendungen (z.B. Social Media) völlig ausreicht.
Der Begriff selbst ist umstritten und entstand eher als Marketing-Schlagwort denn als technische Beschreibung. Kritiker schlugen Alternativen wie „NoREL“ vor, da „NoSQL“ suggeriert, es gäbe gar keine Abfragesprache. Inzwischen hat sich die Interpretation „Not Only SQL“ durchgesetzt, um zu verdeutlichen, dass diese Systeme relationale Datenbanken nicht zwingend ersetzen, sondern in spezifischen Anwendungsfällen sinnvoll ergänzen.
(1.3.) Kategorisierung von NoSQL-Systemen
Die enorme Marktmacht relationaler Systeme hat dazu geführt, dass sich inzwischen über 100 verschiedene nicht-relationale Datenbanken unter dem Sammelbegriff NoSQL vereinen. Um diese Vielfalt zu strukturieren, wird eine Unterscheidung in NoSQL-Kernsysteme und nachgelagerte Systeme (oder soft-NoSQL) vorgenommen. Zu den Kernsystemen zählen Wide Column Stores, Document Stores, Key/Value-Stores sowie Graphdatenbanken. Diese Gruppe repräsentiert die „echten“ NoSQL-Systeme, die spezifisch als Antwort auf die massiven Skalierungs- und Schema-Anforderungen des Web 2.0 entwickelt wurden.
Die Gruppe der nachgelagerten oder „Soft-NoSQL“-Systeme umfasst hingegen Technologien, die zwar nicht-relationale Ansätze verfolgen, aber historisch oder konzeptionell eine andere Herkunft haben. Hierzu gehören beispielsweise Objekt- und XML-Datenbanken, die bereits seit den 90er Jahren als Alternativen existieren, sowie diverse Grid-Lösungen. Obwohl die Grenzen zwischen diesen Kategorien oft fließend sind und jeder Anwender sie anders zieht, konzentriert sich die fachliche Auseinandersetzung primär auf die vier Hauptkategorien der Kernsysteme.
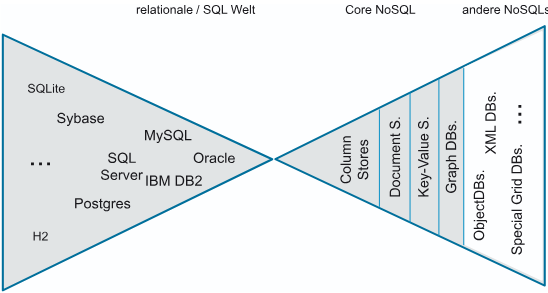
Die Unterscheidung erfolgt primär aufgrund der historischen Herkunft und des Entwicklungsziels:
-
NoSQL-Kernsysteme: Entstanden direkt aus der Notwendigkeit der Internet-Giganten (Google, Amazon), massive Datenmengen im Web 2.0 zu verarbeiten. Ihr primärer Fokus liegt auf horizontaler Skalierbarkeit (Scale-out) auf günstiger Hardware und Schema-Flexibilität. Sie sind die "neue Welle".
-
Soft-NoSQL / Nachgelagerte Systeme: Umfassen nicht-relationale Systeme, die oft schon vor der NoSQL-Welle existierten (z.B. Objektdatenbanken der 90er) oder für spezialisierte Nischen entwickelt wurden (XML-Datenbanken). Sie passen zwar in die Definition "Not Only SQL", waren aber ursprünglich nicht Teil der Web-2.0-Bewegung zur Lösung von Big-Data-Problemen.
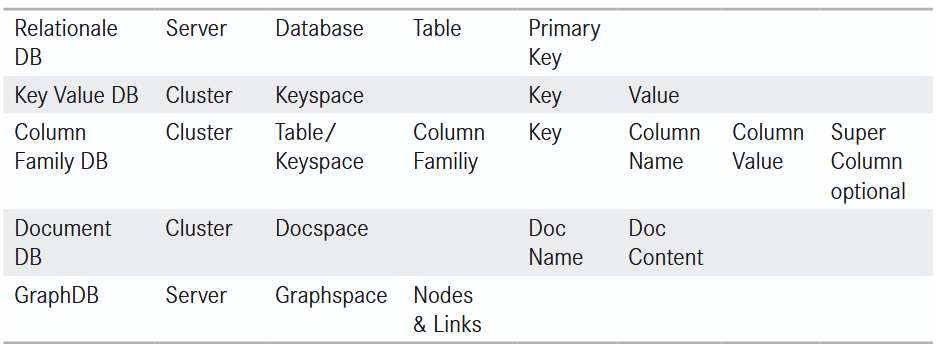
(1.3.1.) Key/Value Systeme
Key/Value-Systeme repräsentieren das fundamentalste Datenmodell im NoSQL-Bereich, basierend auf einer simplen Zuordnung von Schlüsseln zu Werten. Die Werte sind dabei oft nicht nur einfache Strings, sondern können komplexe Strukturen wie Listen, Sets oder Hashes annehmen, was die Funktionalität teilweise in die Nähe von Column-Family-Systemen rückt.
Der entscheidende Vorteil dieses minimalistischen Designs liegt in der hohen Performance und der effizienten Datenverwaltung. Dieser Geschwindigkeitsvorteil geht jedoch oft zu Lasten der Flexibilität: Da komplexe Abfragesprachen meist fehlen, ist die Datenmanipulation stark von der Mächtigkeit der bereitgestellten API abhängig. Zu den bekanntesten Vertretern zählen Redis, Voldemort (früher LinkedIn, seit 2018 nicht mehr aktualisiert) sowie die Amazon-Dienste Dynamo und S3.
(1.3.2) Column-Family-Systeme
Diese Systeme, zu denen HBase, Cassandra und Hypertable gehören, erinnern auf den ersten Blick an klassische Excel-Tabellen, bieten jedoch eine wesentlich höhere Flexibilität. Das Modell erlaubt es, einem Zeilenschlüssel eine beliebige Anzahl von Spalten (Key/Value-Paaren) zuzuordnen, die zur Laufzeit dynamisch erweitert werden können – die sogenannte Column Family.
Durch zusätzliche Strukturierungsmöglichkeiten wie Super-Columns (verschachtelte Listen) oder Keyspaces entsteht eine mächtige Architektur. Diese fungiert faktisch als Hybrid zwischen einfachen Key/Value-Stores und komplexeren spaltenorientierten oder relationalen Datenbanken und eignet sich hervorragend für riesige, aber strukturierte Datenbestände.
(1.3.3) Document Stores
Der Begriff Document Store (für dokumentorientierte Datenbanken) ist historisch irreführend, da er ursprünglich aus dem Umfeld von Lotus Notes stammt, wo tatsächlich Anwenderdateien verwaltet wurden. Im Kontext moderner NoSQL-Systeme bezieht sich der Begriff jedoch nicht auf Textdokumente, sondern auf strukturierte Datensammlungen in Formaten wie JSON, YAML oder RDF - diese müssen nicht einem physikalischen Dokument entsprechen. Diese „Dokumente“ werden meist unter einer eindeutigen ID abgelegt, wobei die Datenbank in der Regel nur das Format validiert, ohne tiefgreifende Schemata zu erzwingen.
Ein Beispiel kann eine Rechnung sein, die Informationen über den Empfänger, den Ersteller, das Datum und die zu bezahlenden Produkte und Dienstleistungen enthält. Insgesamt wird meist die gesamte Rechnung und nicht Teile davon betrachtet, sodass ein relationales System dazu immer mehrere Tabellen bearbeiten müsste. Dadurch, dass Rechnungen typischerweise eindeutig durch ihre Rechnungsnummer identifizierbar sind, liefert eine dokumentenorientierten Datenbank unmittelbar das zur Rechnungsnummer gehörende gesamte Dokument.
Dokumentenorientierte Datenbanken sind typischerweise schemafrei. Anders als bei relationalen Tabellen gibt es keine starre Struktur, die alle Datensätze einhalten müssen, weshalb auch Normalformen keine Rolle spielen. Dies bietet den entscheidenden Vorteil, dass neue Informationen dynamisch in einzelnen Dokumenten ergänzt werden können, ohne den gesamten Datenbestand anpassen zu müssen. Im Gegensatz dazu erfordern relationale Datenbanken bei Erweiterungen oft Strukturänderungen (neue Spalten mit vielen NULL-Werten) oder zusätzliche Tabellen.
Zu den wichtigsten Vertretern dieser Kategorie zählen CouchDB und Riak, die auf das JSON-Format setzen, sowie MongoDB, das die binäre Variante BSON verwendet. Ein valides Dokument kann dabei von einer simplen Textdatei bis hin zu komplexen Objektstrukturen mit verschiedenen Datentypen reichen.
BSON Beispiel:
SurName="Doe"
FirstName="John"
Age="42"
(1.3.4) Graphdatenbanken
Graphdatenbanken stellen die Verknüpfung zwischen den gespeicherten Objekten in den Mittelpunkt und sind optimiert für die Nutzung gängiger Graph-Algorithmen. Graphen bestehen aus Knoten und Kanten. Obwohl die Graphentheorie etabliert ist, gewannen diese Datenbanken erst durch das Semantic Web und insbesondere durch Location Based Services (LBS) auf Smartphones ab 2008 massiv an Bedeutung. Ein zentrales Einsatzgebiet ist die Verknüpfung von sozialen Beziehungen mit Geodaten („Wer sind meine Freunde in der Nähe?“) sowie komplexe Pfadsuche-Algorithmen.
Meist kommen hier native Property-Graphen zum Einsatz, bei denen Knoten und Verbindungen mit Eigenschaften gewichtet werden können (z.B. „Alice kennt Bob seit 3 Jahren“). Ihr entscheidender Vorteil gegenüber relationalen Systemen liegt in der enormen Geschwindigkeit beim Traversieren komplexer Beziehungen, die in SQL aufwendige Join-Operationen erfordern würden. Bekannte Vertreter sind Neo4j und SonesDB.
(1.3.5) Objektorientierte Datenkbanken
Objektorientierte Datenbanken richten ihre Speicher- und Abfragestruktur direkt an Objekten und deren Sammlungen aus, was den Zugriff erleichtert. In der Praxis hat sich dieser reine Ansatz jedoch kaum durchgesetzt; stattdessen dominieren heute Objekt-Relationale Mapper (ORM), die eine Zwischenschicht zu anderen Datenbanktypen bilden.
(1.3.6) Spaltenorientierte Datenbanken
Diese unterscheiden sich technisch grundlegend durch ihre Speicherart. Während klassische Datenbanken Daten zeilenweise ablegen (gut für das Editieren ganzer Datensätze), speichern diese Systeme Daten spaltenweise. Da der Datentyp einer Spalte homogen ist, lässt sich Speicherplatz effizient sparen (Kompression). Besonders effizient sind sie bei Analysen über einzelne Spalten (z.B. Durchschnittsberechnungen). Da sie oft SQL unterstützen und komplexe, verschachtelte Strukturen in Spalten erlauben, ist ihre Einordnung als „reines“ NoSQL teilweise fließend.
(1.3.8) Weitere Unterscheidungsmerkmale
Neben den vier Hauptkategorien lassen sich NoSQL-Systeme auch anhand ihrer Architektur und Speicherstrategie klassifizieren. Ein wesentliches Merkmal ist die Verteilung: Während Systeme wie HBase, MongoDB oder Cassandra nativ auf verteilte Umgebungen und Skalierung ausgelegt sind, arbeiten andere Lösungen wie Redis oder die Tokyo-Familie oft nicht sichtbar verteilt für den Anwender. Zudem unterscheidet man zwischen Disk-basierten Systemen (z.B. CouchDB, Riak), die auf dauerhafte Festplattenspeicherung setzen, und RAM-basierten oder hybriden Ansätzen (z.B. Redis, Cassandra), bei denen die Datenhaltung im Arbeitsspeicher konfigurierbar ist.
(2.) NoSQL - Theoretische Grundlagen
Der erfolgreiche Einsatz von NoSQL-Datenbanken setzt ein fundiertes Verständnis der zugrundeliegenden Konzepte und Algorithmen voraus. Während einige dieser Verfahren bereits aus der klassischen Datenbankwelt bekannt sind, nutzt die NoSQL-Welt spezifische Protokolle und Ansätze, die für verteilte Systeme essenziell sind und in relationalen Umgebungen seltener anzutreffen waren.
Dieses theoretische Fundament bildet die Basis für fast alle NoSQL-Architekturen. Zu den zentralen Bausteinen gehören dabei Verarbeitungsmodelle wie Map/Reduce, Verteilungsstrategien wie Consistent Hashing und Paxos sowie Konzepte zur Konsistenz und Kommunikation wie das CAP-Theorem, Eventual Consistency, MVCC, Vector Clocks und REST.
(2.1.) Map/Reduce
Map/Reduce ist ein spezialisiertes Framework und Verfahren, das entwickelt wurde, um die effiziente Verarbeitung massiver Datenmengen im Tera- und Petabyte-Bereich zu ermöglichen. Kern des Ansatzes ist die Verteilung von Rechenaufgaben auf Computercluster, wodurch eine performante, nebenläufige Berechnung realisiert wird.
Das Konzept wurde ursprünglich im Jahr 2004 von den Google-Entwicklern Jeffrey Dean und Sanjay Ghemawat entworfen und auf der OSDI-Konferenz vorgestellt. Zwar erhielt Google im Jahr 2010 ein US-Patent auf das Verfahren.
(2.1.1.) Funktionale Ursprünge
Das theoretische Fundament moderner Map/Reduce-Frameworks liegt in der funktionalen Programmierung (z.B. Haskell, LISP). Diese Sprachen eignen sich ideal für die Parallelisierung, da ihre Funktionen keine Seiteneffekte erzeugen (wie Deadlocks oder Race Conditions) und Daten niemals „in-place“ verändern. Stattdessen arbeiten sie stets auf Kopien, was bedeutet, dass die Ausführungsreihenfolge von Operationen technisch irrelevant ist und Prozesse problemlos auf verteilte Cluster-Knoten ausgelagert werden können.
Die namensgebenden Kernfunktionen arbeiten dabei wie folgt:
- Map (Abbilden): Diese Funktion realisiert eine n-zu-n-Transformation. Sie ist polymorph und akzeptiert als Argumente eine weitere Funktion
fsowie eine Liste. Die Logik wendet die Funktionfrekursiv auf jedes einzelne Element der Eingabeliste an und erzeugt eine neue Liste identischer Länge mit den transformierten Werten. Die Reihenfolge der Elemente bleibt dabei erhalten.
Beispiel: Eine Map-Funktion, die x^2 auf die Liste [1, 2, 3] anwendet, liefert [1, 4, 9] zurück. Ebenso können Operationen auf Strings (z.B. toUpper) elementweise durchgeführt werden.
- Reduce / Fold: Diese Funktion führt eine n-zu-1-Transformation (Aggregation) durch. Sie „faltet“ eine Liste unter Verwendung einer Schrittfunktion und eines Startwertes (Akkumulator) zu einem einzelnen Ergebniswert zusammen. In Sprachen wie Haskell wird dabei zwischen der Abarbeitungsrichtung unterschieden: foldl (von links nach rechts) und foldr (von rechts nach links).
Beispiel: Eine Reduce-Funktion mit dem Operator + und dem Startwert 0 summiert die Liste [1, 2, 3] schrittweise auf (((0+1)+2)+3), bis das Endergebnis 6 steht.
Obwohl diese mathematisch strikten Definitionen in modernen Big-Data-Frameworks (wie bei Google) modifiziert wurden, bleibt das Grundprinzip identisch: Die Zerlegung komplexer Aufgaben in eine verteilbare Mapping-Phase und eine aggregierende Reducing-Phase.
(2.1.2.) Datenfluss und Phase des Map/Reduce-Verfahrens
Der Ablauf eines Map/Reduce-Verfahrens folgt einem strikten Datenflussmodell, das sich in zwei Hauptphasen unterteilt. Zunächst werden die Eingabedaten aufgeteilt und in der Map-Phase parallel von verschiedenen Prozessen verarbeitet. Die dabei entstehenden Zwischenergebnisse werden gepuffert. Erst wenn alle Map-Prozesse abgeschlossen sind, beginnt die Reduce-Phase, in der die zwischengespeicherten Daten aggregiert, weiterverarbeitet und schließlich als finale Ergebnisdateien im System abgelegt werden.
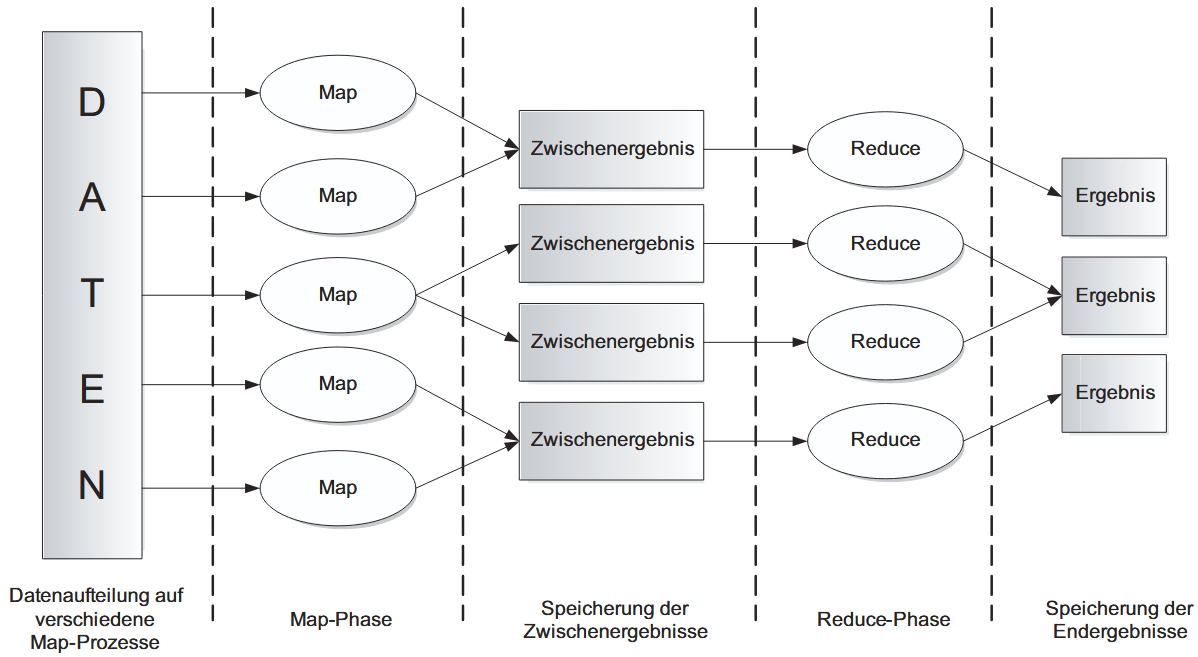
Eine zentrale Stärke dieses Ansatzes ist die strikte Trennung von Anwendungslogik und technischer Ausführung. Der Entwickler muss lediglich die beiden namensgebenden Funktionen definieren: Die map-Funktion transformiert ein Eingabepaar (key/value) in eine Liste von Zwischenergebnissen (out_key/intermediate_value), während die reduce-Funktion diese Zwischenwerte für einen bestimmten Schlüssel zu einem Endergebnis zusammenfasst.
Die gesamte komplexe Verwaltung im Hintergrund übernimmt das Framework (wie z.B. Hadoop). Es kümmert sich automatisch um die Parallelisierung der Prozesse, das I/O-Scheduling sowie die Fehlertoleranz, indem es beispielsweise Aufgaben von ausgefallenen Hardware-Knoten neu verteilt. Das klassische Beispiel zur Veranschaulichung dieses Prinzips ist die Zählung von Worthäufigkeiten (Word Count): Die Map-Funktion emittiert für jedes gefundene Wort den Wert „1“, und die Reduce-Funktion summiert diese Werte anschließend pro Wort auf, um die Gesamtzahl zu ermitteln.
Exkurs: OLTP vs. OLAP in NoSQL
Für das Verständnis der Architektur von NoSQL-Systemen ist die Unterscheidung zwischen zwei grundlegenden Verarbeitungsmustern essenziell.
OLTP (Online Transaction Processing) bezeichnet das operative Tagesgeschäft. Hierbei handelt es sich um viele kurze, atomare Transaktionen, wie das Speichern eines neuen Nutzers oder das Abrufen eines Warenkorbs anhand einer ID. Das Ziel ist eine Antwortzeit im Millisekundenbereich. In NoSQL-Systemen (z.B. DynamoDB, Redis) wird dies nicht durch Map/Reduce gelöst, sondern durch Mechanismen wie Consistent Hashing. Der Client greift hierbei direkt und gezielt auf den spezifischen Server zu, der die Daten hält.
OLAP (Online Analytical Processing) hingegen fokussiert sich auf die Analyse historischer oder aggregierter Datenmengen, um Muster oder Geschäftszahlen zu ermitteln (z.B. „Umsatz aller Filialen im letzten Jahr“). Da hierbei oft der gesamte Datenbestand durchsucht werden muss, ist der direkte Zugriff ineffizient. Genau hier kommt das Map/Reduce-Verfahren zum Einsatz: Es bringt die Rechenlogik zu den Daten, um die massive Last parallel auf den Speicherknoten zu verarbeiten, anstatt Terabytes an Daten durch das Netzwerk zu schleusen.
(2.1.3) Komponenten und Architektur
Die Implementierung eines Map/Reduce-Frameworks hängt stark vom Einsatzzweck ab (z.B. Shared Memory vs. verteilte Netzwerke). Googles Referenzarchitektur ist spezifisch für die Verarbeitung im Petabyte-Bereich auf Clustern aus tausenden günstigen Standard-PCs (Commodity Hardware) optimiert.
Ein fundamentaler Baustein hierfür ist das spezialisierte Dateisystem (Google File System GFS oder HDFS bei Hadoop). Da der Datendurchsatz hier wichtiger ist als niedrige Latenzzeiten, weist es besondere Eigenschaften auf:
- Dateien werden in sehr große Blöcke (Chunks, typisch 64 MB) unterteilt.
- Daten liegen redundant vor (mindestens 3-fach), um Ausfälle zu kompensieren.
- Optimierung auf Streaming-Zugriffe („Write once, read many“).
Der Prozessablauf (Datenfluss) Der Ablauf wird zentral von einem Master-Prozess gesteuert, der Aufgaben an viele Worker verteilt:
- Initialisierung: Die Eingabedaten werden in Blöcke (M mit einer Größe von 16–64 MB) zerlegt.
- Zuweisung: Der Master weist den Workern Map- oder Reduce-Aufgaben zu.
- Map-Phase: Worker lesen ihren Datenblock, führen die Map-Funktion aus und puffern Zwischenergebnisse im Speicher.
- Partitionierung: Die gepufferten Daten werden auf die lokale Festplatte geschrieben und für die Reduce-Phase partitioniert.
- Shuffle & Sort: Reduce-Worker holen sich die Daten (via RPC) von den Map-Workern und sortieren sie, sodass gleiche Schlüssel gruppiert sind.
- Reduce-Phase: Die sortierten Daten werden aggregiert und das Endergebnis ins Dateisystem geschrieben.
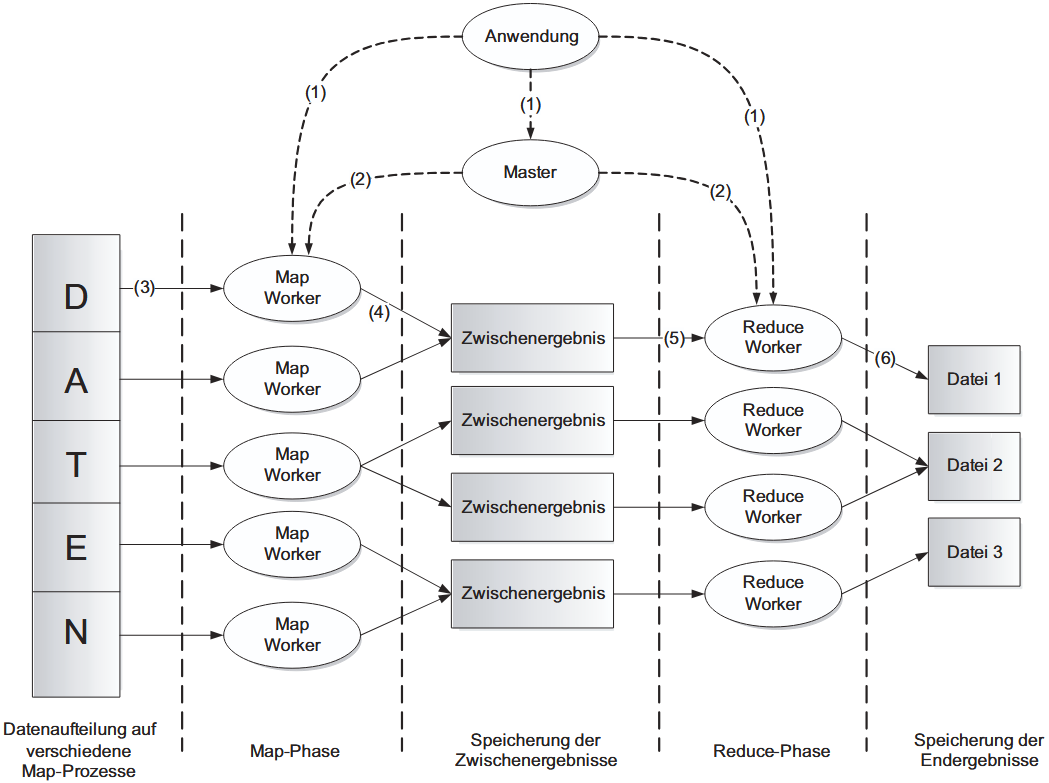
Wesentliche Software-Komponenten Neben der Map/Reduce-Bibliothek selbst besteht die Architektur aus:
- Master: Verwaltet Worker, überwacht den Status und verteilt Aufgaben.
- Partitionierungsfunktion: Teilt Zwischenergebnisse für die Verteilung auf.
- Sortierfunktion: Gruppiert Daten vor dem Reduce-Schritt.
- Combiner (Optional): Eine Art „lokaler Reduce“ direkt nach dem Map-Schritt, um die Netzwerklast zu verringern (fasst identische Ergebnisse vor der Übertragung zusammen).
(2.1.4.) Anwendungen und Implementierungen
Das Map/Reduce-Verfahren ist universell für Aufgaben einsetzbar, die rechenintensive Operationen auf massiven Datenmengen in einem Rechnerverbund erfordern. Zu den klassischen Einsatzszenarien gehören:
- Verteiltes Suchen (Grep): Filtern von Zeilen nach Mustern über riesige Datenbestände.
- Zugriffsstatistiken: Zählen von URL-Aufrufen (ähnlich dem Word-Count-Beispiel).
- Graphen-Erstellung: Analyse der Verlinkungsstruktur des Webs (Wer linkt auf wen?).
- Indexierung: Erstellung invertierter Wortindizes, wie sie für Suchmaschinen essenziell sind.
Aufgrund der Effizienz des Verfahrens entstanden nach der Veröffentlichung von Google zahlreiche Implementierungen für unterschiedlichste Umgebungen. Neben dem proprietären Google-Framework (C++) ist Apache Hadoop (Java) der bekannteste Open-Source-Vertreter. Die Bandbreite reicht jedoch weiter: von spezialisierten Lösungen für GPUs und Shared-Memory-Systeme über Implementierungen in diversen Programmiersprachen (Python, C#, Erlang, Go) bis hin zu Cloud-Diensten wie Amazon Elastic MapReduce. Zudem nutzen viele NoSQL-Datenbanken wie CouchDB (für Views) oder MongoDB Map/Reduce direkt als integriertes Werkzeug zur Datenverarbeitung.
(2.1.5) Praktisches Beispiel: Word Count
Um die Funktionsweise von Map/Reduce greifbar zu machen, wird in der Literatur standardmäßig die Worthäufigkeitsanalyse (Word Count) herangezogen. Die Aufgabe besteht darin, in einer großen Menge von unstrukturierten Textdokumenten zu zählen, wie oft jedes Wort vorkommt.
Dieses Beispiel eignet sich hervorragend, da es die strikte Trennung der beiden Phasen und die „Teile-und-Herrsche“-Strategie (Divide and Conquer) verdeutlicht.
1. Die Ausgangslage (Input)
Nehmen wir an, wir haben eine riesige Textdatei (oder viele kleine), die auf mehrere Server verteilt ist. Unser Input besteht aus drei Sätzen:
- "Hallo Welt"
- "Hallo NoSQL"
- "NoSQL ist toll"
2. Die Map-Phase
Das Framework weist jedem Datensatz (hier: einer Textzeile) einen Map-Worker zu. Die Aufgabe der Map-Funktion ist simpel: Sie liest den Text, zerlegt ihn in Wörter und emittiert für jedes gefundene Wort ein neues Key/Value-Paar. Der Schlüssel ist das Wort, der Wert ist einfach die Zahl 1 (als Zähler).
Pseudo-Code (Map):
def map(document_id, text):
# Zerlege den Text bei Leerzeichen in eine Liste von Wörtern
woerter = text.split()
for wort in woerter:
# Sende für jedes Wort ein Paar: (Wort, 1)
emit_intermediate(wort, 1)
Ergebnis der Map-Phase (Zwischenergebnis):
("Hallo", 1)
("Welt", 1)
("Hallo", 1)
("NoSQL", 1)
("NoSQL", 1)
("ist", 1)
("toll", 1)
3. Shuffle & Sort (Vom Framework übernommen)
Bevor der Reduce-Schritt beginnt, führt das Framework im Hintergrund eine Shuffle-Phase durch. Es sammelt alle Ausgaben der Map-Phase ein, sortiert sie und gruppiert alle Werte, die zum selben Schlüssel gehören, in einer Liste.
Datenstruktur nach Shuffle:
"Hallo" -> [1, 1]
"Welt" -> [1]
"NoSQL" -> [1, 1]
"ist" -> [1]
"toll" -> [1]
4. Die Reduce-Phase
Nun übergibt das Framework jeden dieser Schlüssel mit seiner dazugehörigen Liste an einen Reduce-Worker. Die Reduce-Funktion muss nun nur noch über die Liste iterieren und die Einsen aufsummieren, um die Gesamtzahl zu erhalten.
Pseudo-Code (Reduce):
def reduce(wort, liste_der_counts):
summe = 0
# Iteriere über die Liste [1, 1, ...] und addiere
for count in liste_der_counts:
summe += count
# Sende das finale Ergebnis
emit(wort, summe)
5. Das Endergebnis
Die Reduce-Worker schreiben ihre Ergebnisse in das Dateisystem. Das Resultat ist eine aggregierte Liste der Worthäufigkeiten über den gesamten Datenbestand:
("Hallo", 2)
("Welt", 1)
("NoSQL", 2)
("ist", 1)
("toll", 1)
An diesem Beispiel wird die Stärke des Verfahrens deutlich: Die Map-Funktion musste nichts über die anderen Sätze wissen (isolierte Abarbeitung), und die Reduce-Funktion musste nur einfache Listen addieren. Die komplexe Logik der Verteilung und Gruppierung lag vollständig beim Framework.
(2.2.) CAP und Eventually Consistent
(2.2.1.) Konsistenzmodell relationaler Datenbanken
Ein wesentlicher Treiber für die Entwicklung von NoSQL war die Unzufriedenheit vieler Web 2.0-Unternehmen mit der Skalierbarkeit klassischer relationaler Datenbanken (RDBMS). Während diese Systeme historisch durch vertikale Skalierung (Aufrüsten einzelner Server) gut funktionierten, stießen sie bei den im Webzeitalter notwendigen Anforderungen an horizontale Skalierung (Verteilung auf viele Server) an ihre Grenzen. Versuche, relationale Datenbanken über Cluster hinweg zu verteilen, führten oft zu inakzeptablen Reaktionszeiten oder erforderten komplexe Workarounds.
Die Ursache für diese Limitierung liegt tief in der Architektur relationaler Systeme begründet, die streng dem ACID-Prinzip (Atomicity, Consistency, Isolation, Durability) folgen. Dabei hat die Konsistenz (Consistency) traditionell die oberste Priorität. Dies ist historisch bedingt, da RDBMS ursprünglich für geschäftskritische Prozesse wie Finanztransaktionen entwickelt wurden, bei denen Dateninkonsistenzen (z.B. bei Banküberweisungen) unter keinen Umständen toleriert werden durften.
Mit dem exponentiellen Datenwachstum des Internets wurde dieses Dogma jedoch zum Flaschenhals. Es zeigte sich, dass die strikte Einhaltung sofortiger Konsistenz in einer verteilten Umgebung physikalisch kaum mit den Anforderungen an hohe Verfügbarkeit und niedrige Latenzzeiten vereinbar ist. Die Erkenntnis, dass das starre Festhalten an ACID für Web-Szenarien hinderlich ist, ebnete den Weg für neue Architekturansätze jenseits der relationalen Welt.
(2.2.2) Das CAP-Theorem
In der akademischen Diskussion waren die Grenzen klassischer Datenbanken in verteilten Systemen schon länger bekannt, doch erst im Jahr 2000 brach Eric Brewer (University of California) mit einem Vortrag auf dem ACM-Symposium den Damm zwischen Theorie und Praxis. Er formulierte das CAP-Theorem, welches heute als zentraler Schlüssel zum Verständnis der NoSQL-Bewegung gilt.
Es liefert die theoretische Erklärung dafür, warum das alte Denkmuster (strikte Konsistenz) in der modernen Web-Welt nicht mehr funktioniert. Die Kernaussage ist, dass ein verteiltes System von den drei wünschenswerten Eigenschaften Consistency, Availability und Partition Tolerance maximal zwei gleichzeitig garantieren kann.
Die drei Größen werden dabei wie folgt definiert und tiefergehend betrachtet:
-
Consistency (Konsistenz): Nach Abschluss einer Transaktion befinden sich alle Knoten auf demselben Stand (D1). Jeder Lesezugriff liefert – egal auf welchem Knoten er erfolgt – sofort den aktuellsten Wert zurück. Das Problem in der Praxis: Um dies in einem großen Cluster zu gewährleisten, muss der geänderte Wert erst an alle Replikas verteilt werden, bevor er wieder gelesen werden darf. Bei vielen Knoten und hoher Last führt dies zu erheblichen Wartezeiten (Latenz), bis die Synchronisation abgeschlossen ist.
-
Availability (Verfügbarkeit): Das System antwortet auf jede Anfrage (Lesen/Schreiben) erfolgreich und innerhalb einer akzeptablen Zeit. Die geschäftliche Relevanz: Was „akzeptabel“ ist, definiert der Anwendungsfall. Für E-Commerce-Riesen wie Amazon hat dies direkten Einfluss auf den Umsatz: Schon minimale technische Verzögerungen im Bestellprozess lassen die Verkaufszahlen messbar sinken. Ein verfügbares System muss daher auch unter hoher Last performant bleiben.
-
Partition Tolerance (Ausfalltoleranz): Das System arbeitet weiter, auch wenn Nachrichten zwischen den Knoten verloren gehen oder Verbindungen (Netzwerk-Partitionen) ausfallen. Die Realität: In großen Rechenzentren sind solche Ausfälle keine Ausnahme, sondern an der Tagesordnung. Für Webunternehmen ist es essenziell, dass ein Verbindungsausfall zwischen zwei Servern nicht das gesamte System lahmlegt.
Das Szenario nach Gilbert und Lynch
Um die Unvereinbarkeit dieser drei Ziele zu beweisen, nutzen Gilbert und Lynch ein vereinfachtes Szenario, das die Konsequenz des Theorems greifbar macht:
Stellen wir uns einen Webshop mit zwei Datenbank-Knoten vor. Knoten K1 ist für Schreiboperationen zuständig, Knoten K2 liefert Leseoperationen für Kunden. Beide halten eine Replik der Daten (Ausgangszustand D0).
-
Der Normalfall: Ein Administrator fügt einen neuen Artikel hinzu (Schreibzugriff auf K1). Der Zustand ändert sich von D0 zu D1. K1 sendet eine Synchronisations-Nachricht an K2. Ein Kunde liest kurz darauf von K2 und sieht den neuen Artikel (D1).
-
Der Fehlerfall (Partition): Die Netzwerkverbindung zwischen K1 und K2 fällt aus. K1 kann die Nachricht über den neuen Artikel (D1) nicht mehr an K2 senden.
Entscheidet man sich für Konsistenz (CP), muss K1 die Schreiboperation blockieren oder ablehnen, da er nicht garantieren kann, dass K2 aktualisiert wird. Die Verfügbarkeit des Systems bricht ein. Entscheidet man sich für Verfügbarkeit (AP), führt K1 die Änderung durch (D1). K2 bleibt jedoch auf dem alten Stand (D0) und liefert dem Kunden veraltete Daten (der Artikel fehlt). Das System bleibt online, ist aber inkonsistent. Da in großen verteilten Netzwerken Ausfälle (Partitionen) physikalisch unvermeidbar sind (P ist also gesetzt), muss der Architekt wählen:
Klassische RDBMS (relationale Datenbanken) sind traditionell auf Konsistenz getrimmt. Im Fehlerfall blockieren sie Transaktionen, um Datenintegrität zu wahren – auf Kosten der Verfügbarkeit. Für Webunternehmen, deren Profit von ständiger Erreichbarkeit abhängt, ist dieses Risiko oft nicht tragbar. Daher wählen NoSQL-Systeme meist den Pfad der Verfügbarkeit (AP). Sie nehmen in Kauf, dass Daten kurzzeitig asynchron sein können (Verzicht auf strikte Konsistenz), stellen aber sicher, dass der Kunde immer eine Antwort erhält.
(2.2.3) Alternatives Konsistenzmodell: BASE
Als Antwort auf die Einschränkungen des CAP-Theorems und als direkter Gegenentwurf zum strikten ACID-Modell relationaler Datenbanken etablierte sich in der NoSQL-Welt das BASE-Prinzip. Das Akronym steht für Basically Available, Soft State und Eventually Consistent. Während ACID einen pessimistischen Ansatz verfolgt und Konsistenz über alles stellt, wählt BASE einen optimistischen Ansatz: Die Verfügbarkeit des Systems hat oberste Priorität. Man akzeptiert dabei, dass der Systemzustand „weich“ (Soft State) ist, sich also auch ohne direkte Eingabe ändern kann, während die Daten im Hintergrund synchronisiert werden.
Zentrales Konzept ist hierbei die Eventual Consistency. Anstatt sofortige Konsistenz nach jeder Transaktion zu erzwingen, wird ein Zeitfenster der Inkonsistenz toleriert. Das System garantiert lediglich, dass die Daten „irgendwann“ auf allen Knoten denselben Stand erreichen. In der Praxis ist dies kein Schwarz-Weiß-Szenario, sondern ein Spektrum, auf dem sich Datenbanken zwischen ACID und BASE positionieren.
Da Entwickler sich bei NoSQL nicht mehr blind auf strikte Konsistenz verlassen können, definierte Amazon-CTO Werner Vogels spezifische Konsistenz-Garantien zur Orientierung:
- Causal Consistency: Stellt sicher, dass logisch aufeinanderfolgende Operationen (A löst B aus) auch in dieser Reihenfolge auf allen Knoten sichtbar werden.
- Read-your-write Consistency: Garantiert, dass ein Prozess seine eigenen Schreibvorgänge sofort lesen kann (keine veralteten Daten für den Verursacher).
- Session Consistency: Bindet die „Read-your-write“-Garantie an eine aktive Benutzersitzung.
- Monotonic Read/Write: Verhindert, dass ein Prozess nach dem Lesen neuerer Daten plötzlich wieder ältere Versionen sieht oder dass seine Schreibvorgänge durcheinandergeraten.
Der Einsatz von NoSQL erfordert somit ein grundlegendes Umdenken: Entwickler müssen aktiv entscheiden, ob für ihren Anwendungsfall die gelockerte Konsistenz ausreicht oder ob zusätzliche Mechanismen auf Anwendungsebene nötig sind.
(2.3) REST
REpresentational State Transfer (REST) gilt als das fundamentale Architekturmuster, das die Skalierung des World Wide Web von einem einzigen Server am CERN im Jahr 1990 zu einem globalen Netzwerk ermöglichte. Wichtig ist hierbei: REST ist keine Software-Bibliothek, die man einfach einbindet, sondern ein Entwurfsmuster, das die Struktur eines Systems von Grund auf bestimmt.
Da NoSQL-Datenbanken ebenfalls auf massive Skalierbarkeit („Web-Scale“) ausgelegt sind, setzen viele moderne Systeme wie CouchDB, Riak oder Neo4j auf REST-Schnittstellen. Obwohl REST theoretisch protokollunabhängig ist, wird es in der Praxis fast immer über HTTP realisiert, da dieses Protokoll die beste Unterstützung bietet.
(2.3.1) Definition: Web-scale
Der oft genutzte Begriff Web-scale beschreibt die Fähigkeit einer Plattform, auf ein globales Niveau mit Millionen von Nutzern zu wachsen. Der Fokus liegt dabei nicht auf der Leistungssteigerung einzelner Server (vertikale Skalierung), sondern auf der horizontalen Verteilung der Last auf tausende Maschinen.
Ein echtes Web-Scale-System zeichnet sich dadurch aus, dass es linear mit der Anzahl der hinzugefügten Server skaliert. Es muss zudem robust genug sein, um in einer heterogenen Umgebung zu funktionieren, also mit unterschiedlicher Hardware und variablen, oft unzuverlässigen Netzwerkverbindungen zurechtzukommen, wie sie im Internet Standard sind.
(2.3.2) Bausteine der REST-Architektur
Ein REST-System basiert auf drei fundamentalen Säulen: Ressourcen, Operationen und Links. Ein entscheidendes Prinzip ist dabei die Statuslosigkeit: Jeder Request ist in sich geschlossen und völlig unabhängig von vorherigen Anfragen. Dies ermöglicht erst die problemlose Verteilung einer Applikation auf viele unabhängige Server, da keine aufwendige Synchronisation von Sitzungsdaten (Session State) zwischen den Knoten notwendig ist.
Das Protokoll HTTP wird in diesem Kontext oft unterschätzt. Es dient nicht nur dem simplen Abruf von Webseiten, sondern fungiert als universelles Framework, um Verben (Methoden) auf Substantive (Ressourcen) anzuwenden. Die Kommunikation erfolgt über Requests und Responses, die jeweils aus einem Header (für Metadaten) und optional einem Body (für die Repräsentation der Ressource) bestehen. Standardisierte Metadatenfelder im Header steuern dabei essenzielle Funktionen für skalierbare Systeme, wie etwa das Caching oder bedingte Abfragen zur Lastreduzierung.
(2.3.2.1) Ressourcen
Im REST-Konzept ist eine Ressource ein adressierbarer Endpunkt, der über einen Uniform Resource Identifier (URI) eindeutig identifiziert wird. Dabei ist strikt zwischen der abstrakten Ressource (dem Informationsgehalt) und ihrer Repräsentation zu unterscheiden. Ein und dasselbe Datenobjekt kann dem Client in verschiedenen Formaten (z.B. als JSON, XML oder HTML) angeboten werden.
Am Beispiel von CouchDB wird dieses Prinzip konsequent umgesetzt: Hier ist alles eine Ressource, vom eigentlichen JSON-Dokument über Indizes (die via Map/Reduce erstellt werden) bis hin zu Konfigurationsdaten.
(2.3.2.2) Operationen
Die Interaktion mit Ressourcen erfolgt über standardisierte HTTP-Verben (Methoden), deren Semantik universell bekannt ist. Dies ermöglicht Mechanismen wie Caching, die für die Skalierung essenziell sind. Die wichtigsten Methoden sind GET, HEAD, PUT, POST und DELETE.
Diese Operationen werden anhand zweier Eigenschaften klassifiziert, die für die Robustheit verteilter Systeme entscheidend sind:
-
Sicher (Safe): Operationen, die keine Seiteneffekte auf dem Server haben (z.B. reine Lesezugriffe). Der Aufrufer trägt keine Verantwortung für Zustandsänderungen.
-
Idempotent: Operationen, die beliebig oft wiederholt werden können, ohne den Serverzustand anders zu verändern als bei der einmaligen Ausführung. Dies ist fundamental für Fehlertoleranz: Wenn eine Antwort im Netzwerk verloren geht, kann der Client den Befehl einfach erneut senden, ohne Dateninkonsistenzen zu riskieren.
(2.3.2.3) HTTP-Methoden im Detail
Die korrekte Verwendung der HTTP-Verben ist essenziell für die Stabilität und Skalierbarkeit eines REST-Systems. Man unterscheidet hierbei zwischen reinen Lese-Operationen und schreibenden Zugriffen.
GET und HEAD (Die „sicheren“ Methoden)
Diese Methoden sind sowohl sicher (keine Seiteneffekte) als auch idempotent.
GET: Fordert die Repräsentation einer Ressource an.HEAD: Fordert nur die Metadaten (Header) an, ohne den Body zu übertragen.
Da Web-Crawler und Proxies sich auf die Sicherheit dieser Methoden verlassen, ist es folgenschwer, zustandsändernde Aktionen (wie Löschvorgänge) über GET-Parameter abzubilden (z.B. ?action=delete). Dies kann zu unbeabsichtigtem Datenverlust führen.
PUT (Erstellen & Aktualisieren)
PUT dient dem Schreiben von Ressourcen und ist idempotent. Der Client sendet die neuen Daten an den Server.
CouchDB-Implementierung: Um Idempotenz und Konsistenz zu sichern, nutzt CouchDB Revisionsnummern (Optimistic Locking). Ein Update gelingt nur, wenn der Client die aktuelle Revisionsnummer mitsendet.
- Erster Aufruf: Revision stimmt überein -> Update erfolgreich, neue Revision wird erzeugt.
- Zweiter Aufruf (Wiederholung): Revision veraltet -> Fehler, aber der Serverzustand bleibt unverändert (Idempotenz gewahrt).
DELETE (Löschen)
Dient dem Entfernen einer Ressource. Auch DELETE ist idempotent: Der Endzustand des Servers (Ressource ist weg) muss nach einem Aufruf identisch sein mit dem Zustand nach zehn Aufrufen.
Der erste Aufruf löscht die Ressource. Folgende Aufrufe mögen zwar Fehlermeldungen liefern (z.B. 404 Not Found), ändern aber nichts mehr am Zustand „gelöscht“.
POST
Die Methode POST nimmt eine Sonderstellung im HTTP-Protokoll ein. Sie steht dem „sicheren“ GET gegenüber, bietet jedoch keinerlei Garantien bezüglich Sicherheit oder Idempotenz. Historisch relevant ist POST vor allem deshalb, weil es (neben GET) die einzige Methode ist, die nativ von HTML-Formularen unterstützt wird. Moderne Frameworks umgehen diese Limitierung oft durch versteckte Formularfelder (_method), um PUT oder DELETE zu simulieren, was architektonisch jedoch nur eine Notlösung darstellt.
Während PUT eine konkrete Repräsentation an eine bekannte Adresse sendet (um sie dort zu speichern), dient POST dazu, Daten an eine Ressource zur Verarbeitung zu senden. Das Ergebnis ist offen: Es kann eine neue Ressource entstehen, eine bestehende geändert werden oder auch gar keine Zustandsänderung erfolgen (z.B. bei komplexen Suchanfragen, deren Parameter zu lang für eine GET-URL wären).
Die Konvention (Best Practice) `
In der REST-Architektur hat sich eine klare Arbeitsteilung etabliert, die auch von CouchDB so umgesetzt wird:
PUT: Wird verwendet, wenn der Client die Adresse (URI/ID) der Ressource bestimmt (z.B. „Speichere dies unter ID 123“).POST: Wird verwendet, wenn der Server die Adresse bestimmen soll. EinPOSTan die Datenbank-URL erzeugt ein neues Dokument, wobei der Server die ID (und damit die URI) generiert.
Links
Der dritte und letzte Baustein eines REST-Systems sind die Links. Sie sind das Element, das isolierte Ressourcen erst zu einem echten Netzwerk (dem Web) verknüpft. Wichtig ist die Unterscheidung der Ebenen: Während Ressourcen und Operationen durch das Protokoll (HTTP) definiert sind, gehören Links zur Repräsentation (dem Inhalt) der Daten.
Eigenschaften von REST-Links:
- Lose Kopplung: Links sind keine festen Verbindungen, sondern Zeiger. Ein REST-System ist darauf ausgelegt, dass ein Link auch ins Leere führen kann (toter Link). Diese Fehlertoleranz ermöglicht erst die Skalierung über verschiedene Server und Organisationen hinweg.
- Semantik: Im Gegensatz zu einfachen HTML-Hyperlinks können REST-Links Metadaten enthalten (z.B. Relationen wie „next“, „alternate“ oder „edit“). Dies ermöglicht dem Client, maschinell zu entscheiden, welchem Verweis er für den nächsten Prozessschritt folgen soll.
Hier ist die Zusammenfassung des Abschnitts 2.7.3, der die Theorie anhand eines konkreten Beispiels veranschaulicht.
(2.3.2.4.) Entwurf von REST-Applikationen (Praxisbeispiel)
Am Beispiel einer Publishing-Plattform für Cocktailrezepte wird demonstriert, wie die theoretischen Bausteine (Ressourcen, Verben, Links) in der Praxis zusammenspielen. Der Workflow verdeutlicht insbesondere das Konzept der Steuerung durch Hypermedia (oft als HATEOAS bezeichnet = Hypermedia as the Engine of Application State).
1. Erstellen einer Ressource (POST)
Um einen neuen Cocktail anzulegen, sendet der Client eine JSON-Repräsentation an die API-URL (z.B. /api/).
- Da die ID noch nicht existiert, wird POST verwendet.
- Bei Erfolg antwortet der Server mit Status 201 Created.
- Wichtig: Der Server teilt dem Client im Location-Header die URL der neu geschaffenen Ressource mit (z.B.
.../cocktails/1).
2. Abrufen und Navigation durch Links (GET)
Fragt der Client die neue Ressource ab, erhält er nicht nur die Nutzdaten (Zutaten, Name), sondern auch einen Links-Block. Dieser Block diktiert dem Client, welche Aktionen im aktuellen Zustand möglich sind.
Beispielantwort (gekürzt):
{
"id": "1",
"name": "Ipanema",
"links": {
"linktypes/publish": "http://example.com/publish/1",
"linktypes/edit": "http://example.com/cocktails/1",
"linktypes/delete": "http://example.com/cocktails/1"
}
}
3. Der Vorteil der Entkopplung
Durch die Nutzung dieser vom Server gelieferten Links (statt URLs im Client-Code fest zu verdrahten) entsteht eine lose Kopplung:
- Der Client muss keine Logik zur URL-Generierung besitzen.
- Der Server kann seine interne Struktur ändern (z.B. den Publishing-Dienst auf einen anderen Server
publish.example.comverschieben), ohne dass die Clients ein Update benötigen. Der Server ändert einfach den Link in der Antwort, und der Client folgt ihm blind.
4. Zustandsübergänge (State Transitions)
REST-Applikationen sind dynamisch. Wenn der Nutzer den Cocktail veröffentlicht (durch einen POST auf den publish-Link), ändert sich der Zustand der Ressource auf dem Server.
Bei der nächsten Abfrage (GET) sieht die Antwort anders aus:
- Die Links für
editundpublishsind verschwunden (da ein veröffentlichter Artikel nicht mehr bearbeitet werden darf). - Ein neuer Link
ratingsist aufgetaucht (da nun Bewertungen möglich sind).
Der Client navigiert also wie durch ein Zustandsdiagramm, wobei der Server ihm bei jedem Schritt sagt, wohin er als Nächstes gehen kann.
Hier ist die Zusammenfassung des Abschnitts 2.7.4 für deine Dokumentation im gewohnten Stil:
(2.3.3) Skalierung von REST-Systemen
Die enorme Skalierbarkeit von REST-Architekturen beruht auf zwei ineinandergreifenden Strategien: der Verteilung der Last auf viele Schultern und der Minimierung der Last durch Vermeidung unnötiger Datenübertragungen.
Lastverteilung durch Statuslosigkeit
Das Fundament der horizontalen Skalierung ist die Statelessness. Da jeder Request alle notwendigen Informationen enthält und nicht von vorherigen Anfragen oder einem server-seitigen Sitzungsspeicher (Session State) abhängt, kann jede Anfrage von einem beliebigen Server im Cluster beantwortet werden. Dies ermöglicht das einfache Hinzufügen weiterer Server ohne komplexe Synchronisationslogik.
Caching (Zwischenspeicherung)
HTTP bietet eine ausgefeilte Infrastruktur für Caches, die an verschiedenen Stellen (Browser, Proxy, Server) greifen. Ziel ist es, Antworten so nah wie möglich am Client zu bedienen, um die Netzwerklast zu reduzieren.
- Identifikation: Anfragen werden durch URI, Methode und Metadaten eindeutig identifiziert.
- Steuerung: Server steuern über Header wie
Cache-Control,ExpiresoderVarypräzise, wie lange Daten als aktuell gelten. - Methoden-Semantik: Caches nutzen die standardisierte Bedeutung der HTTP-Verben (z.B. ist GET cachebar, POST meist nicht).
Bedingte Anfragen (Conditional Requests)
Um Bandbreite zu sparen, unterstützt HTTP Mechanismen, mit denen Clients prüfen können, ob ihre lokal vorliegenden Daten noch aktuell sind, bevor der Server die vollen Nutzdaten sendet. Antwortet der Server mit 304 Not Modified, wird kein Body übertragen. Es gibt zwei Verfahren:
- Zeitbasiert: Der Server sendet ein
Last-Modified-Datum. Der Client fragt später mit dem HeaderIf-Modified-Since: „Sende mir die Daten nur, wenn sie sich seit Zeitpunkt X geändert haben.“ - Inhaltsbasiert (ETags): Der Server sendet einen Hash-Wert (Entity Tag / ETag), der den Zustand der Ressource repräsentiert. Der Client fragt mit
If-None-Match: „Sende mir die Daten nur, wenn der Hash nicht mehr mit meinem übereinstimmt.“
Fazit
Die Kombination aus Statuslosigkeit, Caching und bedingten Anfragen ermöglicht eine Skalierung von einer einzelnen Maschine bis hin zu weltweiten Content Delivery Networks (CDNs). Werden diese Prinzipien jedoch verletzt (z.B. durch Sessions oder falsche Methodenwahl), bricht die Skalierbarkeit zusammen.